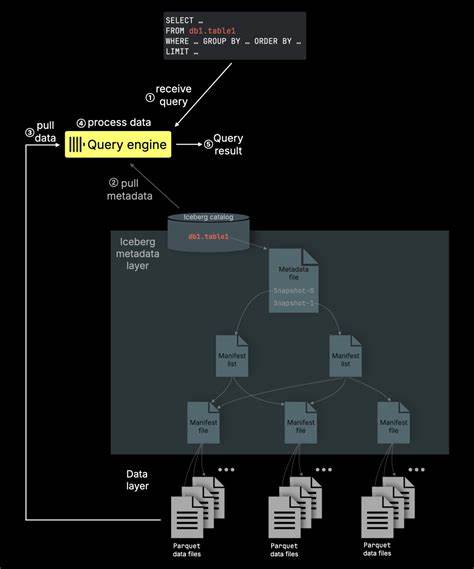
En el mundo actual, donde el análisis de datos voluminosos es crucial para la toma de decisiones rápidas, las arquitecturas Lakehouse han emergido como una solución integral que combina lo mejor de los data lakes y los almacenes de datos tradicionales. ClickHouse, una base de datos de código abierto altamente optimizada para análisis en tiempo real, se ha convertido en una pieza fundamental para potenciar estas arquitecturas, especialmente gracias a su soporte robusto y eficiente para el formato de almacenamiento Parquet. Parquet es un formato columnar en disco ampliamente adoptado en la industria, conocido por su alta eficiencia en almacenamiento y capacidad para acelerar consultas analíticas gracias a su diseño optimizado para la lectura selectiva de columnas y su compresión avanzada. ClickHouse, aunque tiene su formato nativo MergeTree, ha dedicado años a optimizar su motor para consultar directamente archivos Parquet sin la necesidad de ingesta previa. Esta capacidad elimina una capa frecuente de complejidad y latencia en los pipelines de datos, y permite que las organizaciones interactúen directamente con vastos volúmenes de datos guardados en formatos abiertos.
La arquitectura Lakehouse se basa en ofrecer un entorno donde los datos pueden ser almacenados de forma duradera y flexible, generalmente en un almacenamiento distribuido en la nube como S3, y ser consultados eficientemente sin los largos procesos de ingestión y transformación tradicionales. ClickHouse encaja de manera natural en este ecosistema porque es capaz de ejecutar consultas sobre más de 70 formatos de archivo, incluyendo Parquet, JSON, CSV o Arrow, desde múltiples ubicaciones, ya sea en la nube, on-premise o en entornos híbridos. Esto facilita la integración con formatos y fuentes de datos diversas, haciendo del motor una herramienta versátil para casos de uso como analítica en tiempo real, machine learning, inteligencia artificial generativa y observabilidad. Uno de los aspectos más destacables de ClickHouse es su capacidad de paralelización a varios niveles, esencial para manejar eficientemente la lectura y análisis de Parquet a escala. El diseño de Parquet organiza los datos en estructuras llamadas row groups, que son particiones horizontales de las filas, y dentro de ellos, columnas organizadas en chunks y páginas de datos.
El motor de ClickHouse puede distribuir el trabajo leyendo simultáneamente múltiples row groups, tanto dentro de un mismo archivo como entre varios archivos, utilizando múltiples hilos para prefetch, parsing y procesamiento. Esto no solo maximiza la utilización de recursos como los núcleos de CPU, sino que también se adapta dinámicamente a distintos entornos, desde instancias locales hasta clústeres distribuidos de gran escala. La eficiencia en el procesamiento no solo proviene de la paralelización, sino también de la marcada estrategia que ClickHouse aplica para reducir la cantidad de datos irrelevantes que debe leer y procesar. Esto se conoce como reducción de operaciones de entrada/salida (I/O). Gracias a las propiedades propias de Parquet —como la codificación eficiente, compresión de páginas y, fundamentalmente, los metadatos que permiten aplicar filtros a alto nivel— ClickHouse puede saltar grandes fragmentos de datos que no cumplen con los criterios de consulta.
