En el mundo actual donde los datos juegan un papel fundamental en la toma de decisiones y el desarrollo tecnológico, contar con herramientas que permitan generar datos sintéticos de calidad es esencial. Cuando se trata de probar sistemas de procesamiento de datos en tiempo real, aplicaciones de inteligencia artificial o simulaciones complejas, la necesidad de crear grandes volúmenes de datos confiables y fácilmente configurables se vuelve ineludible. En este contexto surge GlassGen, un generador de datos en streaming desarrollado en Python que ofrece una solución integral para la generación flexible, rápida y escalable de datos sintéticos, ideal para simular escenarios del mundo real. GlassGen se destaca por su capacidad para crear datos basados en esquemas definidos por el usuario, permitiendo una personalización profunda y adaptada a múltiples casos de uso. A través de una estructura simple pero poderosa, los usuarios pueden especificar qué tipo de datos necesitan generar y cómo desean gestionar su entrega.
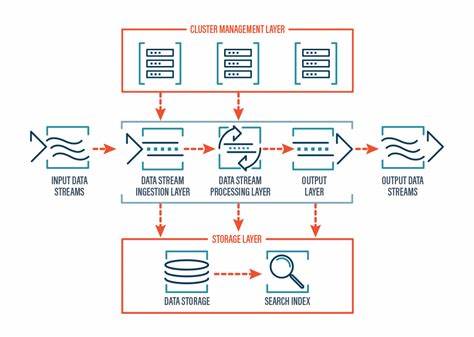
Esta herramienta es particularmente valiosa para desarrolladores, ingenieros de datos, analistas y empresas que necesitan validar sistemas en entornos controlados antes de su despliegue en producción. Una de las características más llamativas de GlassGen es su arquitectura extensible de 'sink' o destinos, que posibilita enviar los datos generados a diferentes plataformas o servicios. Ya sea que se quiera escribir la información en archivos CSV para análisis offline, enviar mensajes a un clúster Kafka para pruebas de streaming, o incluso notificar endpoints mediante webhooks, GlassGen ofrece soporte para todos estos métodos y posibilita la creación de destinos personalizados según las necesidades. Esta flexibilidad facilita su integración en diversos flujos de trabajo y sistemas existentes. Al hablar de generación de datos, la diversidad y variedad de la información es esencial para que las simulaciones sean representativas y realistas.
GlassGen incorpora un amplio catálogo de generadores de esquemas que pueden producir datos desde simples cadenas, enteros, fechas y booleanos hasta datos específicos como nombres, correos electrónicos, direcciones, números de teléfono, UUIDs y valores monetarios, entre otros. Además, ofrece soporte para formatos de fecha personalizados y rangos numéricos, lo que permite construir datasets detallados y adaptables. Un aspecto fundamental para usuarios avanzados es el soporte para la duplicación controlada de eventos. Esta función permite simular situaciones reales en las que ciertos eventos pueden generarse o procesarse múltiples veces, como sucede en entornos distribuidos o cuando existen errores de transmisión. GlassGen posibilita ajustar la proporción de duplicados, seleccionar campos clave para identificar eventos repetidos y definir ventanas de tiempo específicas.
Esta funcionalidad no solo mejora la calidad y realismo de las simulaciones, sino que también aporta mayor valor a las pruebas de tolerancia y recuperación de sistemas. El uso de GlassGen puede realizarse tanto desde la línea de comandos como mediante la interfaz SDK en Python, lo que facilita su incorporación en pipelines automatizados o su ejecución manual para generar datasets ad hoc. La instalación es sencilla, desarrollándose principalmente con la gestión de entornos virtuales y paquetes estándar de Python, lo que asegura compatibilidad y facilidad de mantenimiento. Para quienes buscan ejemplos prácticos, GlassGen proporciona configuraciones definidas que permiten comenzar rápidamente a generar datos. A través de archivos JSON configurables, es posible definir el esquema de los datos, el destino y parámetros como la tasa de generación y el número total de registros.
Esta simplicidad en la configuración abre la puerta a su uso por parte de usuarios con distintos niveles técnicos, sin sacrificar la complejidad que un entorno avanzado pueda demandar. Otra ventaja palpable de GlassGen radica en su diseño orientado a la eficiencia y responsabilidad con los recursos. Para evitar problemas de memoria y garantizar un rendimiento sostenido durante la generación continua de datos, dispone de mecanismos internos para limpiar y administrar eventos antiguos, especialmente en la función de duplicación, asegurando que la simulación no se vea afectada por acumulaciones o fugas. El soporte para Kafka como uno de sus destinos más robustos responde a la creciente adopción de esta plataforma en arquitecturas modernas basadas en eventos y procesamiento en tiempo real. Gracias al uso de la popular biblioteca confluent_kafka, GlassGen puede conectar con clústeres Kafka, incluyendo servicios gestionados en la nube, utilizando parámetros de configuración comunes que aseguran la seguridad y autenticación necesaria.
Esta capacidad convierte a GlassGen en una herramienta eficaz para probar y validar aplicaciones de streaming y arquitecturas event-driven. Los desarrolladores interesados en personalizar GlassGen pueden ir más allá de los esquemas y destinos predefinidos, extendiendo la clase base de destinos para implementar comportamientos específicos. Este enfoque modular y abierto favorece la innovación y la expansión del ecosistema, garantizando que la herramienta siga siendo relevante ante nuevas demandas y contextos. En el entorno actual donde el procesamiento de datos en tiempo real y la inteligencia artificial exigen datasets realistas y flexibles, contar con una herramienta como GlassGen es una ventaja competitiva. Su capacidad para producir datos personalizados, entregar en múltiples formatos y adaptarse a escenarios complejos lo convierten en un aliado imprescindible para quienes buscan robustez y versatilidad en la generación de datos sintéticos.
Por último, la comunidad de GlassGen ofrece documentación completa, ejemplos prácticos y un proceso de liberación continuo que asegura actualizaciones constantes y mejoras progresivas. Esto brinda confianza a los usuarios sobre la sostenibilidad y evolución del proyecto. En resumen, GlassGen es una solución integral para la generación de datos en streaming en Python, que combina potencia, flexibilidad y facilidad de uso, ideal para simular escenarios reales, realizar pruebas rigurosas y desarrollar aplicaciones basadas en datos con confianza y precisión.








