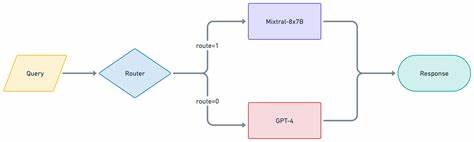
En la era actual de la inteligencia artificial, los modelos de lenguaje grande (LLM) juegan un papel crucial en el desarrollo de sistemas inteligentes y aplicaciones conversacionales. Sin embargo, la gran diversidad de LLMs existentes genera un desafío importante: ¿cómo elegir el mejor modelo para cada tarea específica? Las diferencias en precisión, velocidad y costos asociados plantean un dilema para los desarrolladores e ingenieros. Aquí es donde LLM Router emerge como una solución revolucionaria que permite administrar múltiples LLMs de manera eficiente y escalable. LLM Router es un framework open-source desarrollado por NVIDIA que actúa como un enrutador inteligente de solicitudes, identificando y redirigiendo los prompts conforme al tipo de tarea o complejidad, hacia el modelo de lenguaje más adecuado disponible en la infraestructura. Este router se configura para trabajar con diversas políticas de clasificación y utiliza modelos pre entrenados que interpreta el contenido de los prompts para determinar su destino ideal.
La idea detrás de LLM Router radica en la automatización de las decisiones difíciles sobre qué modelo utilizar en cada momento. Por ejemplo, una solicitud que involucra generación de código puede enrutar automáticamente a un modelo especializado en esa función, mientras una consulta general de preguntas abiertas puede enviarse a un modelo diferente optimizado para esa tarea. Esto no solo mejora la precisión de las respuestas sino que también optimiza los costos y tiempos de respuesta. Una de las grandes fortalezas del LLM Router es su compatibilidad con la API de OpenAI, lo que facilita su integración en aplicaciones existentes que ya usan clientes OpenAI como LangChain. Gracias a ello, los desarrolladores solo deben realizar mínimas modificaciones para incorporar el LLM Router, agregando metadatos específicos en las solicitudes para definir políticas y estrategias de enrutamiento.
El software está compuesto por tres componentes principales: el Router Controller, que actúa como un proxy para recibir y reenviar peticiones compatibles con OpenAI; el Router Server, que usa servidores de inferencia con modelos entrenados para clasificar las solicitudes según política; y los modelos downstream que reciben finalmente los prompts. Muchos de estos modelos downstream son NVIDIA NIMs, pero también es compatible con otros servicios y modelos hospedados localmente o a través de API compatibles. En cuanto a su funcionamiento interno, el Router Server utiliza modelos de clasificación basados en técnicas avanzadas de machine learning para identificar la tarea o la complejidad del prompt. Por ejemplo, dentro de su política más común, task_router, el servidor categoriza las solicitudes en múltiples tipos de tareas como generación de código, preguntas abiertas, resúmenes, reescritura de textos, y otros. De manera similar, la política complexity_router evalúa la dificultad o el tipo de conocimiento requerido, clasificando prompts en creatividad, razonamiento, conocimiento contextual, entre otros.
La configuración del enrutamiento se realiza a través de un archivo YAML donde se definen las políticas y los modelos asociados a cada categoría. Esto permite una gran flexibilidad para adaptar el sistema a las necesidades específicas de cada proyecto o entorno, haciendo posible incluso la creación de políticas personalizadas según el dominio de aplicación o características especiales. Desde el punto de vista técnico, LLM Router está construido considerando la alta performance y compatibilidad con hardware acelerado por GPU, utilizando Rust en su controlador que aporta velocidad y fiabilidad, y servidores de inferencia NVIDIA Triton, que permiten una baja latencia y rendimiento optimizado para múltiples solicitudes concurrentes. La solución está diseñada para ambientes Linux, con requisitos claros sobre hardware, recomendando GPUs como NVIDIA V100 en adelante, y utiliza contenedores Docker y Docker Compose para facilitar su despliegue. Se requiere también instalar herramientas complementarias, como CUDA Toolkit, para aprovechar la aceleración por GPU.
El proyecto también ofrece soporte para monitoreo a través de Prometheus y Grafana, lo que permite a los equipos de MLOps y desarrolladores recoger métricas relevantes sobre el uso, latencia y rendimiento de cada modelo, facilitando así el ajuste fino y la toma de decisiones informadas en entornos de producción. Para los interesados en personalizar aún más el LLM Router, el código fuente y las herramientas disponibles permiten crear modelos de clasificación propios, afinando los routers para contextos específicos. Por ejemplo, se incluye un caso de uso para clasificar interacciones en un chatbot de soporte bancario personalizando la política de enrutamiento a base de datos históricos o patrones propios. En términos de seguridad, se recomienda especial cuidado en la gestión de claves API y en la protección de la configuración para evitar accesos no autorizados que puedan comprometer tanto costos como integridad de los sistemas. Se enfatiza que el LLM Router no maneja autenticación o autorización de forma nativa por lo cual la capa de seguridad debe implementarse externamente, protegiendo interfaces y restringiendo el acceso a clientes legítimos.
El manejo correcto y seguro de los logs es otro aspecto crucial, ya que por defecto el sistema imprime solicitudes y respuestas para facilitar el desarrollo, pero en producción es indispensable implementar mecanismos para proteger esta información sensible evitando filtraciones. En términos prácticos, el LLM Router representa un avance significativo para las organizaciones que implementan múltiples modelos de lenguaje en paralelo, ofreciendo una herramienta que optimiza el uso de recursos computacionales, mejora la experiencia del usuario final con respuestas más precisas y eficientes, y reduce costos al direccionar la carga al modelo más económico y rápido según la necesidad puntual. Esta herramienta también abre la puerta a la creación de arquitecturas híbridas donde se pueden combinar modelos de proveedores distintos, tanto locales como en la nube, aprovechando las fortalezas específicas de cada uno y evitando bloqueos con un único proveedor o modelo. El impacto para desarrolladores e ingenieros de inteligencia artificial es considerable, ya que facilita la integración y el mantenimiento de sistemas multi-LLM, permitiendo que la gestión del enrutamiento de prompts sea automática y transparente. Esto permite a los equipos concentrarse en el desarrollo de funcionalidades y mejora continua sin preocuparse excesivamente por la complejidad de administrar múltiples modelos.
En conclusión, LLM Router es una solución open-source robusta e innovadora que responde a la necesidad de gestionar de manera inteligente y eficiente la diversidad creciente de modelos de lenguaje grande. Su arquitectura flexible, compatibilidad con estándares y alto rendimiento lo posicionan como una herramienta indispensable para proyectos avanzados de IA que buscan excelencia, optimización y escalabilidad en la utilización de LLMs. Su adopción puede marcar una diferencia significativa en la calidad y costo-efectividad de aplicaciones impulsadas por inteligencia artificial.