La evolución constante de las tecnologías de inteligencia artificial ha impulsado el desarrollo de modelos de lenguaje cada vez más sofisticados y exigentes en cuanto a rendimiento. En este sentido, SGLang ha emergido como una plataforma moderna para servir modelos de lenguaje a gran escala (LLM), destacando por su arquitectura optimizada y por su compatibilidad con diversas estrategias de atención. Uno de los componentes vitales que contribuye al alto rendimiento de SGLang es la implementación del backend Flash Attention, especialmente en su versión 3, que ha logrado transformar la manera en la que se ejecutan los mecanismos de atención, fundamentales en modelos como Transformers. Flash Attention es un algoritmo de atención exacta que se distingue por su enfoque consciente del Input/Output (IO), diseñado para minimizar las operaciones de lectura y escritura entre la memoria de alta ancho de banda del GPU (HBM) y la memoria caché interna (SRAM). Esto se logra mediante técnicas de 'tiling' o división de tareas en bloques que permiten un uso más eficiente de los recursos de hardware, lo que se traduce en una mejora sustancial en la velocidad y el rendimiento durante la inferencia y el entrenamiento de modelos grandes.
Su adopción en motores de inferencia modernos ha sido rápida debido a esta eficiencia y a la precisión que ofrece en el cálculo de los mecanismos de atención. En el ecosistema de SGLang, el backend de atención no es solo un módulo más, sino el cuello de botella crítico en la mayoría de las cargas de trabajo, ya que las operaciones de auto-atención consumen gran parte del tiempo de computación durante una pasada hacia adelante del modelo. Para enfrentar este desafío, SGLang ha desarrollado una arquitectura que segmenta claramente las responsabilidades en tres componentes: el servidor, que maneja las solicitudes entrantes y las respuestas; el programador, que construye lotes o batches optimizados para la ejecución; y el modelo, encargado de la inferencia propiamente dicha. Dentro del proceso de inferencia, el backend de atención adquiere protagonismo cuando el modelo procesa cada capa, especialmente las capas de auto-atención multi-cabezal (MHA) y sus variantes. Es aquí donde Flash Attention ofrece su valor añadido, ya que puede ejecutar estas operaciones complejas con una latencia y uso de memoria reducidos.
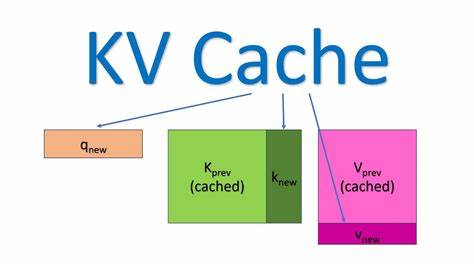
SGLang soporta varias variantes de atención, como MLA, GQA, atención deslizante y local, lo que requiere que el backend esté diseñado con gran flexibilidad y optimización adaptada. Una pieza central para lograr este desempeño es el manejo del KV Cache, o caché de claves y valores, que almacena de manera eficiente los estados intermediarios necesarios para la atención durante la generación secuencial de texto. En SGLang, el KV Cache se gestiona mediante dos niveles de memoria: uno que mapea las solicitudes (requests) a los tokens en caché, y otro que almacena los datos reales de clave y valor para cada capa y cabeza de atención. El primer nivel, denominado req_to_token_pool, relaciona cada solicitud con los índices que representan los tokens almacenados en el caché. Su estructura es un tensor bidimensional cuya primera dimensión corresponde al número máximo de solicitudes concurrentes configurado, y la segunda al contexto máximo permitido por modelo.
Por ejemplo, si se manejan dos solicitudes simultáneas con siete tokens cada una, el tensor podría verse como una matriz con valores únicos para cada token asignado. El segundo nivel, token_to_kv_pool, utiliza estos índices para acceder a los datos concretos de clave (k) y valor (v) guardados para cada capa, divididos por cabeza y dimensión de cabeza. Esta estructura permite que el backend recupere de manera rápida y conjunta el estado almacenado necesario para continuar la inferencia sin recomputar información pasada. Implementar Flash Attention en SGLang implica integrar esta gestión del KV Cache directamente con la API flash_attn_with_kvcache de Tri Dao. Esta API simplifica la llamada a Flash Attention al aceptar un mapa completo o tabla de páginas (page_table) que representa el caché paginado, permitiendo así manejar contextos y lotes de gran tamaño sin incurrir en la sobrecarga de construir manualmente las matrices de claves y valores.
