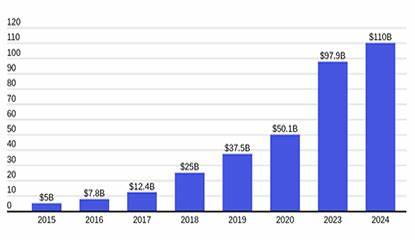
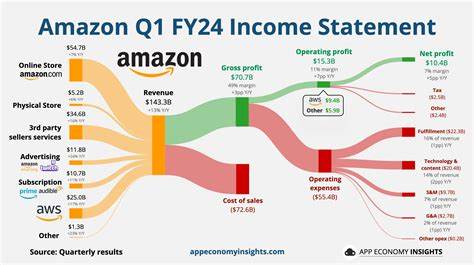
En los últimos años, los modelos de lenguaje grande (LLM, por sus siglas en inglés) han revolucionado la forma en que interactuamos con la tecnología, ofreciendo capacidades impresionantes en procesamiento de lenguaje natural, generación de texto, traducción y mucho más. A pesar de estos avances, un tema recurrente que surge entre desarrolladores y usuarios experimentados es la importancia vital de formular prompts o indicaciones explícitas para que dichos modelos puedan entregar resultados útiles y precisos. La ausencia de una intención clara en la solicitud limita severamente su utilidad, especialmente en tareas que requieren un nivel alto de detalle o mantenimiento, como la creación de código estructurado y sostenible. El problema central radica en la naturaleza misma de los LLM. Estos modelos se entrenan con una gran cantidad de datos textuales y, a partir de patrones estadísticos, generan respuestas que parecen coherentes y contextualmente adecuadas.
Sin embargo, esta generación no implica una comprensión profunda o razonamiento complejo, sino una predicción probabilística de la siguiente palabra o fragmento. Por esta razón, si la indicación es vaga o ambigua, el modelo puede interpretarla de múltiples formas, lo que se traduce en resultados inconsistentes, erróneos o directamente confusos. Un desafío común que enfrentan quienes trabajan con LLM es la capacidad limitada del modelo para autocorregirse. A diferencia de un humano, que puede revisar su trabajo y ajustarlo en función de errores evidentes o retroalimentación, los modelos no poseen un mecanismo interno efectivo para detectar y corregir las imprecisiones generadas anteriormente. En consecuencia, si al generarse una respuesta se infiltra información irrelevante o incorrecta, el proceso se perpetúa, lo que puede dar lugar a un ciclo interminable de recopilación de errores y contenido poco fiable.
Este fenómeno es especialmente problemático en contextos profesionales, sobre todo cuando se espera que el modelo entregue código limpio, eficiente y fácil de mantener. Cuando se aborda la generación de software mediante LLM, la expectativa de que el código producido sea automáticamente mantenible, escalable y estructurado resulta, por ahora, irreal. Sin indicaciones claras y bien definidas, los modelos tienden a producir soluciones superficiales, generalmente basadas en fragmentos disponibles en sus datos de entrenamiento, que carecen de arquitecturas sólidas o patrones de diseño. Esto genera código que es más un parche improvisado que una base sólida para futuros desarrollos. La experiencia de muchos usuarios muestra que los LLM no alcanzan de forma autónoma las mejores prácticas de ingeniería de software sin obtener una guía precisa y detallada durante el proceso de generación.
Esta limitación no implica un fracaso total de la tecnología; más bien nos sitúa en un punto donde la colaboración humano-máquina es esencial para alcanzar resultados óptimos. Mientras los modelos continúan evolucionando y mejorando en precisión y comprensión contextual, el papel del usuario es fundamental para diseñar prompts que articulen claramente los objetivos, restricciones y expectativas. Solo mediante indicaciones explícitas y exhaustivas, los LLM pueden aprovechar su capacidad para producir contenido valioso y funcional dentro de los parámetros establecidos. Los expertos señalan que esta necesidad de claridad en la comunicación con los modelos es comparable a las dinámicas presentes en equipos humanos. Ningún colaborador puede interpretar correctamente una tarea sin una definición clara y un entendimiento compartido del propósito.
Así como en el desarrollo ágil se realizan reuniones constantes para alinear el trabajo y corregir el rumbo antes de avanzar, la interacción con LLM requiere una planificación cuidadosa y supervisión continua para evitar que el producto final pierda cohesión o caiga en errores. Además, la precisión y el mantenimiento en el desarrollo de sistemas informáticos no solo dependen de cumplir con una función, sino de garantizar que el código sea legible, modular y fácil de adaptar con el tiempo. Para que un modelo de lenguaje pueda generar este tipo de código, necesita instrucciones específicas sobre estándares de estilo, modularidad, nombres de variables, estructura de carpetas, manejo de errores, entre otros aspectos cruciales. Sin esta explicitud, el resultado inevitablemente carecerá de la calidad requerida en entornos profesionales o colaborativos. A nivel de futuro y desarrollo tecnológico, es importante reconocer que se están llevando a cabo investigaciones para ampliar el horizonte de capacidades de los LLM, incluyendo la mejora en su capacidad para gestionar tareas de larga duración o incorporar retroalimentación en bucles más extensos.
Sin embargo, los tiempos estimados para que estos avances consoliden la generación automática y autónoma de código mantenible se sitúan a varios años vista. En este lapso, la interacción estructurada, clara y meticulosa seguirá siendo la clave para sacar el máximo provecho de estas herramientas. En conclusión, los modelos de lenguaje grande han abierto un nuevo abanico de posibilidades que permiten aumentar la productividad, acelerar procesos y automatizar tareas en múltiples ámbitos. No obstante, la condición para maximizar su valor y lograr resultados confiables y útiles es hacer uso de prompts explícitos que definan con precisión la intención del usuario. Sin esta claridad, los LLM se ven relegados a un nivel de utilidad limitado, resultando en generados poco estructurados, errores recurrentes y, en resumen, una experiencia frustrante para quienes buscan soluciones sofisticadas y de alta calidad.
Por tanto, el futuro del trabajo conjunto con inteligencia artificial en la creación de contenido, y más específicamente en la programación, dependerá tanto del avance tecnológico como del dominio que los usuarios logren al formular sus consultas e indicaciones.