Además, soporta tecnologías como filtros Bloom, estadísticas de mínimos y máximos a nivel de páginas y secciones completas, acelerando la selección de datos necesarios. En la práctica, el rendimiento tangible de esta optimización se refleja en benchmarks realizados con conjuntos de datos representativos de analítica web masiva. En estas pruebas, que comparan la consulta directa sobre Parquet con el rendimiento sobre tablas nativas MergeTree, se observa que aunque el formato native de ClickHouse ofrece la máxima velocidad gracias a su integración profunda y funcionalidades específicas como PREWHERE o lazy materialization, el acceso directo a Parquet se acerca bastante, logrando tiempos de respuesta muy competitivos con un nivel de escalabilidad impresionante. Cabe destacar que ClickHouse no solo ha sabido aprovechar la arquitectura actual de Parquet, sino que también está desarrollando un nuevo lector nativo de Parquet que prescindirá de la capa intermedia que utiliza hoy (Arrow), logrando así una lectura más directa y paralela a nivel de columnas dentro de los row groups. Esta innovación permitirá un mejor aprovechamiento del hardware, especialmente en situaciones con menos cantidad de row groups, mediante la lectura concurrente de columnas individuales y la consolidación inteligente de solicitudes de I/O, mejorando la eficiencia en sistemas con latencia alta.
Este nuevo desarrollo también introducirá soporte ampliado para técnicas de filtrado, incluyendo min/max a nivel de página y filtrado con diccionarios, además de integrarse con mecanismos nativos de reducción de lectura de ClickHouse, avanzando hacia un motor aún más rápido y eficiente. Estos resultados se traducirán en consultas más rápidas, uso más eficiente de memoria y menores costos en infraestructura. Sumado a la capacidad de paralelización interna, ClickHouse puede escalar horizontalmente mediante la ejecución distribuida en clústeres, permitiendo que múltiples nodos participantes procesen los archivos Parquet simultáneamente y de forma coordinada. Esta función es esencial para escenarios en los que la ingesta y consulta de datos ocurren a gran escala y con demandas de baja latencia, tan comunes en las implementaciones modernas de Lakehouse en la nube. La flexibilidad de ClickHouse también se ve reflejada en sus modos de despliegue, que incluyen la operación en nube (ClickHouse Cloud) con integración nativa en grandes proveedores como AWS, Google Cloud o Azure, así como en configuraciones on-premise o híbridas.
La posibilidad de operar en modo Bring Your Own Cloud, donde el servicio se despliega en la cuenta propia del usuario, ofrece control completo y seguridad sin sacrificar la comodidad de un servicio gestionado. Además, sus más de 80 integraciones incorporadas facilitan la conexión con diversas fuentes de datos y almacenamiento, permitiendo a las organizaciones armar canalizaciones robustas y complejas, adaptadas a sus necesidades particulares. El enfoque de “query anything, run anywhere” no solo alienta la interoperabilidad entre sistemas diversos, sino que también anticipa un futuro donde la simplicidad, velocidad y escalabilidad de los análisis serán la norma, no la excepción. Desde un punto de vista del ecosistema y la comunidad, ClickHouse sigue creciendo rápidamente, impulsando innovaciones no solo en el motor de consulta sino en áreas complementarias como machine learning, analítica en tiempo real y observabilidad. Su madurez y optimización para formatos estándar abiertos como Parquet lo posicionan como una opción viable para empresas que requieren soluciones modernas sin el riesgo de quedar encerradas en tecnologías propietarias.
En resumen, ClickHouse representa una base sólida y eficiente para las arquitecturas Lakehouse que buscan conjugar la flexibilidad y economía de los data lakes con las capacidades analíticas rápidas y complejas tradicionales en data warehouses. Su capacidad de consultar archivos Parquet directamente, sin necesidad de ingesta, unido a sus avanzadas técnicas de paralelismo y reducción de I/O, establece un nuevo estándar de rendimiento para el procesamiento analítico a escala. Con el soporte activo y continuo desarrollo de un lector nativo más eficiente para Parquet y su enfoque multisistema y multinube, ClickHouse no solo está preparado para el presente, sino que lidera la evolución hacia un futuro donde los análisis complejos y de alta velocidad son accesibles, escalables y flexibles. Para las organizaciones que desean acelerar su transición hacia una arquitectura Lakehouse moderna, ClickHouse emerge como un aliado estratégico imprescindible.