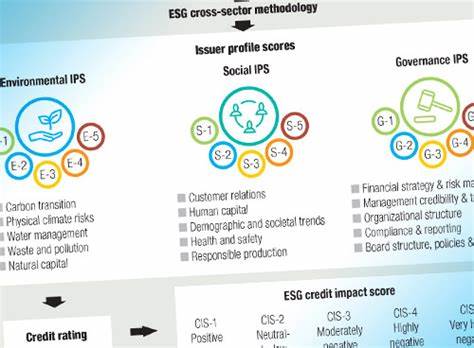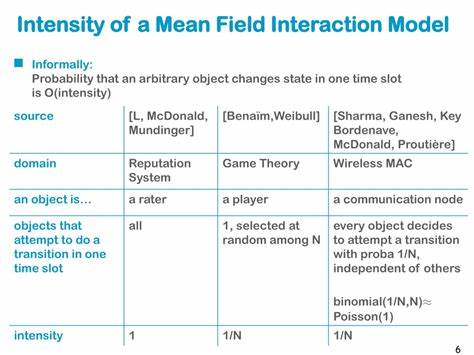
En el mundo actual, la tecnología avanza a pasos agigantados y con ella, la inteligencia artificial (IA) y el aprendizaje automático continúan expandiendo sus fronteras. En particular, el aprendizaje en sistemas multiagente ha cobrado gran relevancia debido a su aplicación en áreas que requieren la cooperación y competencia de múltiples agentes, desde vehículos autónomos y robótica colaborativa hasta simulaciones militares y videojuegos en línea. Sin embargo, al abordar escenarios con un número muy elevado de agentes, surgen retos significativos que las técnicas tradicionales de aprendizaje automático tienen dificultades para superar. Aquí es donde las interacciones de campo medio y los enfoques basados en la teoría del campo medio han demostrado ser una herramienta fundamental para modelar y aprender comportamientos competitivos en equipos a gran escala. La colaboración y competencia entre grupos numerosos de agentes genera dinámicas complejas.
Tradicionalmente, los algoritmos de aprendizaje multiagente como MADDPG (Multi-Agent Deep Deterministic Policy Gradient) y MAAC (Multi-Agent Actor-Critic) han probado ser efectivos en contextos donde el número de agentes se mantiene en cantidades manejables. Sin embargo, a medida que el número de agentes crece exponencialmente, estos métodos enfrentan problemas de escalabilidad, incremento exponencial de la complejidad computacional y dificultades para captar las interacciones entre tantas entidades. Para contrarrestar estas limitaciones, la teoría de campo medio propone un enfoque innovador. Se basa en la idea de que, cuando la cantidad de agentes es extremadamente alta, el comportamiento agregado de la población puede aproximarse por un efecto promedio, denominado 'campo medio'. En lugar de modelar cada interacción individuo a individuo, se estudia cómo un agente interactúa con esta representación promedio del resto.
Esta aproximación no solo reduce la complejidad computacional, sino que también permite capturar el comportamiento colectivo de manera eficiente, facilitando el aprendizaje en escenarios competitivos entre equipos numerosos. En este contexto surge la innovación del algoritmo denominado Mean-Field Multi-Agent Proximal Policy Optimization (MF-MAPPO), que introduce técnicas de optimización proximal de políticas adaptadas a dominios de campo medio. Este algoritmo ha sido desarrollado para enfrentar específicamente juegos multijugador de suma cero entre dos equipos - una situación común en escenarios ofensivos y defensivos como batallas simuladas a gran escala. La combinación entre la efectividad del aprendizaje por refuerzo y la aproximación de campo medio permite que MF-MAPPO escale a cientos o incluso miles de agentes por equipo. El uso de MF-MAPPO en situaciones complejas, por ejemplo en simulaciones militares realistas, revela su gran potencial.
En estas aplicaciones, la estrategia y coordinación entre agentes es crucial para el éxito del equipo, y la competencia feroz entre ambos lados ejemplifica la dinámica típica donde una estrategia adaptativa y óptima puede marcar la diferencia. Mediante experimentación numérica, se ha comprobado que la aproximación de campo medio mantiene consistencia y mejora el rendimiento incluso cuando se aumenta la cantidad de agentes, superando a métodos tradicionales que no logran gestionar la complejidad ni la escalabilidad. Este avance también tiene amplias implicaciones más allá del terreno militar simulado. En sectores como el tráfico de vehículos autónomos, la economía basada en agentes o la gestión de recursos distribuidos, comprender y aprender comportamientos colectivos competitivos facilita la creación de sistemas más robustos, adaptativos y eficientes. La capacidad de modelar interacciones en entornos densamente poblados abre las puertas a soluciones innovadoras para problemas antes considerados intratables.
A nivel técnico, el MF-MAPPO extiende la popular técnica de Proximal Policy Optimization (PPO), reconocida por su estabilidad y eficacia en aprendizaje por refuerzo. La clave está en incorporar el marco de campo medio para que la política de cada agente se ajuste no solo basado en su propia experiencia directa, sino también en la distribución promedio de acciones y estados de la población. Esto crea un entorno de aprendizaje en el que la política es, a su vez, dependiente y adaptativa al contexto colectivo, capturando interacciones estratégicas esenciales en contextos competitivos. Además, al utilizar esta modalidad, se reducen de manera significativa las dificultades derivadas del curse of dimensionality, problema recurrente en aprendizaje multiagente cuando el espacio de estado y acción crece con cada agente adicional. La reducción del problema al estudio del efecto de campo medio posibilita la definición de políticas óptimas en espacios más manejables, lo que contribuye a la mejora en tiempos de entrenamiento y ejecución.