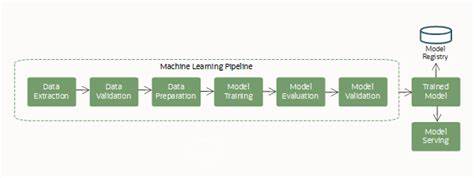
En el vertiginoso mundo de la inteligencia artificial y el aprendizaje automático, las pipelines de datos se han convertido en el corazón que impulsa la innovación. Sin embargo, a medida que la tecnología avanza y las expectativas crecen, también lo hacen los desafíos inherentes a la gestión eficiente de los datos. En 2025, estos retos son aún más palpables y afectan directamente el rendimiento y la efectividad de los modelos utilizados en distintos sectores. Uno de los principales dolores en la cadena de datos es la recolección. Conseguir grandes volúmenes de datos relevantes, de calidad y representativos sigue siendo una tarea titánica para muchas organizaciones.
En sectores como finanzas, salud o áreas multi-modales, la dificultad aumenta por razones que van desde la privacidad hasta la sensibilidad de la información. El acceso a fuentes confiables se ve obstaculizado por regulaciones estrictas y la escasez de datos etiquetados adecuados, lo que genera un cuello de botella que ralentiza la construcción de modelos robustos. La limpieza y preprocesamiento de datos es otro punto crucial que consume una gran parte del tiempo y recursos en las organizaciones. Datos inconsistentes, errores, valores faltantes o anomalías pueden dañar el entrenamiento y la capacidad predictiva de los algoritmos. En muchos casos, las herramientas automatizadas aún no son suficientemente maduras para resolver todos estos inconvenientes sin supervisión humana, haciendo que la intervención manual sea necesaria y, por ende, costosa y propensa a errores.
El etiquetado o labeling es quizás uno de los procesos más laboriosos y esenciales para modelos supervisados. Aunque la generación de datos sintéticos y técnicas avanzadas como el Reinforcement Learning with Human Feedback (RLHF) han emergido como soluciones prometedoras, no siempre logran reemplazar completamente la necesidad de datos frescos y contextuales. La calidad del etiquetado impacta directamente en la capacidad del modelo para generalizar y adaptarse a escenarios reales. Por tanto, contar con procesos de etiquetado eficientes y precisos es fundamental para el éxito de cualquier proyecto de inteligencia artificial. Un desafío adicional que afecta gravemente a los pipelines es la deriva o drift de datos.
Con entornos cambiantes, las características de los datos pueden sufrir modificaciones con el tiempo, lo que obliga a la recalibración constante de los modelos para evitar pérdidas en precisión y rendimiento. Esta necesidad de monitorización continua genera presión adicional en los equipos, que deben detectar a tiempo estas variaciones y actuar rápidamente para mantener la validez del modelo. El cumplimiento normativo y ético también se ha convertido en un aspecto clave en la gestión de datos para IA y ML. Legislaciones como GDPR, HIPAA y otras regulaciones locales demandan a las organizaciones mantener altos estándares de privacidad y seguridad. Esto complica la manipulación y almacenamiento de información, obligando a las empresas a implementar controles estrictos que garantizan la trazabilidad y protección de los datos sin sacrificar la calidad ni la agilidad en el procesamiento.
La automatización aparece como una esperanza para aliviar diferentes puntos críticos dentro de los pipelines. Sin embargo, identificar qué tareas deben automatizarse primero es un dilema constante. Actividades repetitivas y propensas a error humano, como la limpieza de datos y la detección de anomalías, suelen ser candidatas óptimas. No obstante, el alto grado de complejidad y especialización en la interpretación y contextualización de datos todavía requiere supervisión humana especializada, lo que limita la automatización completa. Sectores específicos enfrentan retos particulares.
En el área financiera, la dificultad para obtener datos verídicos y actualizados se combina con la obligación de cumplir regulaciones que restringen su uso. En salud, la sensibilidad de la información y la necesidad de anonimización complican la recolección y etiquetado, además de la gestión ética de datos. Las aplicaciones multi-modales, que integran texto, imágenes y audio, enfrentan el desafio de sincronizar y homogenizar datos heterogéneos, lo que demanda pipelines mucho más complejas y especializadas. Finalmente, la comunidad que trabaja en inteligencia artificial y machine learning está en constante búsqueda de soluciones que minimicen estos frenos en sus pipelines. La colaboración abierta, la adopción de herramientas avanzadas de etiquetado, el desarrollo de frameworks para la detección automática de drift y el impulso de la ética y la privacidad, son algunos de los enfoques prioritarios para construir un futuro en el que las pipelines de datos sean suficientemente robustas, eficientes y adaptables para enfrentar los desafíos del mañana y fomentar la innovación en todos los sectores.
En definitiva, los mayores problemas que enfrentan las pipelines de datos para IA y ML en 2025 abarcan desde la recolección hasta la monitorización continua, pasando por la limpieza, etiquetado, deriva y cumplimiento regulatorio. La comprensión profunda de estos puntos de dolor y el desarrollo de estrategias efectivas para mitigarlos representa un factor crítico para el éxito en la era de la inteligencia artificial.








