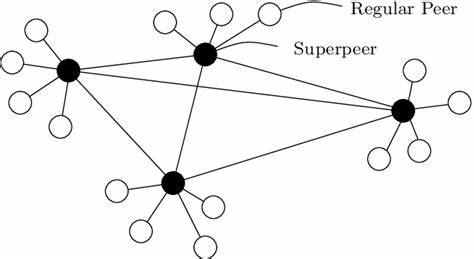
En la era actual, la inteligencia artificial (IA) está experimentando una transformación profunda, impulsada por modelos cada vez más grandes y potentes que requieren una operación eficiente y escalable. La inferencia, es decir, la capacidad de un modelo de IA para generar respuestas o ejecutar tareas en tiempo real, ha pasado a ser el núcleo del ecosistema de IA. Sin embargo, el enfoque tradicional para ejecutar esta inferencia se enfrenta a grandes desafíos, como la necesidad de hardware especializado y centros de datos centralizados que controlan el acceso a la tecnología. En este contexto surge la inferencia descentralizada peer-to-peer (P2P), un paradigma innovador que promete democratizar y distribuir la capacidad de ejecutar modelos de inteligencia artificial complejos utilizando hardware de consumo común y redes públicas de alta latencia. Esta revolución tecnológica está en camino de redefinir la forma en que accedemos y contribuimos al poder computacional global para IA, llevando la ejecución de modelos a escala planetaria.
El concepto central de la inferencia descentralizada P2P es simple, pero poderoso: en lugar de depender de grandes servidores centralizados o clusters de hardware especializado, la inferencia se reparte entre una red de dispositivos individuales interconectados. Cada nodo en esta red contribuye con su propia unidad gráfica (GPU) —a menudo hardware accesible para consumidores comunes— para participar en la ejecución de tareas de inferencia. Así, se aprovechan los recursos latentes, muchas veces subutilizados, presentes en millones de computadoras alrededor del mundo. Pero aunque la idea es clara, llevarla a la práctica supone superar retos técnicos complejos relacionados con la latencia en la comunicación, la sincronización entre dispositivos y las limitaciones de memoria durante el procesamiento. Uno de los principales retos que enfrenta la inferencia descentralizada es la latencia inherente a las redes públicas, que pueden tener demoras de hasta 100 milisegundos o más entre dispositivos.
En sistemas centralizados, estas latencias son mínimas, lo que permite una comunicación rápida y fluida entre unidades computacionales. Sin embargo, cuando la inferencia ocurre en nodos distribuidos geográficamente, los retrasos en la transferencia de datos pueden provocar periodos prolongados donde partes críticas del sistema quedan inactivas, afectando la eficiencia general del proceso. Para mitigar estos efectos, el diseño ha privilegiado un tipo de paralelismo llamado paralelismo de pipeline, donde cada nodo procesa una parte secuencial del modelo en un flujo sincronizado. Aunque este enfoque reduce la necesidad de comunicación constante, introduce el problema del tiempo muerto o idle time en las GPUs, ya que los nodos deben esperar a que otros terminen antes de continuar, lo que limita la ganancia en rendimiento esperada. Otra dificultad esencial está relacionada con la cantidad de memoria necesaria para almacenar el KV cache, que es la memoria donde se guardan las claves y valores utilizados en las operaciones de auto-atención durante la inferencia de modelos de lenguaje.
Este caché crece conforme se procesan más secuencias en paralelo, imponiendo un límite estricto en la cantidad de datos que puede manejar cada GPU. Así, aunque existan múltiples nodos para distribuir la carga, el tamaño del batch que puede procesarse simultáneamente está restringido por la capacidad de memoria, lo que también afecta el rendimiento y la escalabilidad. Desde el punto de vista técnico, la inferencia en un solo acelerador obtiene su rendimiento ideal cuando está limitada principalmente por la capacidad de cómputo (compute-bound), en lugar de por la velocidad con que puede acceder o trasladar la memoria (memory bandwidth-bound). Sin embargo, en la práctica, durante la fase de decodificación auto-regresiva en modelos de lenguaje, se observa que la operación está principalmente limitada por el ancho de banda de memoria debido a la gestión del KV cache y otros factores relacionados. Esto significa que las GPUs pasan más tiempo moviendo datos que calculando, una ineficiencia que es crucial entender para diseñar sistemas descentralizados efectivos.
