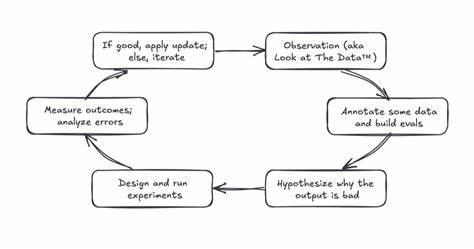
En el mundo actual de la inteligencia artificial, la creación y desarrollo de productos que integran modelos de lenguaje grande (LLM) representa un desafío significativo para equipos de ingeniería y gestión de producto. Existe una idea errónea común que sugiere que simplemente añadir una herramienta automatizada como un LLM actuando como juez para evaluar la calidad del producto puede resolver todos los problemas. Sin embargo, esta perspectiva ignora el verdadero núcleo de mejorar un producto y la importancia vital de contar con un proceso robusto y disciplinado para su desarrollo y monitoreo continuo. Los productos basados en inteligencia artificial no pueden sustentarse únicamente en evaluaciones automatizadas sin un fundamento sólido en prácticas rigurosas de análisis y mejora continua. La evaluación de producto debe entenderse como una práctica dinámica, un ciclo constante de observación, hipótesis, experimentación y análisis que imita los principios del método científico.
No se trata de un trámite estático ni de una solución rápida que pueda comprarse o integrarse sin esfuerzo. El punto de partida del proceso de evaluación está en la observación detallada. Esto implica revisar constantemente los datos disponibles: entradas al sistema, salidas del modelo y la interacción real de los usuarios con la herramienta. Esta mirada profunda permite identificar con claridad dónde el sistema funciona adecuadamente y, más importante aún, donde se presentan fallas o defectos. Reconocer estos modos de falla es fundamental para diseñar intervenciones efectivas y orientadas a resultados concretos.
A partir de la observación, se procede a la anotación de los datos, poniendo especial atención en los casos donde el modelo presenta problemas. Esta tarea consiste en catalogar ejemplos tanto de aciertos como de errores para conformar un conjunto equilibrado y representativo. La idea es trabajar con un dataset que contenga una proporción similar de resultados exitosos y fallidos, cubriendo la variedad y riqueza de los inputs que se reciben. Un conjunto bien anotado se convierte en la base desde la cual se desarrollan evaluaciones a la medida y específicas para los puntos críticos detectados. Paralelamente, es esencial formular hipótesis sobre las causas de los fallos.
El análisis puede revelar, por ejemplo, que un sistema de recuperación de información no está localizando documentos relevantes, o que el LLM encuentra dificultad en seguir instrucciones complejas o contradictorias. Al estudiar el comportamiento del sistema, el origen de los errores y la calidad de los datos recuperados, se pueden priorizar aquellas áreas que requieren intervención inmediata y las hipótesis que deben ser experimentadas para encontrar soluciones. La experimentación es el siguiente paso crucial. Se diseñan pruebas concretas que permitan validar o refutar las hipótesis planteadas. Estas pruebas pueden incluir la reescritura de prompts, la actualización de componentes de recuperación de información o incluso el cambio a otro modelo diferente.
La clave está en definir con claridad los resultados esperados que indicarán el éxito o fracaso de la intervención, garantizando la existencia de una referencia o línea base para comparar el impacto de las modificaciones introducidas. Medir los resultados de cada experimento y realizar un análisis profundo de los errores representa uno de los desafíos más importantes. Requiere cuantificar en términos objetivos si las actualizaciones lograron mejorar el producto. Aspectos como el incremento en la precisión, la disminución de defectos o la mejoría en comparaciones directas son indicadores que deben medirse rigurosamente. Sin esta cuantificación no es posible avanzar en un proceso de mejora continua efectivo y fundamentado.
Cuando un experimento resulta exitoso, la actualización se implementa en el producto, mientras que en caso contrario se vuelve al análisis detallado de errores para afinar las hipótesis y emprender nuevamente el ciclo experimental. Este proceso iterativo construye un motor de mejora basado en datos que incrementa la calidad del producto, reduce los defectos y aumenta la confianza de los usuarios de forma sostenida. Adoptar el método científico al construir productos de inteligencia artificial significa aplicar un enfoque estructurado donde la evaluación y el desarrollo van de la mano. Eval-driven development (EDD) es una práctica que fomenta definir los criterios de éxito desde el inicio y conformar evaluaciones que guían el progreso del producto. Similares a las pruebas en desarrollo tradicional de software, estos evals se diseñan antes de implementar una funcionalidad con el propósito de medir su desempeño preciso y alinearse con los objetivos planteados.
Mediante EDD, cada cambio en el prompt, cada actualización en componentes o cambios de modelo se someten a evaluación rigurosa. Esto permite observar de forma inmediata qué modificaciones impactan positivamente en la fidelidad, la recuperación de información o cualquier otra métrica relevante, y cuáles no. Así se construye un ciclo consistente y fiable donde la intuición da paso a un riguroso feedback basado en datos, incrementando considerablemente las probabilidades de éxito. Sin embargo, es importante destacar que aunque los evaluadores automatizados como un LLM actuando como juez ayudan a escalar la monitorización y el control de calidad, no sustituyen la supervisión humana ni el análisis crítico constante. La automatización facilita el proceso al permitir la revisión de grandes volúmenes de datos, pero si los equipos no mantienen una vigilancia activa y no analizan de manera adecuada tanto la retroalimentación explícita como la implícita, el producto no mejorará significativamente.
Normalmente, la evaluación y monitoreo de productos de IA implica tomar muestras representativas de las salidas del sistema para anotarlas y detectar defectos o logros. Con un volumen suficiente de anotaciones de alta calidad es posible calibrar evaluadores automáticos para alinearlos con el juicio humano. Esto puede incluir medir niveles de recall o precisión o evaluar correlaciones en tareas de comparación de resultados. Cuando esta alineación es adecuada, la automatización se convierte en una poderosa herramienta para mantener una vigilancia continua y escalable. Es indispensable entender que ni los evaluadores automáticos ni los humanos son perfectos.
No obstante, un aumento en la cantidad y calidad de las anotaciones puede mejorar de manera sustancial la precisión y utilidad de los evaluadores automáticos. Mantener esta retroalimentación coordinada requiere una disciplina organizacional que asegure procesos constantes de muestreo, anotación y ajuste de las herramientas de evaluación. La integración de evaluadores automatizados debe verse como un complemento que amplifica y mejora los procesos existentes de anotación y análisis, no como un reemplazo. La clave radica en mantener un ciclo virtuoso donde el conocimiento generado se traduzca en modificaciones concretas que progresivamente optimicen el producto. En definitiva, la construcción de productos potentes con IA no surge del azar o la magia de la tecnología, sino del esfuerzo constante, disciplinado y estructurado.
Es fundamental aplicar el método científico, desarrollar y respetar prácticas de eval-driven development, y mantener un monitoreo exhaustivo que incorpore tanto la evaluación automatizada como la supervisión humana. Invertir en mejorar el proceso detrás de la creación y evolución de productos es mucho más efectivo que simplemente buscar la herramienta automática que aparentemente soluciona todos los problemas. Una visión integral, basada en datos y con iteración constante, es la ruta segura para generar soluciones fiables, robustas y bien valoradas por los usuarios. En un entorno donde las expectativas sobre la inteligencia artificial crecen vertiginosamente, dominar el arte de la evaluación y el desarrollo metódico es esencial para crear productos que realmente marquen la diferencia.








