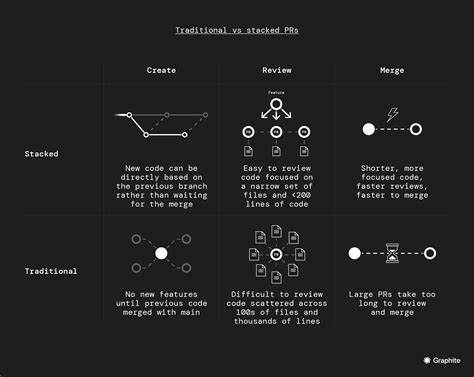
En el mundo actual, la gestión eficiente y rápida de grandes volúmenes de datos es fundamental para las empresas que operan en la nube. A medida que las infraestructuras crecen y la complejidad de los entornos se intensifica, contar con una base de datos que combine velocidad, escalabilidad y facilidad de uso es un factor decisivo para el éxito. CloudQuery, una plataforma de gobernanza en la nube, comparte una travesía de seis meses con ClickHouse, una base de datos analítica de alto rendimiento, revelando insights valiosos que servirán tanto a desarrolladores como a ingenieros de datos interesados en optimizar sus ecosistemas digitales. Cuando CloudQuery inició su aventura, el objetivo era sencillo: extraer datos de configuración de la nube de sus usuarios y permitir enviar esta información a cualquier base de datos existente, desde Postgres hasta MongoDB o Neo4J. Sin embargo, esta flexibilidad resultó ser un arma de doble filo, ya que mantener múltiples integraciones complicaba el desarrollo de nuevas funcionalidades como dashboards en tiempo real y reportes interactivos.
La necesidad evidente era contar con un backend robusto y confiable, capaz de manejar grandes volúmenes de datos con un ingresado continuo y consultas ad-hoc rápidas sin intervención manual en la gestión de índices. En este contexto, tras diversas pruebas comparativas y evaluación de opciones, ClickHouse emergió como la solución más adecuada gracias a su rendimiento escalable y su costo eficiente. Uno de los principales desafíos que enfrentaba CloudQuery era el volumen masivo de datos que debían ser procesados: billones de filas sincronizadas cada mes, miles de cuentas en múltiples proveedores de nube y millones de datos en tiempo real a consulta constante. ClickHouse demostró poder absorber miles de millones de filas por segundo, con un crecimiento lineal al agregar nodos al clúster y una latencia en las consultas mucho menor en comparación con alternativas como BigQuery o Snowflake. Un aprendizaje fundamental fue la gestión de las operaciones JOIN, que inicialmente representaron un cuello de botella en términos de rendimiento y uso de memoria.
Al enfrentarse a consultas complejas entre tablas grandes, el sistema experimentaba bloqueos y terminaciones abruptas debido a la sobreatribución de memoria. Para sortear estas limitaciones, CloudQuery optó por reordenar los JOINs siempre colocando las tablas más pequeñas en la derecha, así como por implementar diccionarios internos de ClickHouse para optimizar estos procesos, reduciendo radicalmente el consumo de memoria y mejorando la velocidad de las consultas. No obstante, esta solución implicó un mayor nivel de complejidad operativa, sobre todo en la sincronización y mantenimiento de las credenciales necesarias para las consultas que alimentan los diccionarios. Este esfuerzo adicional, aunque significativo, permitió que ciertas consultas que antes fallaban se ejecutaran en tiempos casi instantáneos, haciendo viable el uso de ClickHouse para análisis en tiempo real. Otro aspecto crucial que impactó el rendimiento fue la definición de las claves de ordenamiento en las tablas.
