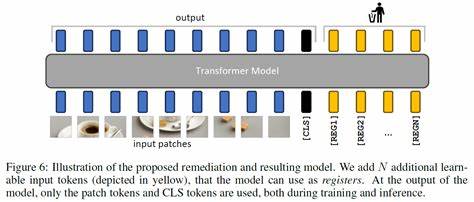
Los Vision Transformers, abreviados comúnmente como ViT, han revolucionado el campo del aprendizaje profundo, especialmente en el área de la visión por computadora. Estos modelos, basados en la arquitectura Transformer originalmente diseñada para tareas de procesamiento de lenguaje natural, han sido adaptados para analizar imágenes con gran éxito, superando en muchos casos a las redes neuronales convolucionales tradicionales. Sin embargo, como cualquier innovación tecnológica, su implementación práctica revela ciertos desafíos, entre ellos la aparición de artefactos en los mapas de características durante la inferencia, que pueden afectar negativamente la calidad de las representaciones visuales obtenidas. El problema central radica en la aparición de tokens con norma alta en áreas de la imagen consideradas poco informativas, usualmente fondos uniformes o poco relevantes. Estos tokens actúan como receptores internos de información que, aunque no aportan contenido visual significativo, son reutilizados en el proceso computacional dentro del Transformer.
En otras palabras, el modelo genera y manipula regiones fantasma de la información visual que no corresponden directamente con los elementos importantes de la imagen. Esta situación provoca mapas de activación poco suaves y puede interferir con el desempeño del modelo en tareas posteriores como detección de objetos, segmentación o reconocimiento. Ante esta problemática, investigadores en el campo de la visión por computadora han propuesto una solución innovadora basada en la incorporación de tokens adicionales, conocidos como "registros", en la secuencia de entrada del Vision Transformer. Estos registros funcionan como espacios designados para acoger las operaciones internas que de otro modo serían asignadas a esos tokens de alto valor aberrantes, básicamente disciplinando la forma en que el modelo utiliza sus representaciones. La implementación de estos registros consigue un efecto doble: primero, realmente corrige la generación de artefactos al evitar que los tokens destinados a cubrir áreas poco informativas sobresalgan en la inferencia.
Segundo, aporta una mayor estabilidad y suavidad a los mapas de características y a las distribuciones de atención que el modelo produce, permitiendo que los procesos de análisis visual sean más precisos y estables. Esto resulta especialmente valioso en métodos de aprendizaje auto supervisado, donde el modelo debe descubrir patrones y relaciones sin depender de etiquetas explícitas, elevando así el desempeño en tareas de predicción visual densa. Además, la inclusión de estos registros abre la puerta a la utilización de modelos Vision Transformers de mayor escala en técnicas de descubrimiento y segmentación de objetos, un aspecto que hasta ahora presentaba limitaciones por la complejidad computacional y la sensibilidad a los artefactos. Esta innovación permite manejar mejor el flujo de información y mejora la generalización del modelo a través de diferentes escenarios visuales, desde imágenes naturales a contextos más estructurados. En paralelo, los resultados experimentales han demostrado que este enfoque no solo mejora la calidad interna del modelo, sino también su rendimiento en benchmarks estándares, posicionando a los Vision Transformers equipados con registros a la vanguardia del aprendizaje visual auto supervisado.
Tal avance tiene implicaciones directas para la comunidad científica y la industria, favoreciendo la creación de sistemas inteligentes con mayor interpretación visual, mejor eficiencia y mayor capacidad de adaptación a contextos complejos. La importancia de este avance radica también en la simplicidad de su implementación. Añadir tokens de registro a la entrada del Transformer no requiere modificar sustancialmente la arquitectura ni incrementar considerablemente el costo computacional, facilitando así su adopción en distintos proyectos y plataformas sin necesidad de rediseños profundos o recursos desmesurados. En conclusión, los Vision Transformers necesitan registros para corregir un problema fundamental de manejo interno de información que afecta su rendimiento visual. Estos registros actúan como una especie de memoria auxiliar que mejora la organización de los datos procesados dentro del modelo, mitigando la influencia de artefactos no deseados.
Esta solución representa un progreso relevante en la mejora continua de los modelos de visión artificial, facilitando el camino hacia sistemas cada vez más potentes, robustos y aplicables a una amplia variedad de tareas en la inteligencia artificial moderna. A medida que esta línea de investigación avanza, se espera que su integración sea estándar en arquitecturas futuras, produciendo un impacto significativo en la calidad y capacidad de los sistemas basados en Transformers para el procesamiento visual.