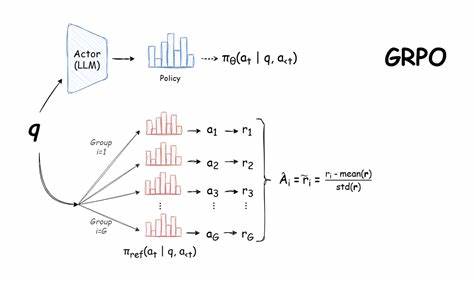
En la era actual de la inteligencia artificial, la capacidad de los modelos de lenguaje para realizar tareas complejas va mucho más allá de responder consultas o generar texto creativo. Una aplicación particularmente interesante es la planificación y la gestión de agendas, una tarea que tradicionalmente se ha resuelto con algoritmos deterministas y métodos heurísticos. Sin embargo, en un fascinante experimento que rompe con lo convencional, se ha entrenado un modelo de lenguaje utilizando GRPO (Group Relative Policy Optimization) para aprender cómo programar eventos a partir de listas con prioridades, aportando una nueva dimensión al uso de modelos de inteligencia artificial en la organización personal y profesional. El proyecto nace del deseo de explorar el aprendizaje por refuerzo aplicado a modelos de lenguaje, un enfoque que no utiliza ejemplos explícitos para enseñar al modelo, sino que lo entrena mediante la recompensa de comportamientos deseables en respuesta a entradas (prompts). Esta metodología permite que el modelo aprenda a razonar y tomar decisiones basándose en la maximización de funciones de recompensa, dando lugar a un comportamiento emergente que supera las limitaciones del aprendizaje supervisado tradicional.
En este experimento específico, el objetivo era sencillo pero desafiante: dado un conjunto de eventos con horarios y prioridades, el modelo debía construir una agenda que optimizara la selección de eventos en función de la duración total ponderada por la prioridad de cada evento. Para simplificar, los eventos con prioridad recibían un peso de 2 mientras que los normales, un peso de 1. La idea era que la agenda final maximizara la suma ponderada del tiempo ocupado por los eventos seleccionados sin superponerse. Esta tarea, que podría parecer trivial para algoritmos clásicos, presenta un interesante reto para un modelo de lenguaje, ya que implica razonamiento temporal, comprensión de prioridades y la gestión de restricciones para evitar conflictos entre eventos. El entrenamiento con GRPO permitió que el modelo mejorara progresivamente en esta habilidad, aprendiendo a balancear las prioridades y a estructurar horarios más eficientes.
Durante el proceso de entrenamiento, se construyó un conjunto de datos especialmente diseñado para la generación de ejemplos variados de eventos y prioridades, proporcionando al modelo una amplia gama de situaciones en las que practicar la toma de decisiones. En lugar de mostrarle cómo resolver cada ejemplo, se dejó que el modelo explorara posibles soluciones y recibiera retroalimentación basada en las recompensas obtenidas al seguir las reglas establecidas. Los resultados fueron sorprendentes, especialmente tomando en cuenta que el modelo utilizado contaba con 7 mil millones de parámetros. Este modelo no solo logró superar en precisión y calidad a su versión base sino que incluso superó a modelos más grandes con 14 mil millones de parámetros en las pruebas finales. Además, fue capaz de adoptar el formato requerido para la salida y respetar la mayoría de las reglas definidas en el enunciado del problema.
Sin embargo, el experimento también reveló áreas en las que el modelo aún tiene margen de mejora. Por ejemplo, el control del solapamiento entre eventos sigue siendo un desafío, lo que indica que el diseño de la función de recompensa para esta limitación podría ser optimizado. Este hallazgo abre puertas para futuras investigaciones acerca de cómo ajustar las métricas y señales de recompensa para que los modelos aprendan a respetar todas las restricciones de manera más rigurosa. Más allá del aspecto técnico, esta experiencia representa un paso significativo en la aplicación del aprendizaje por refuerzo en modelos de lenguaje para tareas prácticas distintas a la generación textual tradicional. El hecho de que un modelo pueda aprender a organizar eventos y comprender la importancia relativa de diferentes tareas sin ejemplos concretos es un avance notable hacia sistemas más autónomos y adaptativos.
A nivel organizacional, el repositorio que documenta el experimento está cuidadosamente dividido en partes que facilitan la comprensión y reutilización del trabajo. Incluye herramientas para la generación de datos, notebooks de entrenamiento, plantillas de prompts y scripts para evaluación y pruebas del modelo. Todo esto constituye un recurso valioso para aquellos interesados en adentrarse en el mundo del aprendizaje por refuerzo aplicado a modelos de lenguaje. Además, la experiencia compartida invita a reflexionar sobre el valor de enseñar a un modelo habilidades que, aunque podrían resolverse con precisión mediante programación determinista, aportan perspectiva y retos únicos que enriquecen el campo de la inteligencia artificial. En un momento donde la experimentación con técnicas como GRPO es tendencia en distintas áreas, esta aplicación demuestra cómo combinar creatividad técnica y motivación investigadora puede conducir a resultados relevantes y sorprendentes.
La decisión de abordar la planificación de eventos como escenario de prueba también refleja un interés por conectar la investigación avanzada con problemas cotidianos y útiles, reforzando la idea de que las herramientas de IA están en constante evolución para mejorar nuestra productividad y calidad de vida. En resumen, el experimento que entrenó un modelo de lenguaje con GRPO para programar eventos no solo representa un avance tecnológico sino que también contribuye a expandir los límites de lo que los modelos de lenguaje pueden lograr mediante el aprendizaje por refuerzo. Sus resultados y hallazgos aportan conocimientos que pueden inspirar nuevas aplicaciones y estrategias para aprovechar el poder de la inteligencia artificial en la resolución de problemas reales. Aprender a enseñarle a las máquinas no solo el significado del lenguaje, sino la forma de razonar sobre el tiempo, las prioridades y las restricciones, es sin duda un paso adelante fascinante y prometedor.