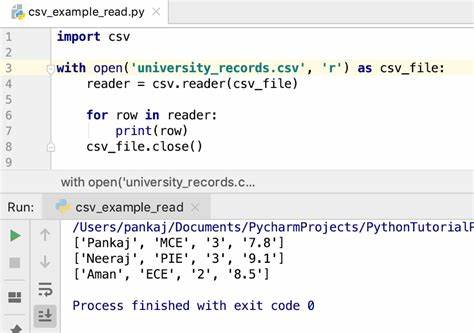
El formato CSV, que significa Comma-Separated Values (Valores Separados por Comas), es uno de los formatos de datos tabulares más utilizados en todo el mundo debido a su simplicidad y facilidad de lectura. Sin embargo, aunque a primera vista parece un formato simple y directo, el análisis y la importación de archivos CSV pueden volverse sorprendentemente complejos. Esta complejidad puede generar dificultades significativas para los desarrolladores que construyen software que depende de la importación y procesamiento de datos en formato CSV. ¿Por qué sucede esto? En este texto exploraremos las razones por las cuales el análisis de CSV no es tan trivial como parece y cómo estas complicaciones impactan en diferentes sectores, especialmente en el software como servicio (SaaS). La importancia del formato CSV en las plataformas SaaS no puede subestimarse, ya que representa a menudo el primer contacto que tienen los usuarios con el sistema.
Muchas empresas ofrecen la posibilidad de importar listas de contactos, inventarios de productos o datos de empleados mediante archivos CSV. Esta funcionalidad es clave para facilitar la entrada de datos y mejorar la experiencia del usuario desde el inicio. Sin embargo, cuando la importación falla debido a problemas con el archivo CSV, puede generar frustración en los usuarios, retrasar la puesta en marcha e incluso causar un desvío de recursos valiosos para el equipo de desarrollo. Una de las razones principales que hacen que el análisis de CSV sea complejo es la gran variabilidad en cómo se crean estos archivos. Aunque la especificación oficial, conocida como RFC 4180, establece ciertas pautas, muchas implementaciones en la práctica las ignoran o las adaptan a necesidades específicas, lo que genera incompatibilidades.
Por ejemplo, la elección del delimitador es un factor fundamental y a menudo causa confusión. Aunque tradicionalmente el delimitador es la coma, existen archivos que utilizan tabulaciones, punto y coma o incluso el símbolo de barra vertical o pipe como separadores. Es común que programas como Microsoft Excel en Europa utilicen por defecto el punto y coma, lo que puede provocar que un mismo analizador de archivos CSV falle al procesar el archivo si no está configurado adecuadamente. Otro desafío que complica el análisis del formato CSV es el manejo adecuado de las comillas y los caracteres de escape. Una buena parte de los datos reales contienen comas, saltos de línea o incluso comillas dentro de los campos, lo que requiere que estos estén correctamente rodeados por comillas y que se aplique una lógica precisa de escape.
La norma indica que las comillas dobles se deben representar duplicando la comilla dentro del campo (es decir, dos comillas), pero en la práctica algunos sistemas utilizan diagonal invertida o backslash para escapar caracteres, lo que puede provocar incoherencias. Además, los finales de línea varían entre distintos sistemas operativos; mientras en Windows se utiliza CRLF, en macOS y Linux se usa LF, y versiones antiguas de Mac OS empleaban CR, lo que requiere que los parsers sean capaces de identificar y adaptarse a estas diferencias para evitar errores. Un problema frecuente al importar CSV son las cabeceras o headers de las tablas. No todos los archivos CSV incluyen una primera fila que describa el nombre de las columnas, y cuando existen, estas pueden estar desordenadas, mal escritas o incluso aparecer en filas intermedias en lugar de la primera posición. Esta inconsistencia dificulta el mapeo correcto entre los datos y las estructuras internas que esperan las aplicaciones, lo que obliga a implementar capas adicionales de validación y corrección automática o manual.
El tema de la codificación también añade dificultad al manejo de archivos CSV. Muchos sistemas, en especial aquellos que utilizan Microsoft Excel, guardan archivos CSV en codificaciones diferentes como ISO-8859-1 o UTF-16, además de la codificación universal UTF-8. El análisis debe ser consciente de estas diferentes codificaciones y tener la capacidad de identificar adecuadamente marcas de orden de bytes (byte order marks, BOM) y convertir el archivo a la codificación esperada en tiempo real. De lo contrario, podría producirse corrupción de caracteres, especialmente con signos de puntuación y caracteres especiales utilizados en idiomas latinos e internacionales. Por otro lado, el manejo de archivos CSV de gran tamaño plantea inconvenientes de rendimiento.
