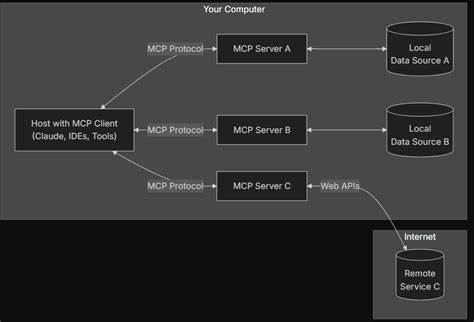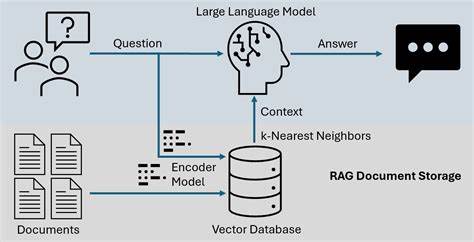
Los modelos de lenguaje grande (LLM) han revolucionado la forma en que interactuamos con la inteligencia artificial, permitiendo avances significativos en procesamiento de lenguaje natural, generación de texto y asistencia automatizada. En este contexto, los sistemas de Recuperación Augmentada por Generación (RAG) se han posicionado como una innovación prometedora para mejorar la precisión y pertinencia de las respuestas generadas. Sin embargo, aunque estos sistemas ofrecen ventajas, es fundamental entender por qué pueden hacer que los LLMs sean menos seguros, no más. Esta realidad representa un desafío crítico para desarrolladores, investigadores y usuarios finales. Los sistemas RAG funcionan integrando una etapa de recuperación de información en tiempo real dentro del proceso de generación de texto.
En esencia, antes de que el modelo produzca una respuesta, consulta una base de datos o un conjunto de documentos relevantes para obtener contexto actualizado. La idea es que, al incorporar conocimiento externo y específico, el modelo pueda ofrecer respuestas más precisas y fundamentadas en lugar de depender únicamente del entrenamiento previo. A primera vista, esta estrategia parece ideal para reducir errores y desinformación, pero existen múltiples factores que pueden comprometer la seguridad del modelo. Uno de los principales riesgos radica en la fuente y calidad de la información recuperada. Si el sistema RAG extrae datos de fuentes poco confiables, desactualizadas o manipuladas, el LLM puede incorporar contenido incorrecto o malicioso en sus respuestas.
Esto incrementa la posibilidad de que se difunda desinformación, sesgos o incluso contenido ofensivo. Aun cuando las fuentes son legítimas, la interpretación del contexto puede ser errónea, llevando a conclusiones inapropiadas o erróneas. Además, los modelos RAG pueden ser más vulnerables a ataques de adversarios que manipulan la base de datos de documentos. Si un atacante logra insertar información maliciosa o tendenciosa en la fuente de recuperación, el modelo puede entregarla como respuesta confiable, lo que afecta la integridad y la fiabilidad del sistema. Este tipo de vulnerabilidad pone en jaque la seguridad del modelo y la confianza del usuario, especialmente en aplicaciones sensibles como asesoría médica, jurídica o financiera.
Otro aspecto relevante es que la implementación de sistemas RAG tiende a aumentar la complejidad del pipeline de procesamiento de lenguaje natural, haciendo que las pruebas y auditorías de seguridad sean más difíciles. Al incorporar múltiples componentes, cada uno con sus posibles fallos, se vuelve complicado controlar el comportamiento general del sistema. Sin una supervisión rigurosa, estas complejidades pueden traducirse en brechas de seguridad inesperadas, errores humanos en la gestión de las bases de datos o errores en la integración entre recuperación y generación. Incluso la latencia y el rendimiento pueden afectar la seguridad en los sistemas RAG. Al ejecutar consultas en tiempo real para recuperar información, puede surgir presión para acelerar estos procesos y así entregar respuestas más rápidas.
No obstante, la optimización apresurada puede sacrificar controles necesarios para evaluar la calidad o coherencia de los datos, lo que también puede derivar en respuestas erróneas o problemáticas. Un balance cuidadoso entre rapidez y seguridad es indispensable para evitar riesgos innecesarios. También es fundamental considerar el impacto en la privacidad de los usuarios. Los sistemas RAG que almacenan o utilizan grandes cantidades de datos para la recuperación pueden involucrar información sensible o personal. Una gestión inadecuada de estos datos puede dar lugar a vulneraciones de privacidad o a filtraciones involuntarias, afectando la seguridad tanto del sistema como de los usuarios.
Para mitigar estos problemas, es necesario implementar mecanismos robustos de control de calidad en las fuentes utilizadas por los sistemas RAG. Esto incluye validar la confiabilidad, actualizar constantemente la información y utilizar filtros para excluir contenido malicioso. Asimismo, la supervisión humana continúa siendo crucial para identificar fallos o desviaciones que la automatización no detecta fácilmente. La investigación en técnicas avanzadas de contramedidas contra ataques adversarios también juega un papel importante para proteger la integridad de las bases de datos de recuperación. La transparencia en los procesos y en los orígenes de la información ayuda a construir confianza y permite auditorías efectivas.
El desarrollo de métricas específicas para evaluar la seguridad y la coherencia en las respuestas generadas por sistemas RAG ayudará a detectar problemas antes de que impacten negativamente a los usuarios. Estas métricas deben formar parte de los ciclos de desarrollo y mantenimiento de las plataformas basadas en LLM. Por último, las regulaciones y estándares sobre el uso de datos y la inteligencia artificial contribuyen a establecer marcos legales claros para la seguridad y protección de los usuarios. La colaboración entre la industria, el mundo académico y los organismos reguladores es crucial para minimizar los riesgos asociados con la implementación de sistemas RAG. En conclusión, aunque los sistemas RAG ofrecen una vía prometedora para enriquecer la capacidad de los modelos de lenguaje grande, su implementación inadvertida puede generar riesgos importantes para la seguridad y la confiabilidad.
La complejidad añadida, la dependencia de fuentes externas y la susceptibilidad a manipulaciones adversarias son factores que deben ser cuidadosamente gestionados. Solo mediante un enfoque riguroso que combine tecnología avanzada, supervisión humana y regulación adecuada será posible aprovechar los beneficios de los sistemas RAG sin comprometer la seguridad inherente a los LLM.