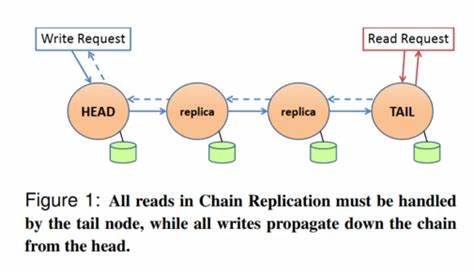
En el ámbito de los sistemas distribuidos, la replicación de datos se presenta como un pilar fundamental para garantizar confiabilidad, disponibilidad y consistencia de la información. Uno de los enfoques tradicionales para alcanzar estos objetivos es la replicación en cadena, un método que, aunque efectivo, enfrenta limitaciones específicas especialmente en cuanto a la velocidad de lectura y la adaptación ante fallos. Surge entonces CRAQ, o Chain Replication with Apportioned Queries, que introduce innovaciones significativas para optimizar el rendimiento y superar las barreras de la replicación clásica. El propósito central de CRAQ es mejorar la lectura en sistemas de almacenamiento clave-valor que replican datos en múltiples nodos organizados como una cadena lineal, similar a una lista enlazada. En el modelo clásico de replicación en cadena, los nodos están dispuestos desde un nodo cabeza (head) hasta un nodo cola (tail).
Las escrituras se gestionan exclusivamente en el nodo cabeza, mientras que las lecturas se concentran en el nodo cola. Este esquema, aunque evita conflictos, puede generar cuellos de botella pues la velocidad de la cadena está limitada por el nodo más lento, normalmente la cola. En este contexto, CRAQ se presenta como una evolución al permitir que las consultas de lectura se aporcionen a nodos intermedios en la cadena, no limitándose solo al nodo cola. Esta innovación amplifica la capacidad de lectura y mejora considerablemente la eficiencia general del sistema. Sin embargo, esta libertad en la lectura plantea un delicado desafío: mantener la consistencia de datos para asegurar que la información leída desde nodos intermedios sea confiable y actualizada.
El mecanismo que permite a CRAQ conservar la consistencia radica en gestionar con precisión los diferentes estados de las versiones de las claves almacenadas en cada nodo. Cuando se realiza una escritura, el dato identificado por una clave se marca inicialmente como sucio (dirty) en el nodo cabeza y se propagará a lo largo de la cadena. Con cada transferencia hacia un nodo siguiente en la cadena, el dato se guarda también como sucio hasta que finalmente llegue al nodo cola, donde se transforma en limpio (clean). La transformación implica no solo guardar la nueva versión como la oficial, sino también eliminar versiones anteriores, lo que se conoce como limpieza o compactación. El proceso involucra una confirmación en sentido inverso, es decir, una vez que la última confirmación se alcanza en el nodo cola, ésta regresa hacia los nodos anteriores, que actualizan sus datos y eliminan las versiones sucias de manera que todos mantengan una versión limpia y consistente.
Mientras este ciclo ocurre de forma transparente, el sistema asegura que solo las versiones limpias estén disponibles para lecturas en el nodo cola. CRAQ innova al permitir que los nodos intermedios también respondan consultas de lectura. Cuando un nodo recibe una solicitud de lectura, evalúa la versión local de la clave. Si solo existe una versión limpia, se puede devolver inmediatamente el dato. Pero si hay versiones sucias o múltiples versiones, el nodo procede a consultar al nodo cola para verificar cual es el estado más reciente y confirmarlo.
Esta consulta no solo sirve para obtener el dato correcto, sino que actúa como una forma implícita de acuse de recibo, lo cual permite al nodo intermedio actualizar su versión local a limpia y eliminar las versiones antiguas o inconsistentes. Este modelo garantiza una consistencia fuerte, ya que las lecturas en cualquier nodo reflejan el estado más actualizado confirmado por el nodo cola. Sin embargo, CRAQ también admite otros modelos de consistencia, ofreciendo flexibilidad para adaptarse a diferentes casos de uso. Por ejemplo, bajo consistencia eventual, un nodo puede devolver la versión más reciente que conoce sin necesariamente validar con el nodo cola, lo cual puede reducir la latencia pero a costa de que diferentes nodos puedan responder con versiones no uniformes. También está la modalidad de consistencia eventual con inconsistencia acotada —donde solo se permite servir versiones no confirmadas hasta ciertos límites— ideal para balancear entre frescura y disponibilidad.
