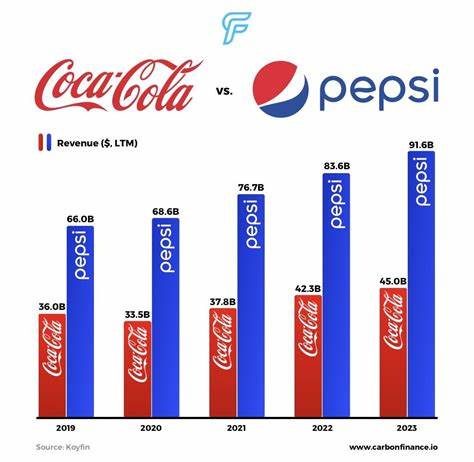
La integración de los modelos de lenguaje a gran escala (LLMs, por sus siglas en inglés) en el ámbito del desarrollo de software representa una transformación profunda que va más allá de la simple autocompletación de código. Estos modelos, impulsados por inteligencia artificial avanzada, abren nuevas posibilidades que pueden cambiar la manera en que programadores y empresas abordan la creación y validación de software. En particular, uno de los aspectos más novedosos y prometedores es el uso de los LLMs como oráculos sin sesgos para la generación automática de pruebas y código, aportando un nivel de objetividad y precisión que supera las limitaciones tradicionales. Históricamente, la generación de código asistida por IA se ha basado eminentemente en el entendimiento inherente del propio modelo sobre la sintaxis y patrones de programación aprendidos durante su entrenamiento. Cuando se proporciona un enunciado o prompt, el modelo genera fragmentos de código que considera válidos y pertinentes según los datos con los que fue entrenado.
No obstante, una problemática recurrente ha sido la dificultad para verificar la corrección y adecuación de ese código generado, ya que la responsabilidad de validarlo recae principalmente en el juicio humano o en pruebas manuales poco sistemáticas. Este método resulta en un ciclo reactivo en la detección de errores y puede dejar pasar fallos que afectan la calidad del producto final. Por ello, ha surgido la necesidad de invertir el paradigma tradicional e introducir un pipeline donde la generación de pruebas preceda y guíe la creación del código. En lugar de que el modelo genere directamente el software a partir de una descripción textual vaga o imprecisa, se plantea un abordaje más riguroso: primero se especifican de manera clara y estructurada los requerimientos funcionales. Estas especificaciones pueden estar expresadas no solo en lenguaje natural, sino idealmente en lenguajes especializados, anotaciones formales o mediante la definición precisa de tipos de entrada, salidas, precondiciones y postcondiciones.
Esta formalidad crea lechos fértiles para que los modelos de lenguaje trabajen con mayor certeza. Luego, un modelo especializado en generación de pruebas utiliza esta especificación para desarrollar un conjunto amplio y diverso de casos de prueba que evalúan el comportamiento esperado del software desde una perspectiva externa. En esta instancia, la particularidad esencial es que el modelo encargado de crear las pruebas no tiene visibilidad alguna sobre cómo se implementará el código que habrá de ser evaluado. Esta falta de información garantiza que las pruebas sean objetivas y no se vean influenciadas por la forma en que se escribe el software, abrazando así el principio fundamental de las pruebas de caja negra: evaluar únicamente la relación entrada-salida sin considerar la estructura interna. Una vez creados estos casos de prueba, un segundo modelo de lenguaje, enfocado en generación de código, se encarga de desarrollar la solución que satisfaga estrictamente los criterios expresados por la batería de pruebas.
El proceso continúa hasta que se obtiene una implementación que pase rigurosamente todos los exámenes planteados. Este ciclo posibilita un marco verificable y repetible donde la corrección del código se asegura objetivamente en vez de depender exclusivamente del criterio interno del modelo o de la revisión humana, lo que normalmente es subjetivo y propenso a errores. Los beneficios de este enfoque son múltiples y profundos. En primer lugar, la producción de pruebas desde una posición independiente y ciega respecto a la implementación disminuye considerablemente el riesgo de introducir sesgos, un problema recurrente cuando se utiliza una misma fuente para codificar y validar resultados. El LLM que genera las pruebas actúa como un verdadero oráculo imparcial que mira únicamente el cumplimiento de las especificaciones, sin suposiciones atadas a soluciones preconcebidas.
Esto fomenta la creación de suites de pruebas más robustas, variadas y completas, capaces de detectar incluso defectos sutiles y edge cases que un programador humano podría pasar por alto. Además, la segregación de funciones permite una especialización tanto para el modelo de generación de pruebas como para el de producción de código. Entrenar un modelo para generar pruebas demanda un conjunto de datos orientados a la relación específica entre especificaciones y casos de prueba bien diseñados, mientras que entrenar otro modelo para producir código que pase dichas pruebas implica enfocarse en la relación inversa entre requisitos verificados y soluciones implementadas. Esta especialización reduce la complejidad que tendría un único modelo destinado a abarcar ambas tareas simultáneamente, lo que puede mejorar notablemente la eficiencia y la efectividad general. La adopción de esta metodología basada en LLMs también podría transformar la cultura de desarrollo de software.
El cambio hacia un paradigma orientado a la prueba primera fomenta una mayor disciplina de especificación clara, así como una validación temprana y continua. Esto puede reducir costos asociados a la corrección tardía de errores, disminuir el tiempo de desarrollo y elevar la calidad del producto final. En la práctica, herramientas y empresas innovadoras están comenzando a explorar estas capacidades. Plataformas especializadas en encontrar bugs mediante IA ya ofrecen funcionalidades que integran pruebas automatizadas generadas por modelos de lenguaje, representando un paso hacia una automatización completa y minimizando la intervención humana solo a actividades de supervisión y ajustes finos. Este avance promete transformar el desarrollo de software en una actividad más predecible, segura y eficiente.
El futuro de los LLMs en el desarrollo de software parece orientado a consolidar este enfoque de oráculos imparciales mediante pruebas automatizadas, alineando un ciclo cerrado de generación y verificación donde la inteligencia artificial no solo crea software, sino que también lo valida rigurosamente. Esto revolucionará la forma en que las empresas producen código, incrementando la confiabilidad y acelerando la entrega de productos tecnológicos de alta calidad. En conclusión, utilizar modelos de lenguaje a gran escala como oráculos sin sesgos mediante un pipeline de generación de pruebas automatizadas y código validado representa una innovación clave en la ingeniería de software. Este enfoque no solo mejora la objetividad en la verificación, sino que también optimiza el entrenamiento y las capacidades de los modelos especializados, abriendo camino a una nueva era en el desarrollo eficiente, seguro y confiable de aplicaciones.