En el mundo actual, donde los datos crecen exponencialmente y las consultas deben ser rápidas y precisas, las bases de datos relacionales enfrentan el desafío de ofrecer soluciones efectivas para búsquedas de texto completo. Postgres, como uno de los sistemas de gestión de bases de datos más robustos y flexibles, ha sido durante mucho tiempo la opción preferida por desarrolladores y empresas. Sin embargo, la integración de capacidades avanzadas de búsqueda en texto completo dentro de Postgres ha requerido innovaciones significativas en su arquitectura de almacenamiento. Recientemente, la extensión pg_search ha llevado a cabo una transformación pionera al migrar su sistema tradicional de archivos externos a un nuevo layout basado en el almacenamiento en bloques de Postgres, revolucionando la forma en que se gestionan y consultan los índices de búsqueda. Esta evolución no solo mejora la eficiencia sino que asegura una integración profunda con las características internas de Postgres, como el registro de escritura anticipada (WAL) y el control de concurrencia multi-versión (MVCC).
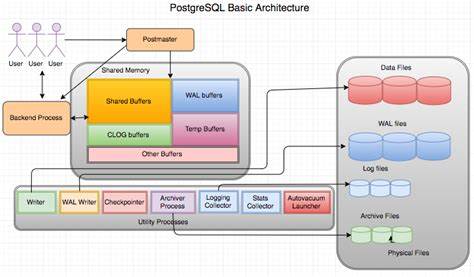
A continuación, se presentan las motivaciones, retos y soluciones clave de esta innovación que marca un hito en las capacidades de búsqueda de texto completo en bases de datos relacionales. El almacenamiento basado en bloques es fundamental para la arquitectura de Postgres. Cada bloque consiste en un segmento de 8 kilobytes que Postgres utiliza para leer datos a través de su caché interna, optimizando el acceso y reduciendo la latencia. Antes de la migración, la extensión pg_search almacenaba sus índices fuera del sistema de almacenamiento nativo de bloques, generando archivos independientes que, aunque funcionales, carecían de integración con la gestión interna de Postgres. Esto significaba que características vitales como la replicación física, la recuperación ante fallos y la coherencia transaccional no se gestionaban idealmente, generando posibles problemas de integridad y rendimiento.
La decisión de migrar pg_search al almacenamiento en bloques de Postgres implicó superar diversos desafíos técnicos. Principalmente, los índices de texto completo que maneja pg_search están basados en Tantivy, una biblioteca de búsqueda escrita en Rust inspirada en Lucene, que tradicionalmente utiliza un sistema de archivos para almacenar sus datos segmentados. Cada segmento está compuesto por múltiples archivos que controlan desde la lista de términos hasta la posición exacta de palabras en documentos, y hasta datos analíticos para ranking y filtrado. La migración implicó repensar completamente cómo estos datos, originalmente almacenados como archivos, se serializan y administran en bloques de 8 KB, respetando al mismo tiempo las reglas de bloque reutilizables, la imposibilidad de eliminar bloques físicamente y los requerimientos de control de concurrencia. Uno de los grandes retos fue manejar archivos que superan en tamaño a un bloque individual.
En soluciones tradicionales, los archivos pueden mapearse a memoria en su totalidad, permitiendo accesos rápidos y sin copias adicionales. No obstante, en el modelo de bloques de Postgres, un archivo grande debe dividirse y enlazarse en una estructura de lista enlazada, donde cada bloque apunta al siguiente mediante un espacio reservado para meta información. Este mecanismo garantiza que los bloques puedan navegarse de manera eficiente, logrando accesos directos mediante un encabezado que contiene el mapeo de posiciones. Para evitar que la fragmentación y la lectura cascada penalicen el rendimiento, se optimizaron las operaciones para cargar y almacenar segmentos, minimizando la cantidad de lecturas redundantes. Además, Postgres enfrenta un desafío específico: no puede mapear bloques a memoria de manera continua, por lo que la solución tradicional de acceso cero-copia no se puede implementar de forma directa.