Estos enfoques permiten diseñar sistemas que se adapten a necesidades específicas, desde aplicaciones que demandan fuerte consistencia hasta otras donde cierta tolerancia a la inconsistencia temporal es aceptable para mejorar rendimiento. Un aspecto clave que emerge del análisis de CRAQ es que la gestión y mantenimiento de la topología de la cadena no es una tarea trivial ni delegable completamente a los propios nodos. La operación coordinada de la cadena requiere un servicio externo o un módulo de gestión responsable de mantener actualizada la configuración, los roles y ubicación de cada nodo. Este componente puede estar basado en plataformas como Zookeeper, que provee un sistema de coordinación centralizado para servicios distribuidos, o en algoritmos de consenso distribuidos como Raft o Paxos. La existencia de este mecanismo externo evita escenarios problemáticos como la bifurcación (split-brain), donde dos nodos podrían considerarse a sí mismos cabeza de la cadena y aceptar escrituras contradictorias.
El servicio de coordinación garantiza que, ante interrupciones en la red o fallos en nodos, la cadena pueda reconfigurarse correctamente, promoviendo automáticamente al siguiente nodo la responsabilidad de cabeza o cola si es necesario. Respecto al desempeño durante fallos, CRAQ también presenta soluciones elegantes. La capacidad de reenviar valores sucios e información pendiente asegura que cuando un nuevo nodo se incorpora o cuando un nodo recuperado reingresa a la cadena, pueda sincronizar adecuadamente su estado y participar de la cadena sin perder datos ni afectar el compromiso de las escrituras previas. Esta característica es fundamental para sistemas con alta disponibilidad que requieren minimizar pérdidas o incompatibilidades durante el proceso de recuperación. A diferencia de sistemas con líderes absolutos para lecturas y escrituras, como aquellos basados únicamente en Raft, CRAQ disminuye la sobrecarga en el nodo cabeza al reducir la cantidad de mensajes por escritura.
En un escenario con múltiples seguidores, el método clásico obliga a enviar múltiples mensajes para replicar la escritura, mientras que CRAQ lo hace de manera secuencial y en cadena, optimizando la comunicación y facilitando escenarios con cargas altas de solicitud. Asimismo, al poder distribuir las lecturas entre múltiples nodos, CRAQ permite balancear la carga y reducir la latencia de respuesta, especialmente en implementaciones geográficamente distribuidas donde acercar el dato al cliente es crucial. Desde una perspectiva práctica, es indispensable reconocer que la implementación efectiva de CRAQ conlleva retos relacionados con la latencia introducida por la verificación de versiones en nodos intermedios, la sincronización continua con el nodo cola y la gestión del directorio o servicio de configuración externo. No obstante, el equilibrio entre esta complejidad y la mejora en rendimiento de lectura y tolerancia a fallos resulta atractivo para muchos entornos modernos, especialmente en sistemas de bases de datos distribuidas, almacenamiento en la nube y aplicaciones que manejan grandes volúmenes de datos con demandas exigentes. CRAQ no solo se destaca en aspectos técnicos sino también en su capacidad para integrarse con sistemas existentes, como los descritos en arquitecturas tipo 3FS, que emplean servidores de gestión para monitorear y mantener nodo direcciones y topologías.
Esto demuestra la aplicabilidad de CRAQ en escenarios industriales donde la robustez y escalabilidad son necesarias. Para quienes trabajan en desarrollo de sistemas distribuidos, entender CRAQ ofrece una perspectiva fresca sobre cómo optimizar la replicación y lectura de datos evitando cuellos de botella, manteniendo la coherencia y mejorando la experiencia de usuario. Así mismo, es una invitación a repensar los modelos tradicionales, explorando innovaciones que surgen desde la necesidad de equilibrar consistencia, disponibilidad y rendimiento. En conclusión, CRAQ representa un avance significativo en la replicación en cadena que mejora la capacidad de lectura mediante la asignación de consultas a nodos intermedios, manteniendo diferentes niveles de consistencia acorde a las necesidades del sistema. Su diseño cuidadoso, combinado con servicios externos para la gestión de topología, lo hacen una opción sólida para ambientes distribuidos modernos donde la eficiencia y la fiabilidad son prioritarias.
Quienes deseen profundizar en el tema podrán encontrar recursos valiosos en el trabajo original del paper CRAQ, complementado con estudios de casos y arquitecturas como 3FS que lo incorporan. La exploración de CRAQ abre las puertas a soluciones innovadoras que redefinen cómo entendemos la replicación de datos en cadenas distribuidas.