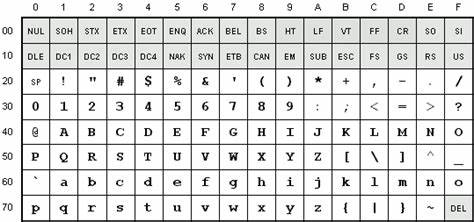
Los caracteres de control forman una parte fundamental y a menudo desconocida de los sistemas de codificación de caracteres, como ASCII y Unicode. Aunque invisibles para muchos usuarios, estos símbolos cumplen funciones esenciales para la gestión de textos, dispositivos y protocolos de comunicación en la informática. Su origen se remonta a la década de 1960, cuando la estandarización de los códigos para representar texto empezó a consolidarse, y desde entonces han evolucionado para adaptarse a las necesidades de la tecnología moderna, manteniendo intacta su importancia en numerosos ámbitos. El conjunto ASCII, establecido en los años 60, introdujo un grupo concreto de códigos reservados para fines de control, distintos de los caracteres alfanuméricos y símbolos gráficos que todos reconocemos. Estos caracteres, ubicados originalmente en las posiciones 0 a 31 del código, y complementados por otros adicionales, fueron diseñados para manejar aspectos como el formato del texto, el control de dispositivos y la transmisión de datos a través de diferentes medios.
En esencia, no representan letras o números visibles sino instrucciones que afectan la forma en que el texto es procesado o presentado. Los caracteres de control del conjunto C0 de ASCII incluyen elementos clásicos cuya utilidad trasciende décadas. Ejemplos destacados son el carácter NUL (Null), que en programas sirve para señalar el final de una cadena de texto; CR (Carriage Return) y LF (Line Feed), que controlan la posición del cursor y el salto de línea en pantallas y documentos; el BEL (Bell), que produce una alerta sonora; y ESC (Escape), crucial para iniciar secuencias que modifican el comportamiento del terminal o impresora. Aunque muchos fueron concebidos para trabajar con tecnologías obsoletas como tarjetas perforadas y máquinas de escribir electrónicas, continúan presentes en los sistemas operativos, lenguajes de programación y protocolos actuales. Además del conjunto básico C0 existe el conjunto C1, que se ubica en el rango 128 a 159 en sistemas de 8 bits.
Este grupo fue creado posteriormente para ampliar las posibilidades de control de dispositivos, como monitores y impresoras, incorporando comandos para tabulación avanzada, control de áreas específicas en formularios y soporte para funciones de presentación más elaboradas. Aunque en la práctica su uso es menos frecuente que los caracteres C0, son parte integral de estándares como ISO/IEC 6429 y ECMA-48, y son soportados por Unicode. Más allá de C0 y C1, existen caracteres especiales derivados de estándares como ISO 8859, entre los que destacan el espacio sin ruptura (NBSP) y el guion blando (SHY). Estos tienen funciones singulares dentro del manejo de texto, como impedir que un espacio provoque un salto de línea o permitir divisiones condicionales de palabras, respectivamente. Estas características son ampliamente utilizadas en el diseño web y la edición de documentos electrónicos, y forman parte esencial de la tipografía digital.
Unicode representa la evolución natural y la unificación moderna de los sistemas de codificación, incorporando todos los caracteres de ASCII y sus extensiones, incluidos los de control. El estándar Unicode no sólo respeta las funciones históricas de estos caracteres sino que las integra dentro de su esquema, con definiciones claras y reglas específicas para su uso, como los roles en algoritmos de ruptura de línea y dirección del texto. Esto permite que los mismos principios básicos sigan siendo relevantes en plataformas actuales, desde sistemas operativos hasta aplicaciones móviles y navegadores web. A pesar de la importancia histórica, el uso práctico de muchos caracteres de control ha cambiado con el avance tecnológico. En entornos modernos, la mayoría de las tareas de control y formato se efectúan mediante protocolos, lenguajes de marcado como XML o HTML, y herramientas específicas de edición y gestión.
Sin embargo, ciertos caracteres siguen siendo imprescindibles para la compatibilidad con sistemas legacy, protocolos de comunicación y ciertas interfaces de usuario. Por ejemplo, los códigos NUL y DEL son fundamentales en la programación y manipulación de cadenas, mientras que ESC y sus secuencias asociadas mantienen su rol en terminales y sistemas basados en líneas de comandos. La relación entre las teclas del teclado y los caracteres de control también es un aspecto interesante. Muchas combinaciones con la tecla Ctrl generan códigos de control, lo que ha llevado a que algunos de ellos sean adoptados como atajos para funciones del sistema o aplicaciones. Sin embargo, la función original del carácter no siempre coincide con la acción ejecutada por la combinación del teclado.
Por ejemplo, Ctrl+C tradicionalmente representa ETX (End of Text), y se utiliza para cancelar procesos, mientras que Ctrl+I corresponde a HT (Horizontal Tab), que mueve el cursor a la siguiente posición tabular. La complejidad y diversidad de los caracteres de control reflejan las necesidades y evolución de la informática desde sus inicios. Desde la gestión física de medios como las cintas y perforaciones, pasando por la manipulación de impresoras y terminales, hasta las soluciones digitales y de red actuales, estos códigos han servido como herramientas versátiles para el control y la comunicación. Aunque el avance hacia interfaces gráficas y sistemas modernos ha disminuido su visibilidad y uso directo, su presencia en los estándares es una garantía de interoperabilidad y soporte para una amplia gama de tecnologías. Conocer y comprender los caracteres de control es esencial para desarrolladores, ingenieros de sistemas y profesionales del software que trabajan en áreas relacionadas con la manipulación de texto, diseño de protocolos o manejo de dispositivos.
Además, los estudiantes y entusiastas de la informática pueden beneficiarse al entender estas bases técnicas que, aunque puedan parecer arcaicas, siguen influyendo en el funcionamiento de los sistemas actuales. En resumen, los caracteres de control en ASCII y Unicode representan un legado tecnológico de gran valor, que combina historia, funcionalidad y adaptabilidad. Su estudio revela no sólo la manera en que se diseñaron los primeros sistemas de codificación, sino también cómo esos principios sobreviven y se mantienen útiles en la era digital contemporánea. Conocer sus particularidades y usos contribuye a una comprensión más profunda de cómo los sistemas procesan la información y cómo interactúan con los dispositivos y usuarios, asegurando la continuidad y evolución en el campo de las tecnologías de la información.