En la era de la globalización y la digitalización rápida, las empresas enfrentan desafíos constantes para administrar datos que están dispersos geográficamente sin sacrificar la velocidad ni la coherencia. Tradicionalmente, manejar bases de datos que abarcan múltiples regiones ha implicado complejas configuraciones de particionado, arquitecturas heterogéneas y problemas de latencia que pueden entorpecer la experiencia del usuario y la performance general de las aplicaciones. CockroachDB, una base de datos SQL distribuida de última generación, ha abordado estos retos con una característica revolucionaria llamada REGIONAL BY ROW, introducida en su versión de 2024. Esta innovación redefine el concepto de homogeneización de datos a nivel de fila, simplificando dramáticamente el despliegue y gestión en entornos multi-regionales al mismo tiempo que garantiza la integridad y rapidez en las consultas. La motivación principal detrás del desarrollo de REGIONAL BY ROW se basa en la necesidad creciente de acercar los datos a los usuarios finales.
Para una empresa global con usuarios en países como Estados Unidos, Reino Unido o Australia, colocar un único centro de datos en una región implica que ciertos usuarios sufrirán latencias considerables, afectando negativamente la experiencia y eficiencia operativa. Una solución intuitiva es dividir los datos según la región geográfica de los usuarios, asegurando que cada fila de datos resida en el nodo más cercano al usuario correspondiente. Sin embargo, implementar esta panorámica a escala, con altos requisitos de consistencia y transacciones seguras, ha sido un desafío complicado con bases de datos tradicionales. Antes de la introducción de REGIONAL BY ROW, CockroachDB ya contaba con mecanismos para lograr almacenamiento regional de filas mediante configuraciones manuales de particionamiento y separación de tablas, pero estos demandaban una considerable complejidad en el desarrollo y administración. Los desarrolladores debían agregar explícitamente una columna para la región, modificar claves primarias y adaptar las consultas para contemplar múltiples ubicaciones geográficas.
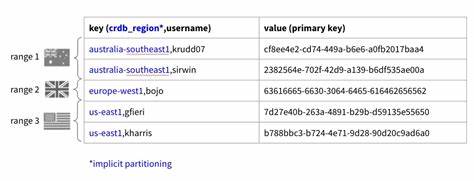
Además, esta aproximación implicaba riesgos en la garantía de unicidad global y generación de latencias por transacciones cruzadas entre regiones. El núcleo de REGIONAL BY ROW radica en una sintaxis SQL simple y declarativa que facilita la creación de tablas donde cada fila está domicilada en una región específica, sin alterar la experiencia de uso de lenguaje SQL estándar. Al incluir LOCALITY REGIONAL BY ROW dentro de la creación de la tabla, CabroachDB genera de manera implícita una columna interna llamada crdb_region que rastrea y define la región local de cada fila. Esta columna es invisible para las consultas habituales, lo que permite realizar operaciones de inserción y selección sin preocuparse por especificar el lugar físico donde está guardada la información. Este enfoque trae múltiples beneficios a nivel de desarrollo y operación.
Por ejemplo, al insertar un nuevo registro mediante un comando sencillo como INSERT INTO users (username) VALUES ('usuarioX'), el sistema automáticamente asigna la fila a la región óptima según el punto de conexión del usuario. De manera similar, las consultas SELECT funcionan con la magia de la búsqueda optimizada, consultando primero la región local para obtener resultados rápidos y luego, solo si es necesario, realizando un barrido hacia otras regiones en segundo plano, minimizando el retardo y la carga en el sistema. Desde el punto de vista técnico, REGIONAL BY ROW implementa un concepto avanzado llamado particionamiento implícito. A diferencia de la necesidad tradicional de tener las columnas de particionado como prefijo de las claves primarias o índices, esta funcionalidad permite que la columna oculta crdb_region actúe en segundo plano como clave para dividir el almacenamiento, mientras la clave primaria lógica del negocio permanece sencilla y clara para el desarrollador. Esto asegura que la integridad referencial y las restricciones únicas, como claves únicas para usernames, sean garantizadas de manera global, sin sacrificar la organización física de los datos.
Además, la base de datos optimiza automáticamente las consultas frecuentes con un mecanismo denominado Locality Optimized Search, que aprovecha el conocimiento de la unicidad de ciertas columnas para reducir consultas y búsquedas distribuidas innecesarias. Esto resulta en respuestas inmediatas para la mayoría de los casos de uso, especialmente cuando el acceso es realizado desde la misma región donde reside el dato. Desde la perspectiva arquitectónica, internamente CockroachDB traduce operaciones SQL a interacciones con su capa de almacenamiento llave-valor, subdividido en rangos que son repartidos y replicados según las configuraciones regionales. El manejo del crdb_region permite segmentar estos rangos de manera dinámica y automática, facilitando el transporte eficiente, la replicación y la recuperación ante fallos, todo sin intervención manual por parte de los desarrolladores o administradores. CockroachDB ha complementado esta innovación con herramientas de simulación fáciles de utilizar para desarrolladores que deseen probar y validar la funcionalidad de bases de datos multi-regionales con latencias simuladas y despliegues distribuidos.
Esto no solo facilita el aprendizaje sino que acelera la adopción de sistemas globales robustos. Más allá de la evidente mejora en rendimiento y simplicidad, REGIONAL BY ROW representa un paso adelante fundamentado en los principios modernos de bases de datos distribuidas y consistencia fuerte. Permite la coexistencia armoniosa entre los requerimientos regulatorios de residencia de datos, las expectativas crecientes de rapidez de acceso por parte de los usuarios y la eficiencia operativa necesaria para administrar datos a escala global. En conclusión, la introducción de REGIONAL BY ROW en CockroachDB facilita a empresas de cualquier tamaño la implementación de bases de datos distribuidas a nivel global sin las complicaciones antes asociadas a estas arquitecturas. Con un diseño inteligente que esconde la complejidad bajo una sintaxis SQL familiar, provee un equilibrio perfecto entre performance, consistencia y experiencia del desarrollador.
Esta funcionalidad no solo redefine la manera en que concebimos la gestión de datos multi-regionales sino que también impulsa a CockroachDB como una opción favorita para compañías que buscan modernizar sus infraestructuras y garantizar la mejor experiencia a usuarios repartidos alrededor del planeta.








