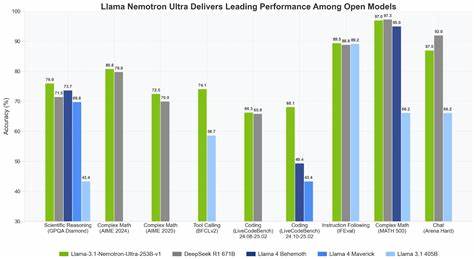
En el mundo vertiginoso de la inteligencia artificial, la capacidad de razonamiento eficiente es una cualidad cada vez más demandada para resolver problemas complejos y mejorar la interacción con máquinas inteligentes. Llama-Nemotron surge como una respuesta avanzada e innovadora a esta necesidad, ofreciendo una serie de modelos que combinan robustez, velocidad y flexibilidad, y que además cuentan con una licencia abierta para su uso en entornos empresariales. Llama-Nemotron representa un hito significativo en el desarrollo de sistemas de razonamiento basado en redes neuronales. Presentado en 2025, este conjunto de modelos se compone de tres variantes principales: Nano, Super y Ultra, que abarcan desde 8 mil millones hasta 253 mil millones de parámetros. Esta diversidad en tamaño y capacidad permite a los usuarios elegir el modelo que mejor se adapta a sus recursos y necesidades, manteniendo siempre un rendimiento competitivo frente a otros modelos punteros en el campo, como DeepSeek-R1.
Una de las grandes innovaciones que ofrece Llama-Nemotron es su enfoque en la eficiencia tanto en la inferencia como en el uso de memoria, superando a numerosos competidores en el mercado. Esto es crucial, ya que los modelos de inteligencia artificial a gran escala suelen requerir vastos recursos computacionales, lo que limita su accesibilidad y aplicabilidad práctica. Gracias a avances en la arquitectura y a procesos de optimización, Llama-Nemotron reduce significativamente esta barrera, ayudando a democratizar el acceso a tecnologías de IA potentes. El desarrollo de Llama-Nemotron se apoya en técnicas avanzadas, entre ellas la búsqueda de arquitectura neuronal (Neural Architecture Search, NAS), que permite mejorar la estructura interna del modelo basada en la eficiencia de inferencia. Esta estrategia parte de la base de Llama 3, otro modelo reconocido, y lo lleva a otro nivel con optimizaciones que aceleran su funcionamiento sin sacrificar la precisión.
Otro pilar fundamental es el proceso de entrenamiento que abarca varias fases complejas y complementarias. Inicia con la destilación de conocimiento, una técnica mediante la cual un modelo grande y costoso enseña a uno más pequeño y eficiente hasta lograr un equilibrio ideal entre capacidad y rapidez. Seguidamente, se realiza un preentrenamiento continuo para reforzar el aprendizaje previo y adaptar el modelo a tareas específicas que requieren razonamiento sofisticado. Finalmente, este ciclo de entrenamiento contempla una etapa dedicada a mejorar las habilidades de razonamiento mediante afinamiento supervisado y aprendizaje por refuerzo a gran escala. Este último es especialmente relevante, ya que permite al modelo ajustar sus respuestas según recompensas obtenidas en tareas específicas, promoviendo comportamientos más inteligentes y ajustados a diferentes contextos.
Una característica innovadora y de suma utilidad en Llama-Nemotron es el llamado “dynamic reasoning toggle”, un mecanismo que permite alternar en tiempo real entre un modo de chat estándar y uno centrado en el razonamiento avanzado durante la inferencia. Esto significa que los usuarios pueden adaptar el desempeño del modelo según las circunstancias, optimizando recursos y obteniendo resultados más coherentes cuando la complejidad de la tarea lo demande. Además de ofrecer potentes herramientas en sí, el equipo detrás de Llama-Nemotron ha puesto un fuerte énfasis en la comunidad investigadora y desarrolladora. Han liberado no solo los modelos LN-Nano, LN-Super y LN-Ultra bajo una licencia comercialmente permisiva (NVIDIA Open Model License), sino también el conjunto completo de datos utilizados en la última fase de entrenamiento, conocido como Llama-Nemotron-Post-Training-Dataset. Adicionalmente, han compartido las bases de código para entrenamiento y alineamiento: NeMo, NeMo-Aligner y Megatron-LM, que son recursos fundamentales para quienes desean desarrollar, adaptar o mejorar estos modelos.
Esto potencia la transparencia, la colaboración abierta y acelera la innovación en el campo de las tecnologías de razonamiento automático. La importancia de Llama-Nemotron radica también en su impacto potencial sobre múltiples industrias. El razonamiento eficiente es crucial en sectores como la atención al cliente mediante chatbots inteligentes, la investigación científica asistida por IA, la toma de decisiones automatizada en finanzas, la medicina para el análisis de datos complejos o la educación personalizada. La capacidad para alternar entre modos de respuesta abre un abanico de posibilidades para aplicaciones dinámicas que pueden ajustarse en tiempo real a las necesidades del usuario. Respecto a su comparación con otros modelos reconocidos, Llama-Nemotron ofrece un incomparable equilibrio entre tamaño, costo y rendimiento.
Modelos gigantes como GPT-4 o sus equivalentes suelen requerir infraestructuras elevadas y licencias restrictivas, mientras que Llama-Nemotron, con su abanico de tamaños y código abierto, impulsa la adopción más amplia y flexible. La estrategia de combinar Neural Architecture Search, destilación de conocimiento, preentrenamiento continuado y aprendizaje por refuerzo en sus distintas fases de postentrenamiento es un modelo de referencia para futuros desarrollos en inteligencia artificial. Este pipeline integral posibilita alcanzar niveles de razonamiento avanzado sin sacrificar la eficiencia, un punto clave ante la creciente demanda global de sistemas IA prácticos y flexibles. En definitiva, Llama-Nemotron representa un paso ambicioso y acertado hacia la democratización del razonamiento automático eficiente. Su enfoque holístico sobre arquitectura, entrenamiento y licenciamiento abierto posiciona a esta serie como un recurso invaluable tanto para investigadores, desarrolladores y empresas de todos los tamaños.
En un futuro próximo, la evolución y adopción de modelos similares harán que la inteligencia artificial no solo sea más accesible, sino también más útil y adaptativa, permitiendo resolver problemas antes inimaginables en menor tiempo y con mayor precisión. Llama-Nemotron, por sus innovaciones y visión abierta, resulta un protagonista destacado en esta nueva era de razonamiento por inteligencia artificial.