CloudQuery descubrió que elegir un ordenamiento subóptimo, como priorizar únicamente la marca temporal en una tabla extensa, causaba escaneos innecesarios de la base dados, afectando gravemente la velocidad de las consultas más habituales enfocadas en clientes o recursos específicos. Ajustar esta clave para priorizar identificadores relevantes y características de las consultas comunes redujo el volumen de datos escaneados hasta en 25 veces, multiplicando por ello la eficiencia y respuesta del sistema. Este insight subraya la importancia de analizar minuciosamente los patrones de acceso a los datos antes de diseñar la estructura física de las tablas, ya que una decisión precoz aquí puede traducirse en mejoras dramáticas en el rendimiento y la escalabilidad a largo plazo. En cuanto a materialización de vistas, ClickHouse ofrecía una solución tentadora con sus Materialized Views (MV) para mantener datos agregados en tiempo real. Sin embargo, en la práctica, CloudQuery encontró que estas vistas ejecutaban de manera asincrónica y carecían de mecanismos claros para detectar fallos o refrescar datos históricos, lo que complicaba la consistencia y la evolución del esquema.
En respuesta a esta limitación, CloudQuery optó por utilizar tablas de snapshot y procesos explícitos de refresco, lo que les devolvió el control integral sobre la consistencia y la gestión de versiones de los datos, especialmente durante migraciones o actualizaciones importantes. Esta estrategia, aunque más laboriosa, aportó la certeza y trazabilidad necesarias para mantener la confianza de los usuarios. Más allá de las aplicaciones analíticas convencionales, ClickHouse demostró ser efectivamente útil para el manejo de logging y observabilidad. CloudQuery integró logs de la aplicación y del sistema directamente en ClickHouse, aprovechando su capacidad para gestionar datos semi-estructurados con alta compresión y consultas rápidas. De igual modo, se exploraron integraciones con OpenTelemetry para almacenar trazas de sincronización sin muestreo, permitiendo consultas detalladas y rápidas sobre eventos de alto volumen y alta cardinalidad.
Esta versatilidad permitió a CloudQuery consolidar múltiples cargas de trabajo en una sola plataforma, simplificando la arquitectura y reduciendo costos operativos, en comparación con sistemas especializados para métricas, trazas o logs. La experiencia práctica confirmó las ventajas económicas y de mantenimiento de ClickHouse como un backend unificado para funciones diversas. Si CloudQuery pudiera repetir este viaje desde el inicio, ofrecería algunos consejos valiosos. Por ejemplo, la implementación temprana de buffers o colas antes de insertar datos en ClickHouse habría ayudado a evitar problemas de consistencia temporal donde datos viejos y nuevos coexistían de manera confusa durante las sincronizaciones. También destacan la importancia de planificar las claves de ordenamiento con antelación, ya que una vez creada una tabla, modificar esta configuración requiere reconstruirla por completo, lo que en producción puede generar interrupciones significativas.
La comparación entre ClickHouse gestionado en la nube y su versión autoalojada también trajo lecciones prácticas. Aunque la opción gestionada facilitó el lanzamiento rápido y la evaluación del producto, la migración posterior poco planificada hacia un entorno propio presentó desafíos operativos, de configuración y compatibilidad que generaron costos de tiempo y recursos inesperados. Mirando hacia el futuro, CloudQuery observa con interés varias mejoras prometedoras en ClickHouse. La incorporación de un soporte nativo y avanzado para JSON facilitará el manejo de datos complejos y semi-estructurados, un punto crítico para muchos casos de uso modernos. Además, la evolución de capacidades de búsqueda de texto completo se espera que expanda el ámbito de uso de ClickHouse, potencialmente reemplazando servicios externos para búsquedas más sofisticadas.
En suma, la experiencia de seis meses con ClickHouse en CloudQuery demuestra que aunque ninguna herramienta es perfecta, la elección acertada y la adaptación cuidadosa a sus particularidades pueden transformar radicalmente la forma en que se manejan grandes volúmenes de datos. Esta aventura ha llevado a un crecimiento en la pericia técnica del equipo y a la creación de soluciones más eficientes, posicionando a CloudQuery para afrontar con éxito los retos crecientes de la gestión de infraestructuras en la nube. Para quienes consideren incorporar ClickHouse en sus entornos, el relato de CloudQuery es un llamado a comprender profundamente los patrones de uso y a implementar con atención las configuraciones clave que determinan el rendimiento final. Con este conocimiento, ClickHouse puede ser no solo una base de datos analítica más, sino la columna vertebral de una plataforma integral de gobernanza, análisis y observabilidad en la nube.