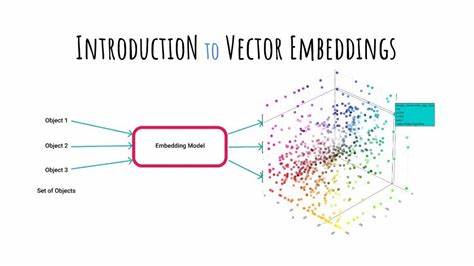
La inteligencia artificial (IA) es una de las tecnologías más transformadoras de nuestra era, y una de las claves para entender su funcionamiento actual reside en un concepto aparentemente sencillo pero poderoso: las embeddings. Estas representaciones numéricas hunden sus raíces en décadas de investigación y son el fundamento de muchos avances, especialmente en procesamiento de lenguaje natural. Aunque parezca un término técnico y complejo, comprender las embeddings no requiere un conocimiento matemático profundo; es básicamente entender cómo podemos convertir datos, ya sean palabras, documentos o cualquier tipo de información, en vectores de números que pueden ser analizados por computadoras. Para comprender mejor qué son las embeddings, es útil imaginar cómo clasificamos cosas en la vida cotidiana. Pensemos en los perros.
Cada perro puede ser descrito por características como tamaño, inteligencia, pelaje o rapidez. Podemos asignar números a cada una de estas características para formar un vector único para cada perro. Por ejemplo, un Gran Danés podría representarse como un vector que contenga números que reflejen su gran tamaño y alta inteligencia, mientras que un Bulldog tendría otros números diferentes. Estos vectores permiten calcular distancias entre perros para determinar cuáles son más similares o diferentes entre sí, utilizando medidas simples como la distancia Manhattan o la distancia Euclidiana. Esta idea se extiende a muchas dimensiones: a más características, más dimensiones tendrá nuestro espacio vectorial, y nuestra computadora podrá comparar elementos con mayor precisión.
Este método básico de clasificación mediante vectores y distancias es la raíz del concepto de embeddings. Cuando trasladamos esta idea al lenguaje, la complejidad crece porque no podemos simplemente asignar tamaños o inteligencias a palabras o textos. En su lugar, comenzamos por contar la frecuencia con la que una palabra aparece en un libro u otro texto, creando algo llamado “bolsa de palabras”. Así, cada documento se convierte en un vector con miles de dimensiones, una para cada palabra del vocabulario. Sin embargo, este enfoque tiene grandes limitaciones.
Por ejemplo, textos muy largos y cortos pueden parecer muy diferentes simplemente por la cantidad de palabras, no por su contenido real. Para mejorar esta representación, se aplican técnicas como la normalización, que ajusta las frecuencias de palabras en proporción a la longitud del texto. Además, se eliminan palabras comunes y poco informativas conocidas como “stop words”, como “el”, “la” o “de”, para que no distorsionen el análisis. Otra evolución importante es el uso de TF-IDF (frecuencia de término – inversa frecuencia de documento), que pondera las palabras por su importancia, lo que permite destacar las palabras raras y significativas frente a las que aparecen en casi todos los documentos. Aun así, el enfoque de la bolsa de palabras sigue teniendo problemas fundamentales.
La dimensionalidad es excesiva, con decenas de miles de palabras y sus variaciones, lo que hace difícil y costoso realizar cálculos eficientes. Las variaciones ortográficas, palabras con formas similares pero significados distintos, o el orden de las palabras, tampoco son adecuadamente manejados con este método. Para superar estas limitaciones, se desarrollaron las embeddings densas y aprendidas automáticamente. La piedra angular fue un avance tecnológico llamado Word2Vec, introducido por Google en 2013. En lugar de crear vectores gigantescos con una dimensión para cada palabra, esta técnica creó vectores mucho más compactos, con dimensiones reducidas (por ejemplo, 300 dimensiones), que codifican el significado semántico de las palabras.