Cargar el archivo completo en memoria es una práctica frecuente pero potencialmente problemática, ya que puede llevar a fallos por falta de memoria o ralentización del sistema. La solución común es procesar los archivos en streaming, es decir, leer y analizar los datos poco a poco. No obstante, esta técnica exige una infraestructura más compleja para gestionar el control de flujo o backpressure y para mantener la integridad de los datos durante la importación incremental. La inferencia automática de tipos es otro aspecto que complica la importación de datos CSV. Sin un esquema o estructura definida, los sistemas intentan deducir si un campo es numérico, fecha o texto.
Esto puede provocar problemas como la eliminación automática de ceros a la izquierda en códigos postales, la conversión incorrecta de fechas o la transformación errónea de identificadores, que en ocasiones son alfanuméricos. Estos errores afectan la calidad de los datos finales y pueden generar inconsistencias críticas en el negocio. Muchas organizaciones, particularmente aquellas que desarrollan plataformas SaaS, han subestimado el esfuerzo necesario para construir un parser de CSV robusto. La simplicidad aparente del formato induce a pensar que el desarrollo será rápido, pero pronto aparecen muchos edge cases y detalles técnicos que consumen tiempo y recursos. Incluso existen testimonios que hablan de gastos significativos, en el orden de decenas o cientos de miles de dólares, debido a la complejidad inesperada del proyecto.
En cuanto a casos concretos, diferentes sectores presentan desafíos específicos. Por ejemplo, los CRM enfrentan dificultades con mapeos complejos y caracteres internacionales, que requieren mayor precisión para garantizar la integridad de los datos. Las plataformas de comercio electrónico deben lidiar con descripciones de productos que incluyen múltiples líneas, comillas incrustadas y formatos no homogéneos. El software de gestión de recursos humanos, por su parte, sufre problemas derivados de fechas inconsistentes y codificaciones mixtas, los cuales pueden afectar la fiabilidad del sistema. Para superar estos retos, es necesario adoptar una estrategia defensiva al diseñar importadores de CSV.
Esto incluye la posibilidad de configurar el procesamiento para distintos delimitadores, tipos de codificación, caracteres de comillas y mecanismos de escape. Además, proporcionar a los usuarios herramientas que faciliten la validación y corrección de sus archivos antes de la importación ayuda a evitar errores y mejora la experiencia general. Escoger la librería o framework adecuado es crucial y debe basarse en el entorno de ejecución, el tamaño esperado de los archivos y los requisitos específicos del proyecto. Algunas librerías ofrecen capacidades de streaming que mejoran el rendimiento con archivos grandes, mientras que otras pueden centrarse en la facilidad de uso o en el tratamiento de múltiples codificaciones. Implementar un enfoque por capas en el proceso de importación también resulta eficiente.
Esto implica separar la lógica de parsing del archivo, la transformación de datos y la validación contra esquemas y reglas de negocio. De esta manera, es posible aislar errores, permitir una mayor flexibilidad y mantener la escalabilidad del sistema. En última instancia, aunque el formato CSV parece una solución simple para intercambio de datos, detrás de su apariencia se ocultan numerosos desafíos técnicos que deben ser abordados cuidadosamente. Reconocer y anticipar estos problemas permitirá a los desarrolladores crear herramientas más robustas y usuarios más satisfechos. La clave es respetar la complejidad inherente al formato y adoptar buenas prácticas basadas en la experiencia y el entendimiento profundo del ecosistema CSV.
A medida que las empresas continúan dependiendo del intercambio de datos a través de archivos CSV, la calidad y fiabilidad del análisis de estos documentos seguirá siendo un pilar fundamental para garantizar el éxito en la incorporación y procesamiento de la información. Atender estas dificultades no solo evitará frustraciones y pérdidas, sino que también fortalecerá la confianza de los usuarios en las plataformas digitales modernas. En conclusión, la dificultad de parsear archivos CSV no reside tanto en el formato en sí, sino en la diversidad de implementaciones, variaciones y casos especiales que deben ser manejados. Construir importadores capaces de lidiar con estas complejidades representa un desafío tecnológico importante pero necesario para ofrecer experiencias sólidas y eficientes en cualquier aplicación que use CSV como medio de entrada de datos.