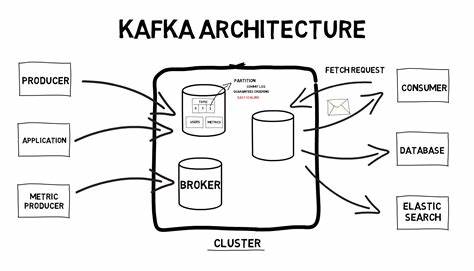
Apache Kafka se ha consolidado como una de las tecnologías más importantes para el movimiento y procesamiento de grandes volúmenes de datos en tiempo real. Su éxito radica en una arquitectura robusta, enfocada en la escalabilidad, durabilidad y capacidad de reproducir mensajes, esenciales para aplicaciones modernas que requieren un manejo ágil y seguro de la información. Explorar el código fuente y el diseño interno de Kafka permite entender cómo combina ingeniería avanzada y conceptos fundamentales para lograr su rendimiento excepcional. Para iniciar, es crucial conocer los tres actores principales en el ecosistema Kafka: brokers, productores y consumidores. Los brokers son servidores dedicados que aceptan solicitudes de producción y consumo de mensajes.
Organizan los datos en logs distribuidos y replicados en múltiples nodos, garantizando la disponibilidad y resistencia ante fallos. Los productores son aplicaciones, generalmente Java pero no exclusivamente, que envían mensajes a los brokers mediante un protocolo TCP propio. Estos mensajes se almacenan divididos en temas separados por particiones, lo que permite repartir la carga y escalar el sistema. Los consumidores, por su parte, consultan los datos almacenados por los brokers de forma ordenada. Su diseño favorece la idempotencia y la capacidad de relectura, características que facilitan la construcción de sistemas tolerantes a fallos y con control preciso del flujo de información.
La comunicación entre estos componentes se encuentra centrada en un protocolo TCP optimizado, manejado mediante canales no bloqueantes que aprovechan las capacidades de Java NIO para una gestión eficiente de múltiples conexiones simultáneas. El punto de entrada para iniciar un broker es indirecto, comenzando con el script kafka-server-start.sh, que a su vez invoca kafka-run-class.sh para ejecutar la clase principal kafka.Kafka.
Este proceso es un programa Java tradicional, aunque equipado con configuraciones específicas que ajustan la memoria, el recolector de basura y otros aspectos del runtime para optimizar el desempeño de Kafka. Al profundizar en el código, la principal función va creando una instancia del servidor basada en la configuración recibida. Aquí es donde se define si Kafka utilizará Zookeeper para su coordinación o si funcionará con el nuevo método KRaft, que reemplaza la necesidad de Zookeeper con un enfoque propio basado en el algoritmo de consenso Raft. Esta evolución es crucial para escalar Kafka, ya que elimina dependencias externas y mejora la eficiencia en la gestión del estado del clúster. Históricamente, Kafka dependió de Zookeeper para almacenar su metadatos, tales como el estado de los brokers, temas y particiones.
Zookeeper funciona como un sistema de archivos jerárquico remoto donde Kafka crea nodos especiales (znodes) para mantener esta información y sus cambios son anunciados a los clientes mediante mecanismos de watch, permitiendo una sincronización casi instantánea entre todos los brokers del clúster. La migración hacia KRaft responde a la necesidad de reducir la complejidad operativa y eliminar un cuello de botella ocasionado por la carga que Zookeeper representaba en clusters muy grandes, con cientos de miles de particiones. Mediante la integración de un controlador nativo que emplea Raft para el consenso, Kafka gana en simplicidad, rendimiento y escalabilidad, además de reducir la curva de aprendizaje para sus usuarios. El manejo de la red en Kafka es otro de los aspectos fascinantes en su código. Para mantener un rendimiento óptimo frente a miles de conexiones simultáneas, Kafka utiliza un modelo basado en threads específicos llamados Acceptors, Processors y Handlers.
Un thread Acceptor se encarga de aceptar nuevas conexiones TCP en los diversos puertos configurados, mientras que los Processors gestionan la lectura no bloqueante a través de Selectors de Java NIO, y los Handlers procesan las solicitudes específicas como envíos o consumos de mensajes. Esta arquitectura puede compararse con un sistema de producción en cadena donde cada parte tiene una función clara y sucede en paralelo, maximizando el throughput y minimizando la latencia. Las conexiones se registran y gestionan mediante colas de bloqueos que evitan sobrecargar el sistema, así como identificadores únicos para cada conexión que permiten trazar su actividad y diagnosticar problemas en tiempo real. Cuando se explora el almacenamiento, se puede apreciar cómo Kafka utiliza un sistema eficiente basado en logs segmentados que se desglosan en archivos físicos almacenados en el disco duro. Cada partición de un tema corresponde a un directorio que alberga múltiples archivos: los logs con los datos reales, los índices de offset que mapean los mensajes a posiciones específicas en archivo y los índices de tiempo que permiten búsquedas basadas en marcas temporales.
Estos índices se cargan en memoria mediante mmap, una llamada al sistema de Linux que mapea archivos directamente en la memoria, lo que acelera enormemente las operaciones de búsqueda y acceso sin incrementar significativamente la carga de I/O. Kafka escribe registros primero en memoria y solamente los sincroniza con el disco en intervalos definidos, un diseño que balancea rendimiento con durabilidad. La clase LogManager tiene un papel fundamental facilitando la creación, recuperación y mantenimiento de estos logs. En su inicio, ejecuta tareas programadas para limpiar logs antiguos, compactar información y realizar flushes que garantizan que los datos en memoria se persistan adecuadamente. Estas tareas ayudan a mantener el buen estado del sistema durante su operación continua.
Para añadir un mensaje a un log, Kafka sigue una ruta bien definida: desde que el handler detecta una solicitud Produce, pasa a manejar la inserción en la cola correspondiente, y llama a métodos especializados que agregan la información al segmento activo. Esta operación se descompone en varias capas, desde UnifiedLog a LocalLog, y finalmente al objeto LogSegment que interactúa con los archivos de disco. Es interesante destacar cómo Kafka utiliza algoritmos clásicos como la búsqueda binaria para encontrar rápidamente las posiciones adecuadas dentro de los índices de offsets o tiempo. Esto demuestra una combinación acertada entre complejas abstracciones de alto nivel y el aprovechamiento de herramientas y datos fundamentales del sistema operativo y la JVM. En definitiva, el código de Kafka está construido sobre sólidos bloques de construcción de Java, como canales de archivos, buffers mapeados y estructuras concurrentes.