El mundo del aprendizaje automático está en constante evolución y la optimización de modelos juega un papel crucial en el logro de resultados efectivos y eficientes. Recientemente, se ha generado un gran interés en el fenómeno conocido como "grokking", un proceso fascinante donde los modelos de machine learning, tras un período inicial de aparente sobreajuste, logran de repente generalizar y alcanzar altos niveles de precisión en datos no vistos. Un avance clave en esta área es la introducción del optimizador Muon, que está demostrando acelerar notablemente el proceso de grokking, transformando la forma en que entrenamos modelos y alcanzamos niveles óptimos de rendimiento. Para entender la relevancia de Muon, primero conviene profundizar en el concepto de grokking. Este término, acuñado por el escritor Robert A.
Heinlein, describe una situación curiosa en la que un modelo parece estar atrapado en una etapa donde solo aprende los datos de entrenamiento con precisión, pero cuando se evalúa en datos de validación o prueba, su desempeño es equivalente al azar. Con el entrenamiento continuo, de manera casi mágica, el modelo “captura” o “grokcea” el patrón subyacente, incrementando rápidamente su precisión de validación a niveles muy altos, más allá del 95%. Este fenómeno ha sido objeto de estudio, ya que desafía las nociones tradicionales sobre la relación entre sobreajuste y generalización. El reciente trabajo desarrollado por Amund Tveit, Bjørn Remseth y Arve Skogvold destaca el impacto del optimizador en la aceleración del grokking, centrándose específicamente en la comparación entre AdamW y Muon. AdamW es uno de los optimizadores más populares y ampliamente usados en la actualidad, valorado por su adaptabilidad y rendimiento en diversos escenarios.
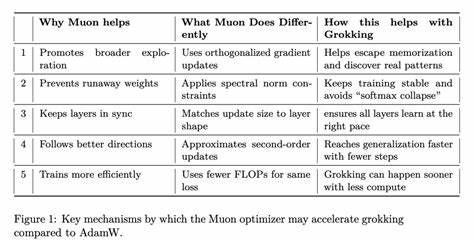
Sin embargo, Muon se ha posicionado como una alternativa innovadora, orientada a optimizar parámetros matriciales internos con técnicas inspiradas en métodos de segundo orden. La esencia del optimizador Muon radica en la utilización de la iteración de Newton-Schulz para ortogonalizar aproximadamente la matriz de actualización derivada de los gradientes. Al tomar los gradientes calculados mediante SGD con momento Nesterov y procesarlos a través de esta iteración, Muon ofrece una actualización más fina y estructurada que potencia la estabilidad y eficacia en la actualización de pesos internos de la red. Este diseño es especialmente beneficioso para entrenar grandes modelos, como los MoE (Mixture of Experts) de millones a miles de millones de parámetros. Uno de los aspectos clave del trabajo es la aplicación de Muon en problemas clásicos de grokking, como el aritmético modular y la paridad binaria.
Estos conjuntos de datos son ideales para observar el grokking, ya que presentan un escenario claro donde el modelo debe aprender un patrón lógico a partir de datos sintéticos con alta complejidad. Los experimentos indican que al utilizar Muon, el grokking se produce mucho antes, alrededor de la época 100, en comparación con la época 150 típica con AdamW. Además, la variabilidad en el tiempo de aparición de grokking se reduce, sugiriendo mayor consistencia y fiabilidad en el proceso de aprendizaje. También es relevante mencionar la influencia de las funciones relacionadas con softmax en el grokking y cómo se abordaron diversas alternativas, como Stablemax y Sparsemax, para mejorar la estabilidad y características estadísticas de las salidas. Estos elementos, combinados con la arquitectura del transformador usada —que incluye embeddings identidad, normalización RMSNorm, activación SiLU y técnicas de regularización como dropout— aseguran un entorno robusto para evaluar la eficacia de Muon.
El éxito de Muon se atribuye a varios factores críticos. Por un lado, las restricciones en la norma espectral que se imponen a través de la ortogonalización de las actualizaciones ayudan a evitar el sobreajuste y la simple memorización de ejemplos, orientando el aprendizaje hacia patrones de verdadera generalización. Por otro lado, el uso de señales de segundo orden en la optimización puede guiar el modelo a regiones del espacio de parámetros donde es más probable encontrar soluciones robustas y explicativas. El impacto práctico es significativo, especialmente en un contexto donde entrenar modelos grandes y complejos consume enormes recursos computacionales. Muon ha mostrado ser aproximadamente el doble de eficiente que AdamW en la capacitación de modelos MoE LLM (modelo de lenguaje de mezcla de expertos) en escalas de billones de tokens.
Esta eficiencia no solo reduce costos sino que también abre la puerta a experimentaciones y despliegues más ágiles en aplicaciones reales. Más allá del desempeño técnico, la introducción de Muon invita a una reflexión sobre el diseño de optimizadores en el aprendizaje automático. La reciente investigacion apunta hacia un entendimiento más profundo de cómo diferentes esquemas de norma y elección de pasos de actualización pueden ser interpretados bajo una óptica de descenso más profundo y matemáticamente fundamentado. Investigaciones paralelas, como el trabajo "Old Optimizer, New Norm: An Anthology", presentan frameworks conceptuales que unifican métodos aparentemente dispares bajo un paraguas teórico común, abriendo el camino para innovaciones futuras en este campo vital. En la práctica, sin embargo, Muon no es una panacea y su uso óptimo requiere consideración específica.
No se recomienda su empleo en embeddings o cabezas de clasificación debido a las diferencias en las dinámicas de optimización de esos componentes, lo que ha sido confirmado empíricamente. Esto enfatiza la importancia de adaptar el optimizador al tipo de parámetros y a la arquitectura del modelo para maximizar beneficios. Además, la aceleración de grokking tiene implicaciones más amplias sobre cómo entendemos el entrenamiento prolongado y las curvas de aprendizaje en machine learning. La posibilidad de acortar la etapa de aparente sobreajuste y obtener resultados sólidos más rápidamente puede cambiar paradigmas en la forma en que se desarrollan, prueban y despliegan modelos. Finalmente, la historia de Muon y su éxito emergente también resalta el papel crucial de la comunidad investigativa abierta y colaborativa.
El código abierto, la discusión accesible y la continua publicación de resultados hacen posible que nuevas ideas se integren rápidamente en el ecosistema, acelerando el progreso general. En resumen, el optimizador Muon representa un avance importante que no solo mejora la eficiencia en el entrenamiento de modelos, sino que también promueve una comprensión más rica y profunda del fenómeno del grokking. Su enfoque innovador basado en la iteración de Newton-Schulz para la ortogonalización y la incorporación de señales de segundo orden ofrece una nueva perspectiva sobre cómo optimizar modelos de manera más inteligente y efectiva. A medida que la investigación continúa y se exploran aplicaciones en modelos mayores y tareas más complejas, es probable que Muon y desarrollos similares desempeñen un papel central en el futuro del aprendizaje automático avanzada.