En cuanto a los métodos de paralelización utilizados para manejar modelos extremadamente grandes, existen principalmente dos enfoques: paralelismo por tensor y paralelismo por pipeline. El paralelismo por tensor involucra dividir las matrices de peso del modelo entre múltiples dispositivos, requiriendo comunicación sincronizada constante durante el cálculo. Por otro lado, el paralelismo por pipeline distribuye capas completas del modelo a diferentes nodos, procesando los datos secuencialmente. El paralelismo pipeline es preferido en entornos descentralizados debido a que genera menor comunicación en red, aunque introduce el desafío de la latencia que ya mencionamos. Para enfrentar las limitaciones de la implementación síncrona, se han desarrollado técnicas de ejecución asincrónica con micro-batches, que permiten que diferentes dispositivos procesen pequeñas porciones de datos de manera independiente y paralela.
Sin embargo, en el contexto de inferencia, donde predominan las limitaciones de memoria y el ancho de banda, este enfoque no genera las mejoras de desempeño que sí se observan en entrenamiento de modelos, por ejemplo. La razón es que el tiempo para procesar una micro porción de datos y para una porción completa es aproximadamente el mismo, eliminando el beneficio esperado de paralelizar más finamente la carga. En consecuencia, para lograr avances significativos hacia un sistema global descentralizado de inferencia que funcione sobre redes públicas con alta latencia y hardware heterogéneo, es necesario replantear la arquitectura y los algoritmos de ejecución. Esto implica trasladar gradualmente parte del trabajo desde operaciones intensivas en memoria hacia operaciones más intensivas en cómputo, aprovechando los tiempos muertos creados por las latencias de red para realizar cálculos adicionales y mejorar la utilización del hardware. También se requieren técnicas innovadoras para reducir el requerimiento de memoria, incluyendo formas inteligentes de cachear o recomputar partes del modelo para liberar espacio sin sacrificar precisión ni velocidad.
El futuro de la inferencia descentralizada pasa por protocolos y arquitecturas flexibles que permitan manejar variabilidad en la disponibilidad, latencia y ancho de banda de nodos participantes. Estos protocolos deberán gestionar de forma robusta la ejecución asincrónica, verificando la validez y seguridad de las operaciones distribuidas, asegurando que múltiples contribuyentes puedan colaborar sin comprometer la integridad del modelo o los resultados. Más allá del ámbito puramente técnico, la inferencia descentralizada peer-to-peer tiene un impacto potencial enorme en el acceso y propiedad de la inteligencia artificial. Al abrir la capacidad de cómputo y ejecución de IA a cualquier persona que posea hardware común —sin depender de grandes corporaciones con centros de datos especializados— se fomenta un ecosistema más democrático y distribuido. Esto puede acelerar la innovación, disminuir costos y ampliar el alcance de aplicaciones inteligentes para comunidades y países con menor infraestructura tecnológica.
Además, esta descentralización es fundamental en la visión de un futuro de inteligencia artificial general abierta y soberana, donde la colaboración global y la contribución colectiva son la base para construir sistemas de conocimiento y razonamiento más completos y confiables. La capacidad de entrenar, evaluar y ejecutar modelos a escala planetaria, sin depender de un punto único de control, puede también incrementar la resiliencia y seguridad del ecosistema de IA frente a ataques o fallos. Las primeras implementaciones y lanzamientos de código abierto orientados a esta tecnología ya están disponibles, ofreciendo herramientas como un backend de comunicación P2P optimizado para paralelismo pipeline, integraciones que permiten ejecutar estas arquitecturas sobre redes públicas y entornos de experimentación para validar ideas innovadoras en cache y programación de pipelines. Estas iniciativas permiten a desarrolladores y entusiastas probar y contribuir al desarrollo de un stack completo que hará posible la inferencia descentralizada a gran escala. En conclusión, la inferencia descentralizada peer-to-peer representa uno de los avances más prometedores para escalar la inteligencia artificial fuera de los confines de grandes datacenters, abriendo camino hacia un modelo más accesible, eficiente y global.
A medida que la investigación y el desarrollo continúen, superando los desafíos de latencia, memoria y sincronización, este paradigma tendrá el potencial de transformar no solo la forma en que las máquinas piensan, sino también quién puede formar parte de ese proceso.




![Ask HN: Why are startups suddenly branding themselves the "OS" for [thing]?](/images/0881F9D9-0408-4826-A3D3-34D3531650EE)

![Research paper: removing dependencies from large (Java) software projects [pdf]](/images/CA6A366B-ED3A-479C-881E-376A20AAAB68)
