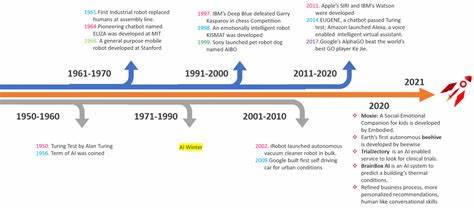
La inteligencia artificial (IA) ha experimentado un crecimiento exponencial en los últimos años, revolucionando la forma en que interactuamos con la tecnología y transformando múltiples sectores a nivel global. Desde 2022 hasta la fecha, una serie de hitos significativos ha marcado esta evolución, reflejando un constante avance en capacidades, diversidad de aplicaciones y apertura de modelos al público y a la investigación. Este recorrido detallado permite comprender cómo la IA ha pasado de ser una mera herramienta experimental a convertirse en un actor esencial para la innovación tecnológica actual. En 2022, el mundo fue testigo del lanzamiento de importantes versiones de generadores de imágenes y modelos de lenguaje. Midjourney lanzó varias actualizaciones de su plataforma, desde la versión 1 hasta la 4, y Stable Diffusion emergió como un competidor destacado con las liberaciones de sus versiones 1.
4, 1.5 y 2.0. Entre los lanzamientos más sonados se encuentra ChatGPT, el chatbot basado en GPT-3.5 creado por OpenAI, que rápidamente capturó la atención pública y se volvió viral gracias a su capacidad para comprender y responder en lenguaje natural con notable precisión y fluidez.
A principios de 2023 siguieron avances impresionantes. Meta lanzó la serie de modelos LLaMA como código abierto para investigación, una movida significativa que abrió las puertas a la comunidad para experimentar y mejorar las arquitecturas de lenguaje grandes. Microsoft introdujo Bing AI, incrementando su apuesta por integrar modelos de lenguaje compatibles con internet para ofrecer búsquedas inteligentes y conversacionales. OpenAI sacó parcialmente a la luz GPT-4, una versión multimodal con análisis de imágenes y soporte multilingüe, mostrando un salto cualitativo en la comprensión y generación de contenido por parte de la IA. Google, por su parte, lanzó Bard basado en el modelo LaMDA, ampliando el abanico de asistentes conversacionales con funciones avanzadas de diálogo.
Adobe, reconocida empresa de software creativo, entró en el juego con Firefly, un modelo enfocado en la creación de imágenes con técnicas innovadoras de texto a imagen, mostrando la convergencia entre IA y diseño gráfico. Durante la primavera y verano de 2023, Midjourney actualizó su plataforma a la versión 5.2 y Stable Diffusion presentó el modelo XL 1.0, mejorando la calidad, rapidez y versatilidad en generación de gráficos. Anthropic lanzó Claude 2, otro modelo de lenguaje grande, que junto con la publicación abierta de LLaMA 2 por parte de Meta en diversas escalas, fortaleció la competencia en el campo de la NLP (procesamiento del lenguaje natural).
A finales de año, DALL-E 3 y Firefly 2 marcaron hitos en generación de imágenes, mientras Midjourney continuaba perfeccionando su versión 6 con mejoras sustanciales en detalle y realismo. El 2024 ha estado caracterizado por una aceleración en la sofisticación de modelos y su accesibilidad. Stability AI anunció Stable Diffusion 3, liberado gradualmente, posicionándose como un referente para crear imágenes con mayor resolución y rapidez. Google transformó Bard en Gemini, consolidando su lenguaje multimodal Gemini Pro 1.5 con capacidad para procesar hasta un millón de tokens y manejar videos e imágenes, ampliando el espectro de la inteligencia artificial más allá del texto.
OpenAI también incrementó sus apuestas con el anuncio del modelo Sora, orientado a la generación de videos cortos que no se liberó al público de inmediato pero que anticipa un futuro en el que la IA podrá producir contenido audiovisual complejo de forma autónoma. Empresas emergentes como Reka AI y Suno AI avanzaron en modelos multimodales y generadores de música respectivamente, demostrando que la diversidad de aplicaciones se intensifica día a día. Abril y mayo de 2024 trajeron innovaciones en modelos mucho más livianos y optimizados para dispositivos móviles, como Phi-3-mini de Microsoft o OpenELM de Apple, democratizando el acceso a la IA de alto rendimiento. La competencia también se refleja en la variedad de modelos abiertos lanzados por Mistral AI, quienes desarrollaron Mixtral 8x22B, el modelo abierto más potente en su momento, además de Claude 3 y su nueva versión con capacidades mejoradas y dimensiones que superan las de GPT-4. Los avances en generación de texto, imagen y video fueron acompañados por innovaciones metodológicas, como la integración de contextos enormes de hasta millones de tokens, permitiendo conversaciones y análisis mucho más extensos y coherentes.
OpenAI, Google y empresas como DeepSeekAI avanzaron en la apertura y mejora de modelos con capacidades multimodales complejas. El medio año y el tercer trimestre de 2024 consolidaron la competencia con lanzamientos como GPT-4o, un modelo multimedial capaz de procesar audio, imagen y texto con gran eficiencia y velocidad, además de Gemini Flash y updates experimentales para potenciar la capacidad de razonamiento, contexto y eficiencia. Los video generadores también dieron un salto importante, con Runway, Google, Adobe, Meta y startups como Pika Labs lanzando versiones avanzadas que permiten videos de alta calidad en tiempo real. La carrera por la miniaturización y eficiencia energética tuvo también su lugar. Los modelos como GPT-4o mini o versiones más pequeñas de LLaMA e ideogramas sirven a dispositivos móviles o aplicaciones ubicuas sin sacrificar rendimiento, acercando la IA a millones de usuarios con necesidades variadas.
En el último trimestre de 2024 y comienzo de 2025, la evolución no disminuye. OpenAI ha presentado modelos como O1 y O3, que muestran capacidades nunca antes vistas en razonamiento matemático, científico y generación de contenido avanzado, además de funcionalidades para búsqueda autónoma y generación de voz mejorada. Google intensifica el desarrollo de Gemini 2.0, integrando capacidades de pensamiento avanzado, generación y edición de imágenes y videos, así como contextos extensísimos. Compitiendo en esta arena de innovación, actores emergentes como xAI con Grok y Anthropic con Claude 3.
7 agregan complejidad y potencia con funciones de raciocinio extendido que superan incluso las expectativas iniciales en tareas de codificación y análisis profundo. Meta sigue avanzando con Llama 3.3 y los modelos de generación de contenido audiovisual como Apollo y Movie Gen, mientras Alibaba y DeepSeekAI ofrecen modelos abiertos con desempeño competitivo en ámbitos muy complejos, desde manejo multimodal hasta razonamiento profundo en matemáticas y programación. En el terreno audiovisual, el lanzamiento de Veo 2 por Google, Firefly Video por Adobe y actualizaciones de Pika Labs han marcado una era donde la generación de videos en alta resolución y de largo formato es posible con inteligencia artificial, abriendo puertas para la creación de contenido en cine, publicidad y entretenimiento digital con procesos automatizados y eficientes. La historia reciente de la inteligencia artificial demuestra un impresionante ciclo de innovación, expansión y democratización tecnológica.