Apache Spark se ha consolidado como una de las plataformas de procesamiento de datos en tiempo real más robustas y escalables, utilizada por miles de empresas para ejecutar cargas de trabajo complejas. No obstante, al trabajar con volúmenes masivos de datos y entornos distribuidos, optimizar el rendimiento de los trabajos de Spark se convierte en un reto significativo. Aquí es donde SparkMeasure emerge como una herramienta indispensable para desarrolladores, ingenieros de datos y equipos de operaciones que buscan mejorar la eficiencia y detectar problemas de rendimiento en sus aplicaciones Spark. SparkMeasure es un proyecto open source que facilita la recopilación, el análisis y la monitorización detallada de métricas de desempeño de trabajos ejecutados en Apache Spark. Al permitir el acceso tanto a métricas de nivel de etapa como de tarea, SparkMeasure brinda un conocimiento profundo sobre cómo se comportan los procesos durante la ejecución, cuáles recursos están siendo más demandados y en qué puntos se generan cuellos de botella que afectan la productividad y escalabilidad.
La importancia de contar con un análisis pormenorizado del rendimiento radica en que el simple tiempo de ejecución no siempre refleja las causas reales de un comportamiento subóptimo. Por ejemplo, un trabajo puede demorar demasiado sin que el motivo sea la cantidad de datos procesados o la lógica aplicada, sino debido a problemas de desbalanceo en las tareas, ineficiencias en la gestión de memoria o altos tiempos de espera durante operaciones de shuffle. SparkMeasure ofrece una visión integral a partir de las métricas recopiladas, facilitando una identificación acertada de estos puntos críticos. Uno de los mayores atractivos de SparkMeasure es su versatilidad y facilidad de integración. Puede utilizarse directamente desde entornos interactivos como notebooks de Jupyter, spark-shell o PySpark, lo que lo hace ideal para una depuración rápida y sesiones exploratorias.
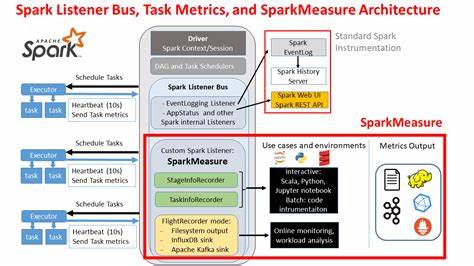
Además, su integración en pipelines de desarrollo y sistemas de integración continua permite establecer comparativas precisas entre diferentes versiones de código o configuraciones de Spark, ayudando a mantener la calidad del rendimiento a lo largo del ciclo de vida del software. Otra característica notable es el modo Flight Recorder, una modalidad que recopila métricas de manera transparente durante la ejecución de trabajos batch sin necesidad de modificar el código existente. Los datos así obtenidos pueden almacenarse para análisis posteriores o enviarse en tiempo real a sistemas externos como Apache Kafka, InfluxDB y Prometheus Push Gateway. Esta flexibilidad permite una observabilidad continua y reactiva, esencial para ambientes productivos donde el monitoreo detallado es indispensable. Desde el punto de vista técnico, SparkMeasure se apoya en la interfaz de listeners de Apache Spark, que es la misma utilizada por herramientas como la interfaz web y el Histórico de Spark para recolectar información relevante.
Esto garantiza que la herramienta no interfiera negativamente en la ejecución y que sus métricas sean confiables y coherentes con las fuentes oficiales del ecosistema Spark. El análisis que propone SparkMeasure puede realizarse a dos niveles diferentes: por etapa o por tarea. La agregación por etapas resulta más ligera y generalmente suficiente para una visión general del rendimiento, mientras que la recopilación granular por tarea permite detectar problemas específicos como tareas que tardan más de lo esperado o que consumen recursos excesivos. Esta dualidad brinda al usuario la posibilidad de ajustar el nivel de detalle según sus necesidades y recursos disponibles. En términos prácticos, para empezar a usar SparkMeasure en su entorno, basta con incorporar el paquete correspondiente a la versión de Spark y Scala que se esté utilizando, ya sea a través de la opción --packages en spark-shell, pyspark o directamente incluyendo el JAR en el classpath.
Posteriormente, se puede instrumentar el código para iniciar y detener la medición o bien emplear métodos que permitan ejecutar consultas y recopilar las métricas de forma sencilla con mínimas líneas de código. Esta simplicidad es crucial para fomentar su adopción por parte de equipos técnicos sin que represente una carga adicional durante el desarrollo. Además, SparkMeasure ofrece reportes detallados y configurables. Estos informes pueden imprimirse en consola, guardarse en archivos o enviarse a sistemas de monitorización para su visualización en dashboards personalizados. Entre las métricas más relevantes que recopila se encuentran tiempos acumulados de ejecución, utilización de CPU, tiempos de deserialización, detalles sobre la gestión de memoria, actividad de lectura y escritura de datos, y muy especialmente todas las actividades relacionadas con las operaciones de shuffle, que son habitualmente fuentes críticas de problemas de rendimiento.
La capacidad de SparkMeasure para generar análisis exhaustivos a partir de métricas oficiales hace que no solo sea una herramienta para la detección y resolución de problemas, sino también una valiosa fuente educativa para quienes desean entender más a fondo el funcionamiento interno de Apache Spark. El proyecto incluye además ejemplos y tutoriales tanto para usuarios avanzados como principiantes, en los lenguajes más populares de Spark, incluyendo Scala, Java y Python. Entre las limitaciones conocidas, es importante destacar que SparkMeasure no captura métricas relacionadas con código que se ejecute fuera del entorno JVM, como es el caso de algunos UDFs escritos en Python que corren en un daemon separado. Asimismo, en entornos donde existen múltiples trabajos concurrentes, puede ocurrir un solapamiento en la captación de métricas si no se gestiona adecuadamente, debido a que los datos se recopilan por etapas o tareas sin aislación automática. La comunidad que respalda SparkMeasure continúa trabajando en la evolución de sus capacidades, con un repositorio activo donde se añaden mejoras, se atienden issues y se aportan nuevas funcionalidades.
Esto garantiza que la herramienta se mantenga actualizada con las últimas versiones de Apache Spark y pueda adaptarse a nuevos requerimientos técnicos y de usuario. En un mundo donde la transformación digital y el análisis de datos son motores fundamentales para la innovación, contar con herramientas que amplíen la capacidad de diagnóstico y optimización, como SparkMeasure, es una ventaja competitiva esencial. Su uso ayuda a reducir costes de infraestructura, evitar tiempos muertos y mejorar la experiencia general de los equipos técnicos, traduciéndose en procesos más ágiles y resultados más confiables. Elegir SparkMeasure para el análisis del rendimiento de trabajos Apache Spark es optar por una solución respaldada por la experiencia técnica y una comunidad dedicada al perfeccionamiento del ecosistema de Big Data. Su enfoque en la transparencia, la integración y el detalle hacen que sea una herramienta recomendada tanto para entornos de desarrollo como para producción, brindando el soporte necesario para alcanzar niveles óptimos de desempeño en cualquier escenario.
En conclusión, SparkMeasure es un aliado fundamental para quienes gestionan y desarrollan aplicaciones basadas en Apache Spark. Su capacidad para medir, analizar y visualizar métricas de rendimiento con precisión y flexibilidad lo posiciona como una herramienta clave en el arsenal de cualquier profesional de datos que aspire a dominar el rendimiento, la eficiencia y la calidad en sus proyectos de procesamiento en gran escala.




![The Synthesizer - a blessing or a curse? (1983) [video]](/images/1159D4AA-1374-438C-877C-CBBFCDE35847)