La integración de la inteligencia artificial (IA) en la medicina es una de las transformaciones más significativas en el ámbito sanitario moderno. Con el avance de los modelos de lenguaje de gran escala, surgen expectativas sobre su capacidad para mejorar el acceso a información médica, asistir a los profesionales de salud en la toma de decisiones y empoderar a los pacientes en el cuidado de su bienestar. Sin embargo, para que estas tecnologías sean útiles y, sobre todo, seguras, es fundamental contar con evaluaciones rigurosas que validen su desempeño en situaciones reales y complejas. En este contexto surge HealthBench, un benchmark o banco de pruebas innovador que busca medir con precisión la efectividad de los sistemas de IA en escenarios clínicos auténticos y multifacéticos. HealthBench no es un conjunto típico de preguntas tipo examen; su fortaleza radica en replicar conversaciones realistas entre usuarios y modelos de IA, reflejando interacciones clínicas que abarcan desde consultas de atención primaria hasta casos difíciles y urgentes que requieren discernimiento, comunicación precisa y relevancia contextual.
Esta plataforma fue desarrollada en colaboración con 262 médicos que practican en más de 60 países, con experiencia en 26 especialidades médicas, lo que garantiza una visión global y multidisciplinaria de la calidad esperada para las respuestas generadas por IA. La base del benchmark consiste en cinco mil conversaciones cuidadosamente diseñadas para simular interacciones típicas y complejas, incluyendo a pacientes, cuidadores y profesionales de la salud. Cada conversación se acompaña de una rúbrica personalizada creada por médicos expertos que define criterios específicos para evaluar las respuestas de los modelos de IA. Estos criterios valorizan aspectos esenciales como la precisión del contenido, la claridad en la comunicación, la adecuación del lenguaje según el interlocutor y la capacidad de manejar incertidumbre o información incompleta. Una característica única de HealthBench es el amplio rango de criterios de evaluación, que suma más de 48 mil ítems distintos.
Esta riqueza permite evaluar con detalle múltiples dimensiones del desempeño de un modelo, desde la exactitud médica hasta la calidad ética y la gestión del contexto. Para implementar esta evaluación a gran escala, OpenAI introdujo un sistema de calificación automatizado mediante GPT-4.1, que verifica si los criterios de la rúbrica se cumplen en la respuesta, asignando una puntuación general al modelo. El propósito de HealthBench va más allá de validar modelos existentes: también busca fomentar mejoras continuas en la IA aplicada a la salud, incentivando el desarrollo de sistemas más seguros, confiables y útiles para diversos usuarios. A diferencia de otros benchmarks saturados donde los modelos han alcanzado un techo de desempeño, HealthBench mantiene casos difíciles y nuevos retos, lo que promueve avances genuinos y sostenidos.
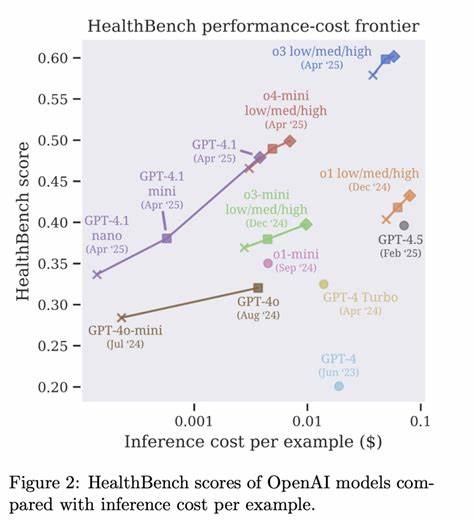
Uno de los ámbitos donde HealthBench destaca es en la evaluación bajo temas específicos, que incluyen la identificación y remisión de emergencias, la comunicación adaptada al nivel de experiencia del usuario, el manejo de incertidumbre, la interpretación de datos clínicos y la atención en salud global. Esta segmentación permite a los desarrolladores entender mejor las fortalezas y debilidades de sus sistemas en contextos variados. Además de evaluar los modelos, HealthBench ha servido para comparar sistemas recientes de referencia con respuestas de médicos expertos. Resultados preliminares indican que los modelos más avanzados, como GPT-4.1 y o3, no solo han mejorado considerablemente respecto a versiones anteriores, sino que en algunos casos han alcanzado o incluso superado la calidad de las respuestas generadas por profesionales, especialmente cuando estos no contaban con referencias adicionales.
Este hallazgo refleja el potencial de la IA para replicar juicios clínicos complejos y apoyar la toma de decisiones médicas. No obstante, el benchmark también ha identificado áreas críticas donde los modelos aún deben mejorar. Entre ellas destacan la capacidad para solicitar información necesaria cuando las preguntas son ambiguas, la gestión de escenarios de alto riesgo con fiabilidad extrema y la interpretación adecuada de variables contextuales específicas. La mejora continua en estas áreas es vital para garantizar que la IA no solo sea efectiva, sino también segura y ética en su aplicación en salud. El componente de confiabilidad es particularmente relevante en el sector sanitario, donde un error o respuesta incorrecta puede tener consecuencias graves para los pacientes.
HealthBench aborda esta necesidad al medir la consistencia de los modelos a través de pruebas repetidas y evaluación del peor rendimiento posible, asegurando que los sistemas mantengan estándares mínimos en todo momento. Esta enfoque impulsa el desarrollo de modelos robustos que mitiguen riesgos y potencien beneficios. En cuanto a la accesibilidad y equidad, HealthBench incorpora conversaciones multilingües y considera distintos perfiles de usuarios, desde pacientes hasta médicos especialistas, lo que permite evaluar la adaptabilidad de los modelos en contextos culturales y sociales diversos. Esta característica es especialmente relevante para llevar soluciones tecnológicas a entornos de recursos limitados, donde la IA puede desempeñar un papel crucial en ampliar el acceso a la atención médica. OpenAI ha puesto a disposición de la comunidad científica y los desarrolladores el conjunto completo de HealthBench y sus herramientas mediante su repositorio público en GitHub.
Esta apertura fomenta la colaboración, la transparencia y la aceleración en la mejora de modelos para salud, al tiempo que permite recibir retroalimentación y contribuciones de expertos globales. El lanzamiento de HealthBench representa un paso estratégico en la evolución de la inteligencia artificial aplicada a la medicina. Gracias a un diseño riguroso, fundamentado en la experiencia clínica real y validado por profesionales alrededor del mundo, brinda un método confiable para cuantificar el rendimiento y seguridad de sistemas que pueden transformar la práctica médica. En resumen, HealthBench combina profundidad, realismo y rigor para evaluar la interacción entre humanos y modelos de IA en salud, apoyando el desarrollo de tecnologías que puedan actuar como compañeros efectivos y seguros en el cuidado clínico. Su enfoque en escenarios auténticos, diversidad global y criterios médicos detallados lo posicionan como la referencia principal para investigadores y compañías dedicadas a crear soluciones AI de próxima generación en salud.
Al fortalecer la confianza y la efectividad de las herramientas de IA, HealthBench está allanando el camino para que la inteligencia artificial no solo aumente la eficiencia del sistema sanitario, sino que realmente mejore los resultados para pacientes y comunidades en todo el mundo. De cara al futuro, la incorporación recurrente de nuevos casos clínicos, métricas de evaluación actualizadas y la constante colaboración con profesionales médicos serán claves para mantener su relevancia y eficacia. Por ello, HealthBench no solo es una evolución tecnológica, sino también un impulso ético y social para que la inteligencia artificial se integre con responsabilidad, rigor científico y un profundo compromiso con la salud humana.