En el mundo actual, donde la cantidad de datos generados crece exponencialmente, la eficiencia en el almacenamiento y procesamiento de la información se ha vuelto vital para las organizaciones que buscan obtener ventajas competitivas. Uno de los conceptos fundamentales para alcanzar esta eficiencia es el almacenamiento columnar, una técnica cada vez más popular, especialmente en entornos de análisis de datos a gran escala. El almacenamiento columnar representa una evolución significativa respecto al almacenamiento tradicional basado en filas, pues cambia la manera en que se organizan los datos en el disco y en memoria. Para comprender su importancia, primero es necesario contrastar ambos enfoques y evaluar cómo impactan en el rendimiento y la escalabilidad de las consultas analíticas. El almacenamiento tipo fila guarda los registros completos uno tras otro.
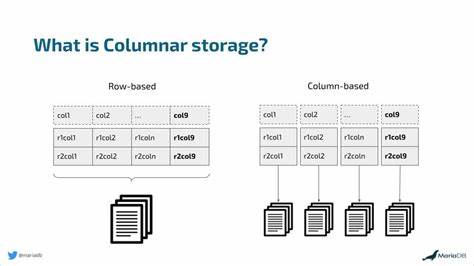
Esto significa que todos los campos de una fila determinada se almacenan juntos. Este modelo es óptimo para sistemas transaccionales que requieren operaciones rápidas de inserción, actualización o eliminación de registros completos, como en bases de datos OLTP (Procesamiento de Transacciones en Línea). Sin embargo, conforme los volúmenes de información crecen y las consultas se orientan principalmente a la agregación o el filtrado de columnas específicas, este modelo muestra limitaciones significativas. En contraste, el almacenamiento columnar organiza los datos agrupándolos por columnas en lugar de por filas. La información de cada columna se almacena de forma contigua, lo que conlleva beneficios importantes para análisis y consultas masivas.
Por ejemplo, cuando una consulta requiere examinar solo algunas columnas de una tabla enorme, el sistema puede acceder únicamente a los datos relevantes, ignorando el resto. Esto reduce considerablemente la cantidad total de datos leídos y, en consecuencia, disminuye el tiempo de respuesta y el uso de recursos. Más allá de esta optimización en el acceso, el almacenamiento columnar facilita una compresión mucho más eficiente. Al guardar datos homogéneos juntos, se pueden aplicar técnicas especializadas como codificación por diccionario, codificación por longitud de ejecución y empaquetado de bits, lo que resulta en archivos más pequeños y velocidades de lectura superiores. Estas características son particularmente valiosas en ecosistemas cloud y big data, donde los costos de almacenamiento y procesamiento impactan directamente el presupuesto.
El auge de formatos como Apache Parquet y Apache ORC ejemplifica la demanda y adopción masiva del almacenamiento columnar en la actualidad. Apache Parquet, desarrollado inicialmente por Twitter y Cloudera, es uno de los formatos más empleados gracias a su compatibilidad con numerosas plataformas modernas como Spark, Presto y BigQuery. Su estructura se basa en divisiones horizontales llamadas grupos de filas que contienen numerosos fragmentos columnarizados, permitiendo una lectura selectiva eficaz y la aplicación de compresiones híbridas. Por otra parte, Apache ORC, diseñado para el ecosistema Hadoop, ofrece funcionalidades avanzadas como índices incorporados que aceleran las consultas al saltar bloques de datos irrelevantes, junto con una excelente relación de compresión y un manejo robusto de metadatos. Ambos formatos, junto con otros, impulsan la evolución de data lakes y almacenes de datos modernos, haciendo viable el manejo de volúmenes masivos con agilidad y bajo costo.
En términos de aplicación real, compañías como Uber y Criteo ilustran cómo la implementación del almacenamiento columnar transforma la gestión de sus datos. Uber, con una infraestructura que manipula cientos de petabytes, mejoró sustancialmente la eficiencia al cambiar su método de compresión en archivos Parquet de SNAPPY y Gzip a Zstandard, alcanzando reducciones de tamaño hasta del 39% y acelerando las consultas, lo que impactó directamente en la reducción de costos de cómputo y almacenamiento. Criteo, por su parte, enfrentaba desafíos de flexibilidad y rendimiento con su antiguo formato RCFile y ganó en agilidad y capacidad al migrar a Parquet, beneficiándose de la mejor integración con motores modernos y una mayor eficiencia en el almacenamiento y procesamiento. Estos casos muestran que el almacenamiento columnar no solo es teórico, sino una práctica empresarial que optimiza sistemas a escala colosal. Un concepto muy relevante del almacenamiento columnar es la posibilidad de ejecución vectorizada.
Esta técnica permite procesar bloques enteros de datos de una columna en una sola operación mediante instrucciones SIMD en el CPU, acelerando notablemente los cálculos y filtros. La ejecución vectorizada es una pieza clave en motores analíticos como DuckDB, Spark y Trino, elevando el rendimiento de las consultas complejas que involucran millones o miles de millones de filas. Es importante considerar que el uso de almacenamiento columnar no es necesariamente la solución para todos los escenarios. En contextos de datos pequeños o donde la naturaleza de las operaciones es altamente transaccional, seguir utilizando almacenamiento basado en filas puede ser la opción más adecuada. La movida hacia columnar debería estar motivada por un análisis profundo del tipo de carga de trabajo, volumen de datos, patrones de consulta y costos asociados.