En el desarrollo de software moderno, la combinación de lenguajes como Go y C es común para aprovechar la eficiencia, funcionalidad y ecosistemas diversos. Especialmente en sistemas que manejan grandes volúmenes de datos o que requieren alta concurrencia, como consumidores o productores de Kafka, Go ha ganado gran popularidad. Sin embargo, integrar código en C dentro de aplicaciones Go puede introducir desafíos importantes, además de los propios del desarrollo, especialmente en cuanto a la gestión eficiente de la memoria. Un caso muy ilustrativo se dio en un equipo de ingeniería de Zendesk, que enfrentó una fuga de memoria persistente en una aplicación Go que utilizaba la biblioteca Confluent Kafka, basada en librdkafka escrita en C, integrándose mediante la herramienta cgo. Esta experiencia destaca el detalle y la complejidad necesaria para detectar y resolver problemas de memoria cuando el problema radica en la interacción entre Go y C.
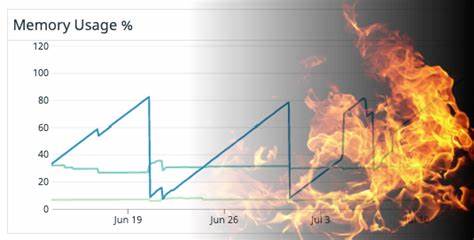
A simple vista, observar un incremento lineal de memoria en el sistema operativo era un síntoma preocupante que indicaba una probable fuga de memoria. Esto se manifestaba en gráficos donde el consumo de memoria aumentaba constantemente durante la ejecución del programa, seguido de caídas abruptas causadas por despliegues o la activación del OOM Killer en Linux, termómetro claro de un problema grave. Lo primero fue determinar si el problema provenía del lado del código Go o del código C. Gracias a las métricas internas que Go ofrece, específicamente las memstats, se pudo notar que no había un incremento acorde en la memoria asignada y gestionada por Go. La memoria residente aumentaba, pero Go no reportaba incremento en asignaciones, por lo que elegían enfocarse en la parte C, el librdkafka, como origen probable.
Antes de asumir una fuga, se deben entender posibles causas alternativas como la fragmentación de memoria o el comportamiento perezoso del kernel Linux que puede retrasar la recuperación de memoria, haciendo que la aplicación parezca consumir más memoria de la que realmente usa. Para profundizar en la fuente real se incluyó la biblioteca jemalloc, que reemplaza al malloc estándar en C y ofrece métricas detalladas sobre la memoria activa y asignada, facilitando un diagnóstico más certero. La confirmación llegó cuando los valores reportados por jemalloc coincidieron con el incremento en memoria residente del sistema operativo, dando la certeza de que efectivamente se trataba de una fuga real de memoria originada en la parte C. A continuación, para identificar en detalle dónde ocurrían los leaks, se buscó usar Valgrind, un clásico en la detección de errores de memoria en programas C. Valgrind envuelve la ejecución y analiza cada llamada a malloc y free en tiempo real para detectar fugas, accesos inválidos y otros problemas relacionados.
Sin embargo, al ejecutarlo en el contenedor que corría la aplicación Go, se descubrió que el reporte de fugas era minimalista y no explicaba el tamaño real de la memoria perdida, mostrándose memoria estática inicializada por librerías como OpenSSL, que no representan una fuga dinámica continua. Esto indicaba dos posibles escenarios: que la memoria perdida usara métodos de asignación que Valgrind no intercepta (como mmap anónimo, que no era el caso) o que la aplicación en efecto estaba gestionando la liberación de memoria, pero acumulaba tantas asignaciones sin procesarlas (por ejemplo, poblando una cola interna) que el consumo crecía sin cesar aunque al finalizar la app la memoria era liberada. Esta última hipótesis era más probable. Investigando más a fondo, el equipo decidió sacar provecho de las tecnologías basadas en el kernel Linux, como eBPF y perf_events, que permiten instrumentar métricas y rastrear eventos con una sobrecarga muy baja. Una herramienta poderosa que facilita este trabajo es bpftrace, un lenguaje y entorno para escribir programas eBPF que pueden monitorizar funciones específicas y recolectar información de bajo nivel sin detener la aplicación.
En este caso, se modificó librdkafka para incluir puntos de rastreo (USDT probes) en las funciones de asignación y liberación de memoria típicas como rd_malloc y rd_free. Estas modificaciones compilan normalmente a instrucciones nulas (nop) sin impacto en producción, pero permiten enganchar funciones de eBPF cuando se activa el tracing. Para obtener datos útiles, se añadió la opción de compilación -fno-omit-frame-pointer que preserva la información del puntero de pila, necesaria para poder obtener trazas de llamada (stacks) claras y precisas. Con estas herramientas listas, el equipo implementó un programa bpftrace que en cada llamada a rd_malloc almacenaba la dirección de memoria asignada y la pila de llamadas, y que en cada rd_free eliminaba la referencia. Esto permitía mapear en tiempo real cuáles asignaciones no habían sido liberadas y rastrear su origen de manera dinámica en producción, una mejora abismal respecto a pruebas post-mortem con Valgrind.
Ejecutar bpftrace dentro de contenedores de Kubernetes a veces presenta dificultades técnicas. El principal obstáculo es que bpftrace necesita acceso a los encabezados del kernel compatible con la versión del kernel que realmente ejecuta el nodo, que puede diferir del sistema base de la imagen del contenedor. En este caso, la solución fue cargar el módulo kheaders en el nodo Kubernetes para exponer el paquete de encabezados en un archivo accesible desde los contenedores. También fue necesario dotar al contenedor con privilegios elevados para permitir la carga de programas eBPF desde dentro. Los resultados fueron reveladores.
Se obtuvo el conjunto de pilas de llamadas responsables de asignaciones sin liberar, lo que permitió identificar rápidamente que la fuga estaba relacionada con eventos específicos de librdkafka, de tipo OffsetCommitResponse, que eran puestos en cola pero nunca consumidos ni descartados. Así, la memoria se acumulaba en la cola sin límite, aumentando la huella de memoria. La solución consistió en consumir activamente los eventos generados por librdkafka para evitar que esa cola creciera infinitamente. Implementar un consumo que descartara o gestionara esos eventos no deseados fue una modificación muy sencilla, que de inmediato estabilizó el uso de memoria. Este caso da varias lecciones valiosas.
La primera es la importancia de entender la arquitectura y comportamiento de todas las partes implicadas cuando se trabaja con programas híbridos en Go y C, dado que problemas originados en el nivel C suelen ser difíciles de detectar mediante herramientas tradicionales de Go. Además, aprender y utilizar herramientas modernas como bpftrace y eBPF puede acelerar y mejorar de forma exponencial la calidad del diagnóstico comparado con técnicas convencionales. Otro aprendizaje fundamental es el riesgo de mantener colas sin límites en memoria para esperar eventos o mensajes sin procesar, especialmente en sistemas de alto rendimiento o producción. Medidas apropiadas incluyen límites en el tamaño de cola o mecanismos de descarte con alertas para evitar escaladas inesperadas de consumo de recursos. Finalmente, este episodio subraya la relevancia de fomentar en las organizaciones ambientes que permiten invertir tiempo en diagnósticos profundos y formación en nuevas técnicas y herramientas, lo que a largo plazo impacta positivamente en la robustez y confiabilidad de los sistemas.
En conjunto, esta experiencia ofrece una guía sobre cómo abordar problemas complejos de memoria en aplicaciones híbridas, integrando tecnologías emergentes e impulsando una cultura de ingeniería sólida y proactiva.