En la era digital actual, los asistentes de voz como Siri, Google Assistant o Alexa se han convertido en herramientas imprescindibles para facilitar nuestras tareas cotidianas. Sin embargo, la mayoría de estos asistentes dependen de la nube para procesar la información, lo que plantea serias preocupaciones acerca de la privacidad y la seguridad de los datos. Imagine un asistente de voz que funcione completamente de manera local, en su dispositivo, sin enviar ninguna información a servidores externos. Un Siri privado y eficiente que respete totalmente su intimidad. La tendencia de construir asistentes de voz que operen íntegramente en el dispositivo está ganando impulso y cambia paradigmas en la tecnología moderna.
Esta revolución no solo responde a la necesidad urgente de proteger datos personales, sino que también ofrece beneficios en velocidad, disponibilidad y autonomía. El creciente interés por la informática en el borde o edge computing ha impulsado la aparición de soluciones que apuestan por el procesamiento local. A diferencia de enviar comandos o consultas a la nube, un asistente de voz localizada interpreta y ejecuta las órdenes al instante, sin depender de una conexión a internet. Esta evolución no es casual, ya que las tecnologías de Inteligencia Artificial y los modelos de lenguaje han avanzado lo suficiente como para ejecutarse en dispositivos personales, desde computadoras portátiles hasta móviles y Raspberry Pi, sin sacrificar rendimiento o precisión. Uno de los retos fundamentales para desarrollar un asistente de voz de este tipo es la capacidad de reconocimiento y comprensión del lenguaje natural, así como la habilidad para interactuar directamente con las funciones del sistema operativo o aplicaciones instaladas en el dispositivo.
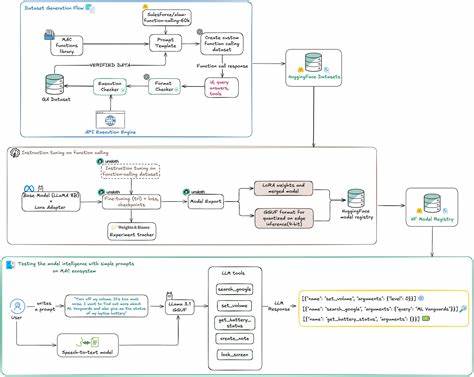
Para lograrlo, es necesario combinar distintas tecnologías: modelos de conversión de voz a texto, modelos de lenguaje ajustados o finamente adaptados para interpretar comandos específicos, y un mecanismo de conexión que traduzca esta comprensión en acciones concretas, como bloquear la pantalla, realizar búsquedas o gestionar el volumen. El proceso comienza con la creación o selección de un modelo de reconocimiento de voz eficiente y ligero, capaz de funcionar en condiciones de bajo rendimiento computacional y sin conexión a internet. Whisper, un modelo desarrollado para reconocimiento de voz, es una opción popular para la transcripción local debido a su balance entre precisión y libre acceso. Una vez transcrita la voz a texto, este contenido se dirige a un modelo de lenguaje, que debe estar adaptado para entender instrucciones concretas y mapearlas a funciones programadas. Aquí es donde entra en juego el ajuste fino de modelos base como LLaMA, utilizando técnicas como LoRA que permiten optimizar el modelo para tareas específicas sin necesitar amplios recursos.
La generación de un conjunto de datos personalizado es vital. No es suficiente con usar datos genéricos o recopilados de fuentes públicas; el sistema debe entrenarse con ejemplos precisos y diversificados que reflejen los comandos reales que se pretenden ejecutar. Esto incluye variaciones en la formulación de órdenes, errores comunes, vacilaciones y diferentes patrones de habla. La creación de este dataset con estructuras claras y verificaciones automáticas garantiza que el modelo internalice un comportamiento determinista, confiable y reproducible, lo que resulta crítico para aplicaciones privadas y sensibles. El ajuste y evaluación del modelo no terminan con el entrenamiento.
