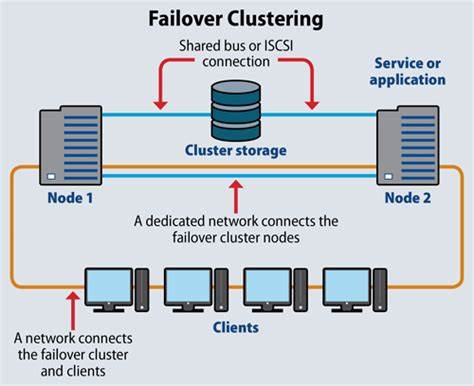
Las bases de datos con arquitectura de líder único son una solución ampliamente adoptada en sistemas distribuidos para manejar operaciones de escritura y garantizar la consistencia de los datos. Este modelo se caracteriza porque un solo nodo, conocido como líder, es responsable de procesar todas las solicitudes de escritura, mientras que los demás nodos, llamados seguidores o réplicas, se encargan de replicar la información y atender las solicitudes de lectura, distribuyendo así la carga y optimizando el rendimiento. Sin embargo, en entornos empresariales y de producción, la resiliencia es crucial, y aquí es donde entra en juego el concepto de failover o conmutación por error, un mecanismo clave para mantener la disponibilidad y minimizar pérdidas en caso de fallos del sistema. Para entender cómo funciona el failover en bases de datos con un líder único, es importante primero definir qué implica este tipo de sistema. En esencia, un sistema de líder único centraliza las escrituras para evitar conflictos y asegurar la coherencia de los datos.
El líder maneja las solicitudes de escritura de los clientes, las registra en un log local o secuencia de operaciones, y posteriormente propaga estos cambios a los seguidores que, aunque no pueden aceptar escrituras directas, mantienen una copia lo más actualizada posible de la base de datos para balancear las consultas de lectura. Todo esto contribuye a la eficiencia y la integridad, pero también crea un punto único de vulnerabilidad: si el líder falla, la capacidad de aceptar nuevas escrituras se ve interrumpida. El failover, en este contexto, es el proceso mediante el cual el sistema detecta la falla de un nodo, ya sea líder o seguidor, y reconfigura automáticamente la arquitectura para que la operación continúe con el menor impacto posible. En las bases de datos de líder único, se manejan dos escenarios principales: el fallo de un nodo seguidor y el fallo del líder. Cuando un nodo seguidor falla, la situación es menos crítica porque los seguidores no procesan escrituras.
La detección de este tipo de fallo suele ocurrir gracias a mecanismos de monitoreo como los latidos (heartbeats) o intentos fallidos de conexión. Al detectar que un seguidor no responde, el sistema lo elimina temporal o permanentemente de la lista de nodos activos. Mientras esto sucede, las solicitudes de lectura que se dirigían al nodo caído se redirigen a otros seguidores o, en último caso, al líder, lo que puede hacer que la carga aumente momentáneamente para estos nodos. El proceso de recuperación incluye la creación o arranque de un nuevo nodo seguidor que debe sincronizarse con el estado actual del líder. Este sincronismo suele empezar con la copia de una instantánea reciente (snapshot) del líder, seguida de la aplicación de los cambios derivados del log desde la fecha de ese snapshot para alcanzar la consistencia necesaria.
Una vez sincronizado, el nuevo seguidor comienza a recibir actualizaciones en tiempo real y retoma su función normal dentro del clúster. Esta estrategia garantiza que la operación de escritura en el sistema no se vea afectada por la pérdida de un seguidor, incrementando la disponibilidad y la capacidad de lectura distribuida. No obstante, el sistema se vuelve temporalmente más vulnerable a futuros fallos de seguidores debido a la disminución de réplicas. El fallo del líder es, sin duda, un reto mayor. Puesto que es el único nodo que acepta escrituras, su indisponibilidad implica una paralización en la aceptación de nuevas actualizaciones hasta que se establezca un nuevo líder.
La detección del fallo del líder también se realiza mediante mecanismos de monitoreo, que pueden ser implementados internamente en la base de datos o apoyados por servicios externos de coordinación. Estos chequeos generalmente verifican la recepción constante de señales de vida del líder y si estas fallan durante un lapso determinado, se declara la falla. Una vez detectado el fallo, el sistema debe llevar a cabo un proceso de elección de un nuevo líder. Este proceso, conocido como elección de líder o líder election, se basa en identificar cuál seguidor tiene los datos más actualizados para minimizar la pérdida de información. Para tales fines, se utilizan algoritmos y protocolos de consenso como Raft o Paxos, que garantizan que todos los nodos lleguen a un acuerdo sobre quién debe asumir el liderazgo, asegurando a la vez que no existan líderes duplicados que puedan generar inconsistencias.
Tras la elección del nuevo líder, es fundamental que todos los clientes y seguidores reconozcan el cambio. Los clientes deben redirigir sus peticiones de escritura al nuevo líder, mientras que los seguidores deben desconectarse de la instancia antigua y comenzar a replicar desde la nueva fuente. Esto implica una reconfiguración dinámica y eficiente que es crítica para restablecer la normalidad en las operaciones lo más rápido posible. Existen dos tipos principales de failover de líder: el failover planificado o controlado y el failover de emergencia. En un failover planificado, que suele ocurrir durante tareas de mantenimiento o actualizaciones programadas, el líder actual finaliza todas las operaciones pendientes, verifica que uno de los seguidores esté completamente sincronizado, y luego transfiere el liderazgo de forma ordenada.
Esta transición controlada normalmente evita la pérdida de datos y permite una transición suave. Por otro lado, el failover de emergencia se produce ante fallos inesperados como caídas del nodo, problemas en la red o cortes de energía. En estos casos, el sistema debe reaccionar de manera automática y rápida para seleccionar un nuevo líder y restablecer la funcionalidad, aunque el proceso puede implicar riesgos temporales de pérdida de datos o mal funcionamiento si no se implementa correctamente. La latencia de la red es un factor que influye en la elección del nuevo líder, especialmente en sistemas distribuidos geográficamente. Aunque la prioridad máxima es seleccionar el nodo con los datos más actualizados para preservar la integridad, la proximidad del nodo al resto de clientes o a la infraestructura puede afectar el rendimiento y la experiencia del usuario.
Un líder ubicado cerca de la mayoría de los clientes reduce la latencia de las operaciones, aunque esto es considerado secundario frente a la coherencia y disponibilidad de datos. Para maximizar la efectividad del failover, las arquitecturas modernas suelen combinar mecanismos automáticos con soporte humano para monitoreo y resolución de problemas complejos. Así mismo, las pruebas frecuentes de failover y simulacros de desastre son prácticas recomendables para garantizar que los planes se ejecuten adecuadamente ante situaciones reales. En resumen, el manejo del failover en bases de datos con arquitectura de líder único es un componente esencial para asegurar la disponibilidad, la integridad y la continuidad en sistemas distribuidos. Mientras que la falla de seguidores afecta principalmente la capacidad de lectura y puede ser gestionada sin grandes impactos, la falla del líder requiere un proceso coordinado y ágil para evitar interrupciones en las operaciones de escritura.
Protocolos de consenso robustos y estrategias de transferencia planificadas son cruciales para minimizar riesgos durante este proceso. Finalmente, el balance entre la consistencia de los datos, la resiliencia de la arquitectura y la latencia de la red es lo que determina la calidad y confiabilidad del sistema en producción.