En la implementación básica, se define un objeto de metadatos que agrupa elementos fundamentales para la ejecución, como las secuencias de cachés en tipo int32, los máximos tamaños de secuencia para consulta y caché, las secuencias acumuladas para consulta y claves, y la tabla de páginas que representa el mapeo de tokens. Estos metadatos se inicializan al iniciar la pasada hacia adelante del modelo y se reutilizan para cada capa durante la inferencia, lo que aporta eficiencia tanto en tiempo de ejecución como en uso de memoria. La función forward_extend se encarga de procesar los lotes de entradas cuando se amplía el contexto, como al generar nuevos tokens en paralelo para varios usuarios o solicitudes. En este punto, las claves y valores generados por el modelo se almacenan en el KV Cache utilizando el mapeo correspondiente, y luego se invoca flash_attn_with_kvcache para computar la salida de atención con las dependencias del caché adecuadamente gestionadas. En escenarios de decodificación, donde típicamente se procesa token por token para generación autoregresiva, la funció́n forward_decode opera con parámetros ligeramente adaptados, pero sigue apoyándose en la misma estructura de metadatos y flujo de trabajo.
Esto garantiza que, independientemente del modo de ejecución, el backend Flash Attention en SGLang mantenga un alto rendimiento y precisión. Un avance significativo en la optimización de la ejecución es la integración con CUDA Graphs, una capacidad que permite capturar y reproducir secuencias de operaciones GPU como un solo gráfico ejecutable. Esto reduce considerablemente la latencia y el overhead provocado por múltiples lanzamientos individuales de kernels desde la CPU y maximiza la utilización del hardware. En SGLang, el soporte para CUDA Graph se gestiona mediante la clase CUDAGraphRunner, que interactúa con el backend para preparar estados, capturar la ejecución y luego reproducirla eficientemente. Este proceso requiere la preasignación de tensores fijos para almacenar los metadatos que serán utilizados en la gráfica, así como la correcta inicialización y actualización de sus valores para garantizar la coherencia y evitar errores en la captura.
Durante la fase de captura del CUDA Graph, se preparan los metadatos con valores aparentemente arbitrarios pero con las dimensiones y tipos correctos. Luego, en la fase de reproducción, estos metadatos se actualizan con los valores reales de la ejecución, tales como las secuencias acumuladas y la tabla de páginas asociada a las solicitudes activas. La correcta implementación de estos pasos asegura que la ejecución en GPU sea rápida, precisa y repetible, lo que se traduce en mejoras cuantificables en la latencia de los modelos de lenguaje. La conjunción de Flash Attention con una gestión eficiente del KV Cache y la utilización estratégica de CUDA Graphs posiciona a SGLang como un motor de inferencia puntero para grandes modelos de lenguaje. No solo mejora el rendimiento bruto, sino que también ofrece soporte para características avanzadas como especulative decoding, atención multi-cabezal y atención para modalidades múltiples, allanando el camino para aplicaciones más avanzadas e integradas en el futuro.
Además de sus méritos técnicos, la implementación en SGLang destaca por estar en una comunidad activa y abierta al desarrollo colaborativo, permitiendo que más investigadores y profesionales contribuyan a la evolución del proyecto. Este entorno abierto es fundamental para mantener el ritmo de innovación en un área tan dinámica como el aprendizaje automático y el procesamiento del lenguaje natural. Para quienes estén interesados en profundizar o contribuir al desarrollo de backends de atención optimizados, el estudio de la implementación de Flash Attention en SGLang ofrece una referencia detallada y actualizada. Comprender su arquitectura, el manejo del KV Cache y la integración con CUDA Graph es esencial para diseñar sistemas que satisfagan las demandas actuales y futuras de la inteligencia artificial a gran escala. En conclusión, la implementación del backend Flash Attention en SGLang representa un hito significativo en la optimización del rendimiento para modelos de lenguaje.
Su diseño cuidadoso en los fundamentos, junto con la sofisticada gestión del KV Cache y la incorporación del soporte para CUDA Graph, hacen que SGLang sea una solución robusta y eficiente para servir modelos avanzados. Esta infraestructura no solo aporta beneficios técnicos inmediatos, sino que también establece la base para incorporar futuras capacidades de manera eficiente y escalable.