En el mundo moderno del desarrollo de software, la comunicación eficiente entre sistemas distribuidos es esencial para el éxito de cualquier arquitectura, especialmente cuando se trabaja con microservicios y sistemas auto-contenidos. Tradicionalmente, para implementar interfaces asíncronas se suele recurrir a middleware especializado como Apache Kafka o RabbitMQ. Sin embargo, estos sistemas, aunque potentes, introducen complejidad, dependencia de infraestructura adicional y retos operativos. Por ello, surge la necesidad de explorar alternativas más ligeras y accesibles, como los HTTP Feeds, que permiten diseñar interfaces asíncronas con protocolos y tecnologías estándar de la web, eliminando la necesidad de un sistema intermediario de mensajería dedicado. La arquitectura de microservicios se caracteriza por la división de aplicaciones en múltiples servicios pequeños e independientes que se comunican entre sí para cumplir funciones específicas.
Esta segmentación implica la existencia de interfaces o APIs entre los diferentes dominios funcionales. El desafío principal está en decidir cómo gestionar dichas comunicaciones, especialmente cuando la naturaleza de la interacción es asíncrona, como en eventos o actualizaciones que no requieren respuesta inmediata. Una forma tradicional de comunicación es la sincronía, donde una petición recibe respuesta en tiempo real, por ejemplo, una llamada REST con método GET para obtener datos de un cliente. Aunque su implementación es sencilla, su uso en sistemas críticos puede generar una dependencia estrecha entre servicios que puede comprometer la disponibilidad y la escalabilidad de la plataforma. Por ejemplo, si un sistema de facturación está en mantenimiento, un sistema de tienda online que dependa de él directamente podría enfrentarse a fallos o latencias no deseadas.
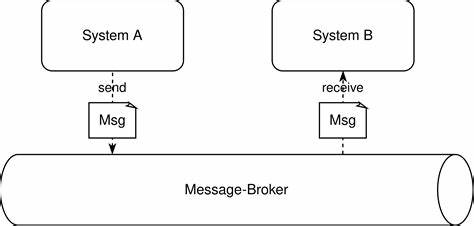
Para evitar estos problemas, la comunicación asíncrona resulta ideal. En esta modalidad, el emisor envía datos o notificaciones sin esperar una respuesta inmediata, y el receptor los procesa cuando está listo. Tradicionalmente, esta interacción se ha implementado usando sistemas de broker, que almacenan y retransmiten mensajes garantizando su entrega. Kafka y RabbitMQ son ejemplos de estas soluciones que disfrutan de gran popularidad por su robustez y versatilidad. No obstante, la incorporación de brokers añade un nivel de complejidad operacional a las organizaciones.
Requiere equipos responsables de su instalación, actualización, monitorización y resolución de problemas. Asimismo, obliga a que todos los equipos involucrados utilicen clientes compatibles, gestión de esquemas comunes y un manejo centralizado de los errores, agregando capas administrativas que pueden ralentizar el ciclo de desarrollo y despliegue. En contraste, HTTP Feeds proponen un enfoque minimalista y directo para implementar interfaces asíncronas. La idea central es que los sistemas productores publiquen datos a través de APIs HTTP accesibles mediante peticiones estándar como GET o POST. Los consumidores, por su parte, consultan estos puntos finales de manera periódica (polling) o mediante técnicas más avanzadas como long polling o streaming, recuperando así la información según su ritmo y capacidad.
Esta solución aprovecha la ubiquidad y madurez del protocolo HTTP, que no sólo es universalmente soportado sino que también facilita la integración con infraestructuras existentes. Las APIs RESTful son fáciles de desarrollar, documentar y mantener, y no requieren la instalación de componentes adicionales más allá de servidores web comunes. Esto reduce considerablemente la carga operativa y el riesgo de dependencias externas. Otro beneficio importante es la arquitectura desacoplada que permite HTTP Feeds. Debido a que el consumidor decide cuándo y cómo leer la información, ambos sistemas pueden funcionar de manera independiente sin necesidad de una coordinación estricta.
Esto proporciona mayor resiliencia ante fallos temporales y permite una escalabilidad flexible, ya que cada parte escalará según sus necesidades sin impactar directamente al contrario. En escenarios donde la actualización frecuente de datos es necesaria, como en notificaciones de eventos o sincronización de estados, HTTP Feeds pueden proporcionar latencias aceptables, especialmente cuando se implementan técnicas como cacheo inteligente, uso de encabezados HTTP de control de versión o iteradores para consultar cambios incrementales. Un aspecto crucial es el mantenimiento de la integridad y la seguridad de la información. Al exponer APIs de consumo de datos, es fundamental implementar autenticación, autorización y controles de acceso estrictos que garanticen que sólo consumidores autorizados puedan acceder a la información. Además, dado que algunos datos pueden estar sujetos a regulaciones como GDPR, debe considerarse cuidadosamente el manejo de datos personales y su almacenamiento temporal.