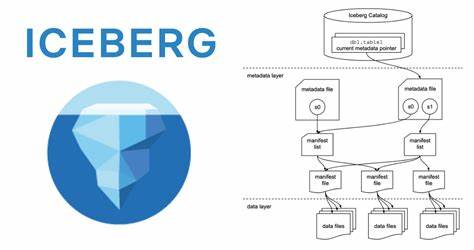
En el mundo actual, donde la gestión y análisis de grandes volúmenes de datos son fundamentales para la toma de decisiones estratégicas, las tecnologías que potencian la eficiencia y rapidez de consulta son altamente valoradas. Apache Iceberg se ha consolidado como un formato de tabla open source que optimiza el manejo de datos en sistemas tipo lakehouse, permitiendo organizar grandes cantidades de información mediante un esquema consistente y transaccional. Sin embargo, la velocidad con la que se ejecutan las consultas y el procesamiento del data lake siguen siendo un desafío constante, especialmente cuando se manejan cargas analíticas complejas. Aquí es donde Vortex aparece como un elemento disruptivo, logrando acelerar las consultas de Apache Iceberg hasta cuatro veces en ciertos escenarios analíticos mediante una integración inteligente y un rendimiento nativo sobresaliente. Vortex fue diseñado con la visión de satisfacer futuras demandas de procesamiento de datos, pero también rinde excepcionalmente en cargas de trabajo tradicionales OLAP.
Su eficiencia no solo se refleja en pruebas sintéticas, sino en benchmarks reales con conjuntos de datos estandarizados como TPC-H, donde supera consistentemente a formatos ampliamente establecidos como Parquet. La clave de su éxito radica en su estructura interna y en la forma en que gestiona la compresión y el acceso a los datos, haciendo uso de tecnologías nativas optimizadas escritas en Rust, lo que aporta ventajas tanto en consumo de recursos como en latencias de lectura y deserialización. En paralelo, Apache Iceberg ha evolucionado para convertirse en el estándar en formatos de tablas de data lakes y lakehouses, adoptado por gigantes tecnológicos y proveedores de servicios cloud. Su arquitectura escalable y extensible permite operar con múltiples formatos de archivo y brinda funcionalidades avanzadas como viajes en el tiempo, gestión de snapshots y transacciones ACID. Sin embargo, su modelo tradicional presenta ciertos retos para admitir nuevos formatos de archivo de alto rendimiento como Vortex, debido a la implementación profundamente integrada de soportes nativos de lectura en lenguajes específicos como Java, lo cual limita la incorporación directa de soluciones externas.
Para superar esta barrera, el equipo desarrollador de Vortex implementó una integración innovadora que expone sus funcionalidades a través de Java Native Interface (JNI), permitiendo que el procesamiento nativo en Rust pueda ser invocado directamente desde Java, el lenguaje en el que Apache Iceberg está desarrollado. Este puente nativo ha sido cuidadosamente diseñado para manejar la complejidad de interoperar entre lenguajes, al mismo tiempo que garantiza seguridad en el manejo de memoria y evita pérdidas o fugas. La solución se centra en exponer una interfaz sencilla que gestiona la apertura de archivos Vortex, la creación de operaciones de escaneo con filtros y proyecciones optimizados y la exportación eficiente de resultados en formato Arrow, compatible con frameworks de procesamiento como Apache Spark. Otro aspecto fundamental para lograr altas velocidades fue la implementación del concepto de “row-splittability” o división por filas, un mecanismo que responde a la estructura interna particular de Vortex, diferente a formatos como Parquet que se dividen por rangos de bytes. Con esta innovación, Iceberg puede planificar tareas distribuidas más equilibradamente en Spark, generando mayor paralelismo y evitando cuellos de botella provocados por grandes volúmenes secuenciales en un solo hilo de procesamiento.
Esta técnica habilita un escalado más eficiente de la carga de trabajo, reduciendo significativamente los tiempos de respuestas en consultas complejas. La colaboración con Microsoft Gray Systems Lab fue clave para validar el potencial de esta integración mediante exhaustivas pruebas en entornos reales sobre Azure. Con un conjunto de datos TPC-H a escala 100, los resultados mostraron una mejora general del 30% en tiempos de ejecución sobre toda la suite de consultas, con picos que alcanzaron mejoras de hasta cuatro veces en escenarios específicos como joins pesados. Esto se traduce en un impacto directo para empresas y usuarios que requieren análisis en tiempo real o procesamiento de datos masivos, donde cada segundo cuenta para la obtención de insights y la competitividad. Además del beneficio en rendimiento, Vortex ofrece ventajas relacionadas con el diseño y evolución del formato de archivo.
A diferencia de otros formatos tradicionales que enfrentan dificultades para incorporar nuevas características de manera gradual, Vortex fue concebido para ser evolutivo. Esto facilita la incorporación de funcionalidades como índices de página o filtros de Bloom de forma coherente y simultánea en todos los sistemas que lo utilicen, evitando fragmentaciones y problemas de compatibilidad que han persistido durante años en ecosistemas como Parquet. El hecho de que Vortex esté implementado en Rust también aporta un salto cualitativo en el control de consumo de memoria y optimizaciones a nivel bajo para vectores y descompresión, lo que se traduce en menos asignaciones innecesarias, mejor vectorización automática y tiempos de CPU más bajos. Estas características nativas son difíciles de replicar de manera eficiente en Java, y la solución JNI permite aprovechar lo mejor de ambos mundos: rendimiento nativo con integración en ecosistemas Java y Spark. Asimismo, el trabajo en la interfaz de tabla de Iceberg continúa, con contribuciones que buscan estandarizar una API de formatos de archivos más modular y flexible para facilitar la incorporación de otras tecnologías más allá de Parquet, ORC y Avro.
La resolución de este desafío técnico permitirá extender la compatibilidad de Iceberg de manera más natural con Vortex y otros formatos emergentes, democratizando el acceso a innovaciones que aceleran análisis y reducen costos. El planteamiento de Vortex frente a los retos actuales también abre caminos para mejorar características complementarias clave para entornos de producción, tales como el soporte para vectores de eliminación (deletion vectors) que optimizan operaciones de merge-on-read y facilitan el manejo eficiente de registros eliminados sin impactos significativos en rendimiento. Esta funcionalidad, en proceso de integración, consolidará a Vortex como una opción robusta para cargas de trabajo con alta frecuencia de actualizaciones y cambios. Finalmente, la integración contempla cuestiones vitales como el cifrado a nivel Iceberg, garantizando que los datos procesados bajo esta arquitectura mantengan la confidencialidad y seguridad exigida por normativas y mejores prácticas del sector. Esto es especialmente relevante para adopciones en industrias reguladas o que manejan información sensible.