Es importante implementar un riguroso esquema de pruebas que simulen escenarios variados en los que los usuarios interactúan con el asistente. Validar la capacidad del sistema para manejar comandos ambiguos, micrófonos con ruido, posibles conflictos entre funciones e incluso distintas entonaciones o acentos es fundamental para asegurar una experiencia fluida y sin errores. De esta manera, se mitigan riesgos de fallos silenciosos que puedan frustrar o poner en riesgo al usuario. Una vez el modelo está preparado, su integración con el sistema operativo o aplicaciones locales debe ser segura y eficiente. El objetivo es que, al identificar un comando válido, el sistema ejecute la función correspondiente sin requerir pasos intermedios ni transmitir información a servidores remotos.
Esta arquitectura totalmente local es la clave para respetar la privacidad del usuario al máximo y evitar vulnerabilidades derivadas de conexiones externas. Un aspecto imprescindible en el desarrollo de estos asistentes locales es la aplicación de principios de MLOps (Machine Learning Operations). Aunque el concepto de MLOps suele asociarse a infraestructuras en la nube, sus prácticas son igualmente esenciales cuando el sistema reside enteramente en el dispositivo. El control de versiones de modelos, registro de cambios, validaciones automáticas, y la capacidad de rastrear el origen de datos y resultados son necesarias para mantener un producto confiable y sostenible a lo largo del tiempo. Esto es aún más crítico cuando no se cuenta con la retroalimentación continua que ofrecen los entornos en la nube.
Los usos potenciales de un Siri local son vastos y variados. En ambientes empresariales donde la confidencialidad es clave, como sectores legales, salud o finanzas, proporcionar a los empleados asistentes de voz privados puede incrementar la productividad sin comprometer la seguridad. En dispositivos personales, evita que los usuarios tengan que sacrificar su privacidad para acceder a funciones inteligentes. Además, la eliminación de latencias que surgen de la dependencia en la nube mejora notablemente la experiencia, haciendo que el asistente sea más reactivo y siempre disponible, incluso en entornos sin conexión. Algunos proyectos recientes demuestran que construir un asistente de voz local no es ciencia ficción sino una realidad alcanzable.
Herramientas opensource y frameworks provistos por comunidades activas permiten a desarrolladores diseñar agentes personalizados, capaces de funcionar de manera autónoma en laptops, móviles y dispositivos integrados. La combinación de modelos compactos, técnicas de fine-tuning eficientes y arquitecturas ligadas directamente a funciones programables facilita la creación de aplicaciones que además de respetar la privacidad, son sostenibles y escalables. Sin embargo, a pesar de contar con la tecnología adecuada, el éxito depende de una cuidadosa planificación y ejecución. Ya sea para hobbyistas, startups o grandes empresas, es imprescindible invertir tiempo en construir datasets de calidad, realizar pruebas exhaustivas y mantener disciplina en el control de versiones. Sólo así se evita el problema común de modelos que funcionan bajo condiciones muy específicas y fallan ante cualquier patrón no anticipado.
El futuro apunta hacia asistentes de voz que no sólo entienden y responden, sino que también actúan como guardianes de la privacidad digital. Esta transición hacia asistentes verdaderamente locales redefine cómo interactuamos con la tecnología y establece un nuevo estándar de confianza para usuarios y empresas. Construir tu propio Siri local es una puerta al control absoluto, rapidez y seguridad, alejándonos de la dependencia en gigantes tecnológicos y sus infraestructuras remotas. En conclusión, los avances en modelos de lenguaje, reconocimiento de voz y MLOps han creado el entorno propicio para que cualquier desarrollador o equipo interesado pueda crear un asistente de voz efectivo que funcione íntegramente en el dispositivo, sin tocar la nube. Esta solución supera las limitaciones actuales en privacidad, coste y latencia, allanando el camino para una nueva generación de asistentes digitales que son, de verdad, personales.
La construcción de estos asistentes exige compromiso, rigor y las herramientas adecuadas, pero la recompensa es un sistema que funciona en tiempo real, respeta la privacidad y se integra profundamente con el usuario y su entorno tecnológico. El futuro ya está aquí y es local.