El principio detrás de Word2Vec es simple y elegante: “una palabra se conoce por las palabras que la rodean”. Para entrenar el modelo, se examina un número de textos inmenso y se entrena una red neuronal para predecir una palabra basándose en su contexto (palabras alrededor). Inicialmente, las vectores asignados a las palabras son aleatorios, pero con el entrenamiento, la red ajusta gradualmente estos vectores para que las palabras que aparecen en contextos similares tengan vectores cercanos. El resultado fascinante es que las palabras con significados parecidos, como “perro”, “cachorro” y “pichicho”, terminan muy próximas en este espacio vectorial. Las relaciones complejas, como la analogía “rey menos hombre más mujer” que conduce a “reina”, emergen naturalmente de estos vectores, demostrando que el modelo ha aprendido conceptos abstractos y relaciones semánticas a partir únicamente del análisis estadístico del texto.
Pero el aprendizaje no termina en las palabras individuales. Para clasificar oraciones o párrafos completos, se pueden combinar estas embeddings de palabras mediante diversas técnicas, permitiendo capturar el significado de un texto mayor. Sin embargo, la simple suma o promedio de vectores pierde el orden y la secuencia, que también son fundamentales para entender el texto. Para resolver este problema, se introdujeron nuevas arquitecturas de redes neuronales que consideran el orden, como las Redes Neuronales Recurrentes (RNN) y, posteriormente, sus variantes mejoradas como LSTM y GRU, que permiten recordar información a lo largo de secuencias y no solo tratar palabras como puntos independientes. Estas redes mejoraron significativamente la capacidad de los modelos para interpretar el lenguaje humano en contexto.
Pero la verdadera revolución llegó con los transformadores y el mecanismo de atención, que hoy alimentan las grandes modelos de lenguaje (LLMs) como GPT. La atención permite que el modelo “pague más atención” a palabras relevantes sin importar cuán cercanas o lejanas estén, capturando la complejidad y las dependencias a largo plazo en el texto de forma eficiente y natural. Además, los transformadores no trabajan con palabras enteras, sino con tokens, que son fragmentos más pequeños y flexibles, lo que les permite manejar palabras desconocidas o errores tipográficos con mayor facilidad. Gracias a estas técnicas, las embeddings obtenidas son vectores de alta calidad, densos y capaces de representar de manera precisa y sofisticada el significado de fragmentos largos de texto. En la práctica, estas embeddings permiten realizar tareas que antes eran muy difíciles para las computadoras.
Clasificar textos de manera automática para detectar sentimientos positivos o negativos, agrupar documentos por temas sin saber de antemano cuáles son las categorías, o lograr una comprensión contextual profunda en aplicaciones como chatbots y asistentes virtuales, son solo algunos ejemplos. Una aplicación particularmente importante y extendida es el sistema de Recuperación Aumentada por Generación (RAG). Cuando un usuario hace una pregunta, el sistema genera un embedding de la consulta y busca en un conjunto de documentos las embeddings más cercanas para encontrar textos que probablemente contengan la respuesta. De esta manera, la inteligencia artificial puede responder con información específica y actualizada, evitando errores comunes en modelos que dependen solo de su conocimiento preentrenado. El uso de bases de datos vectoriales como Pinecone o pgvector es crucial en este proceso, ya que están optimizadas para buscar y comparar estos vectores de forma rápida y eficiente, incluso en grandes volúmenes de datos.
En resumen, las embeddings son la esencia de la inteligencia artificial moderna. Son representaciones numéricas que permiten a las máquinas entender, comparar y generar lenguaje de forma sorprendentemente humana. Aunque la matemática y la complejidad técnica detrás de ellas son profundas, su lógica básica puede ser comprendida de forma sencilla y sin necesidad de cálculos avanzados. Este conocimiento no solo aporta claridad a los conceptos actuales en IA, sino que también abre la puerta a imaginar nuevas aplicaciones y mejoras en tecnología y software que cada día impactan más en nuestra vida cotidiana. Entender cómo los ordenadores interpretan el lenguaje y la información mediante estas representaciones vectoriales es comprender la llave maestra para el futuro de la inteligencia artificial y el procesamiento de datos.
Así, la próxima vez que interactúes con un asistente inteligente, un motor de búsqueda o una herramienta que clasifique y resuma información, sabrás que detrás de esa magia hay un mundo fascinante de vectores numéricos y modelos que aprenden el significado en alta dimensión, transformando datos brutos en conocimiento útil y preciso.