.janicre representa un avance significativo en la manera en que los modelos de lenguaje extenso (LLMs, por sus siglas en inglés) pueden interactuar con bases de código complejas y dispersas. Los modelos de lenguaje, aunque poderosos, enfrentan restricciones naturales cuando intentan procesar proyectos reales que sobrepasan con creces el límite típico de tokens de contexto, que ronda los 128 mil tokens. Además, los proyectos modernos suelen estar distribuidos en múltiples archivos y diversas tecnologías, lo que dificulta que un modelo pueda ofrecer asistencia efectiva y coherente. Ante esta problemática surge .
janicre, un lenguaje de especificación estructural minimalista diseñado específicamente para que sistemas de software sean comprendidos por LLMs de manera integral y eficiente. El desafío principal que aborda .janicre radica en cómo representar la información esencial de un proyecto sin necesidad de exponer todo el código fuente, lo que puede comprometer la privacidad o generar costes computacionales elevados. Técnicas como la recuperación aumentada con generación (RAG) o las entradas con gran contexto aunque útiles, suelen presentar problemas como el leakage de código sensible, baja capacidad para razonar a través de múltiples archivos o costos computacionales elevados debido a la complejidad cuadrática de la tokenización y análisis de grandes cantidades de texto. Para afrontar estos retos, .
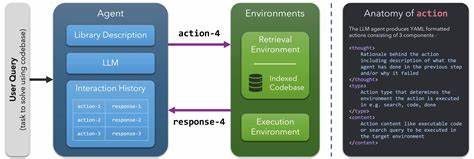
janicre introduce un enfoque basado en una representación intermedia estructurada en un formato unificado JSON-YAML. Este formato permite convertir diversos artefactos de programación —ya sea código Python, JavaScript, HTML o cualquier otro lenguaje— en un manifiesto común que expresa el propósito del sistema, su jerarquía interna, los conceptos semánticos claves, la teoría subyacente y las restricciones aplicables. Al hacerlo, facilita que los modelos de lenguaje puedan captar no solo qué se está construyendo, sino también cómo las diferentes partes del sistema se relacionan entre sí y por qué se aplican determinados algoritmos o decisiones técnicas. El diseño minimalista de .janicre no solo facilita la comprensión sino que también optimiza la complejidad en términos del número de tokens que los LLMs deben procesar.
La formalización del esquema demuestra que la complejidad crece de manera logarítmica con respecto al tamaño del software, lo que significa un avance considerable frente a la complejidad cuadrática que presentan otros métodos. Esto permite que modelos puedan analizar bases de código mucho más grandes sin perder eficiencia ni capacidad de razonamiento. Otro aspecto destacable es cómo .janicre protege el código privado. Al transformar la información en una representación abstracta centrada en las intenciones y estructuras, se evita la exposición directa de fragmentos de código que podrían contener datos sensibles o propiedad intelectual, mitigando riesgos de seguridad y privacidad que suelen preocupar a desarrolladores y organizaciones.
Más allá de la eficiencia técnica y la seguridad, .janicre plantea un marco para evaluación empírica. Se propone comparar metodologías tradicionales de recuperación de código y prompting extendido con esta representación estructurada intermedia, midiendo indicadores como la precisión en la comprensión, la calidad en la generación de respuestas y la capacidad de razonamiento sobre múltiples componentes y lenguajes. Esta comparación permitirá ajustar y mejorar aún más la metodología, consolidándola como un estándar en el análisis colaborativo entre humanos y máquinas. El potencial impacto de .
janicre en el ecosistema de desarrollo es amplio y multidimensional. Primero, posibilita que los LLMs asuman un rol más activo y efectivo en la asistencia de programadores, facilitando tareas como la navegación de código, la detección de errores, la documentación automatizada y la generación de snippets de código relevantes. La agrupación lógica y semántica de componentes mediante el manifiesto ayuda a los modelos a ofrecer recomendaciones más contextuales y precisas. Además, a nivel organizacional, al implementar .janicre, las empresas pueden mantener grandes bases de código con mayor coherencia y claridad en la estructura, lo que se traduce en una mejor gestión del conocimiento interno.
Esto resulta especialmente valioso en proyectos con larga vida útil, cambios continuos y equipos multidisciplinarios que interactúan con diferentes tecnologías. Desde el punto de vista de la investigación, .janicre abre un espacio para explorar nuevas formas de entender sistemas complejos mediante modelos de lenguaje, fusionando conceptos de ingeniería de software, lingüística computacional y aprendizaje automático. Su enfoque formal y esquemático puede servir como base para futuras generaciones de herramientas inteligentes que no sólo lean código sino que lo interpreten con profundidad, comprendiendo intenciones, limitaciones y objetivos en contextos reales. Aunque .
janicre representa un avance prometedor, su adopción generalizada aún implica desafíos. Es necesario crear herramientas amigables para los desarrolladores que automaticen la generación del manifiesto JSON-YAML a partir del código fuente existente, así como mecanismos para mantenerlo actualizado en procesos de desarrollo continuo. Asimismo, incentivar a la comunidad para que valide, extienda y adapte el lenguaje a múltiples paradigmas y lenguajes emergentes garantizará su relevancia a largo plazo. En conclusión, .janicre surge como un puente entre el vasto y fragmentado mundo de los códigobases modernos y la capacidad analítica de los modelos de lenguaje extensos.
Ofrece una solución estructurada, eficiente y segura para que estos modelos entiendan el propósito, estructura y lógica detrás de sistemas de software complejos. Su esquema unificado permite superar limitaciones tradicionales, abrir nuevas fronteras en la colaboración humana-máquina y optimizar procesos de desarrollo y mantenimiento de software en la era de la inteligencia artificial.