Para mitigar esta limitación, se modificó Tantivy para que defiera la desreferenciación de grandes bloques de datos hasta que es estrictamente necesario, implementando cacheo interno para evitar accesos repetidos y garantizar que el impacto en el rendimiento durante consultas complejas sea mínimo. Otro desafío crucial lo representa la naturaleza inmutable de los segmentos dentro del índice. Cada vez que se realiza una modificación en los datos, se genera un nuevo segmento, lo que puede llevar a un aumento exponencial de segmentos en tablas con altas tasas de actualización. Este fenómeno puede afectar negativamente los tiempos de búsqueda y la carga del sistema. Para contrarrestar este efecto, se desarrolló un mecanismo inteligente de fusión denominada merge_on_insert, que detecta automáticamente oportunidades para combinar segmentos recién insertados, optimizando así el número total de segmentos activos sin comprometer la coherencia ni la exactitud de los resultados.
El manejo cuidadoso de bloque y transacciones también fue esencial para garantizar que solo un proceso de fusión pueda ejecutarse en simultáneo, evitando conflictos y duplicación de segmentos. Se usa para ello la escritura atómica de identificadores de transacción en bloques de metadatos y la verificación de visibilidad MVCC, asegurando que los procesos de fusión sigan el orden correcto y respeten el aislamiento transaccional. Las ventajas del almacenamiento en bloques para pg_search son visibles desde varios ángulos. Primero, la integración con el sistema WAL de Postgres concede soporte completo para replicación física, facilitando la configuración de réplicas y la recuperación ante fallos sin depender de mecanismos externos. Segundo, el uso compartido de la caché de buffers de Postgres reduce considerablemente la I/O de disco, acelerando tanto la creación de índices como la ejecución de consultas y escrituras.
Tercero, la administración nativa de espacio libre y reutilización de bloques por parte de Postgres simplifica el mantenimiento y evita el crecimiento indefinido del índice sin desfase operativo. Esta evolución facilita también que pg_search pueda aprovechar futuros desarrollos en Postgres, como mejoras en los trabajadores paralelos y en la gestión de la concurrencia, sin necesidad de modificar profundamente su núcleo. La eliminación de sistemas de bloqueo basados en archivo, reemplazados por los mecanismos interprocesos nativos de Postgres, reduce la complejidad y mejora la estabilidad general del sistema. En perspectiva, la migración del sistema de almacenamiento de pg_search a la arquitectura de bloques de Postgres no solo es un ejemplo destacado de innovación técnica sino también una inspiración para otras extensiones que dependen actualmente de archivos externos. Abre una puerta hacia índices de búsqueda más robustos, consistentes y fáciles de administrar integrados profundamente con el ecosistema Postgres.
Además de mejorar la experiencia tradicional de búsqueda de texto completo, el nuevo layout sienta las bases para futuras funcionalidades, destinadas a optimizar consultas analíticas como las búsquedas facetadas, agregaciones rápidas y similares basadas en patrones, potenciando escenarios de uso empresarial donde la rapidez y precisión en el acceso a la información son críticas. En definitiva, el rediseño del almacenamiento en pg_search refleja el compromiso de la comunidad con la mejora continua del ecosistema Postgres, manteniéndose a la vanguardia en tecnología de bases de datos relacionales y ofreciendo soluciones potentes y confiables para los retos del manejo de datos contemporáneos. Usuarios y desarrolladores pueden esperar que esta innovación impulse una nueva generación de aplicaciones capaces de explotar la búsqueda de texto completo con una eficiencia y flexibilidad nunca antes vistas en entornos SQL.






![Gumroad CEO's playbook to 40x his team's productivity with v0, Cursor, and Devin [video]](/images/0A351BB4-5A75-4CDB-B805-8E3459FDD141)
