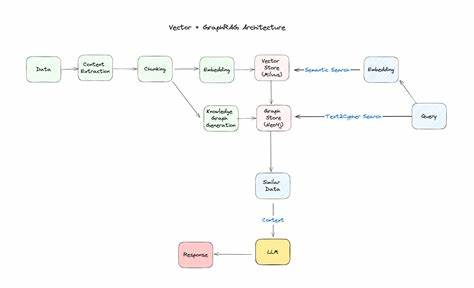
En la era actual de la inteligencia artificial y el procesamiento avanzado de datos, construir sistemas que integren grandes modelos de lenguaje con datos estructurados se ha convertido en un desafío clave para muchas organizaciones. GraphRAG, que significa Generación Aumentada por Recuperación basada en Grafos, es una solución innovadora que combina la capacidad de razonamiento relacional de los grafos con el poder de los modelos de lenguaje para mejorar significativamente la recuperación y generación de información. La construcción de un sistema GraphRAG eficaz requiere una comprensión profunda de las opciones disponibles en frameworks, bases de datos de gráficos y herramientas que facilitarán el procesamiento, la consulta y la integración con modelos de lenguaje. Para abordar esta tarea, es fundamental analizar las diferentes tecnologías que se pueden emplear y cómo optimizar el flujo desde la estructuración de datos hasta la generación de respuestas explícitas y contextuales. El primer paso para construir un sistema GraphRAG es la estructuración y modelado del dato.
En este sentido, la elección de la estructura de almacenamiento es vital. Para datasets pequeños y dinámicos, puede ser suficiente utilizar estructuras en memoria que permitan un acceso rápido y la actualización en tiempo real. Estas estructuras suelen ser grafos que permiten la navegación eficiente sobre relaciones o índices invertidos que favorecen la recuperación basada en palabras clave o documentos. La flexibilidad y rapidez que ofrecen estas estructuras hacen que sean ideales para prototipos o soluciones que no requieren almacenamiento persistente a gran escala. Sin embargo, para aplicaciones empresariales o de mayor envergadura, resulta preferible utilizar bases de datos especializadas.
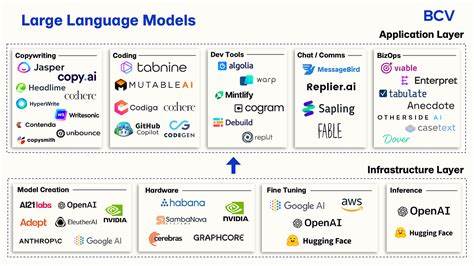
Dentro de este panorama, las bases de datos de grafos representan la mejor opción para manejar datos altamente relacionales y que requieren múltiples saltos de consulta para inferir respuestas complejas. Memgraph se destaca como una base de datos en memoria optimizada para procesamiento en tiempo real y algoritmos complejos como Louvain o Leiden, que son clave para detección de comunidades y agrupamientos en grandes grafos. Esta capacidad es esencial para realizar búsquedas que consideren la relación entre datos y no solo correspondencias textuales simples. Paralelamente, las bases de datos vectoriales juegan un papel crucial en el manejo de búsquedas semánticas, que funcionan gracias a los embeddings generados por grandes modelos de lenguaje. Weaviate y Pinecone destacan como opciones sólidas para este propósito, facilitando la recuperación de información que no solo se basa en palabras clave exactas, sino también en conceptos y similitudes semánticas subyacentes.
La integración de bases de datos vectoriales con las bases de datos de grafos permite un enfoque híbrido donde se combinan las capacidades de razonamiento y relaciones estructuradas con la semántica profunda capturada por los modelos de lenguaje. En algunos escenarios, las bases de datos relacionales tradicionales también pueden ser útiles, particularmente cuando se trata de sistemas heredados. No obstante, su limitación fundamental radica en la incapacidad para realizar razonamientos multi-salto o consultas complejas sobre relaciones entre entidades, lo que las hace menos recomendables para sistemas GraphRAG avanzados. Además de las bases de datos, existen motores de búsqueda como Elasticsearch, que sobresalen en la indexación y consulta de grandes volúmenes de datos textuales. Este tipo de motores puede combinarse con bases de datos de grafos para crear sistemas híbridos de recuperación que aprovechan tanto búsquedas por texto como razonamiento relacional.
Una vez que los datos están modelados y almacenados adecuadamente, la siguiente gran tarea es encontrar y extraer información relevante para enriquecer las consultas que se realizarán a los modelos de lenguaje. Esta etapa, conceptualmente llamada búsqueda pivote y expansión de relevancia, impulsa la capacidad de GraphRAG para regresar respuestas contextuales y fundamentadas. La búsqueda pivote implica identificar puntos de datos clave relacionados con el prompt del usuario; esto puede lograrse mediante búsqueda por palabra clave para coincidencias exactas, búsqueda textual que es más amplia y flexible, o búsqueda vectorial que utiliza embeddings para hallar información semánticamente similar incluso en ausencia de términos exactos de búsqueda. Existen también búsquedas especializadas como la búsqueda geográfica, que permite consultas basadas en la localización, ideal para aplicaciones que manejan datos espaciales. La combinación de estas técnicas permite incrementar el alcance y la precisión de la recuperación.
Para enriquecer aún más las respuestas obtenidas, es necesario realizar una expansión de relevancia que explore datos relacionados y conectados en el grafo. Algoritmos como Louvain o Leiden permiten detectar comunidades dentro del grafo para identificar agrupamientos naturales de datos que pueden ser relevantes. Por otro lado, algoritmos como PageRank ayudan a priorizar nodos en función de su importancia o centralidad dentro del grafo, permitiendo identificar información clave para el usuario. Finalmente, las exploraciones de grafos a través de recorridos multi-salto facilitan descubrir relaciones indirectas y datos de contexto que son fundamentales para respuestas más precisas y fundamentadas. Un ejemplo claro de un sistema GraphRAG eficiente puede construirse utilizando Memgraph debido a su capacidad de procesamiento en memoria y actualización en tiempo real.
El flujo típico comienza con un modelado del dato donde las entidades y sus relaciones se organizan en un esquema claro. A partir de ahí, el sistema realiza una búsqueda pivote utilizando diferentes técnicas para captar los puntos más relevantes en función de la consulta. Posteriormente, se aplica la expansión de relevancia con algoritmos de detección de comunidades o recorridos de grafo para ampliar el contexto. El dato obtenido posteriormente se utiliza para enriquecer el prompt del usuario, que se envía a un modelo de lenguaje preentrenado. Este enriquecimiento permite que el LLM produzca respuestas mucho más contextuales, precisas y valiosas para el usuario final.
La integración con frameworks como LangChain o LlamaIndex resulta fundamental para conectar de forma fluida las bases de datos con los modelos de lenguaje, permitiendo la orquestación del proceso y facilitando la escalabilidad del sistema. Esta solución ha sido aplicada con éxito en diversos sectores. En salud, se han desarrollado sistemas para apoyar la investigación sobre Alzheimer mediante el uso de modelos de autoaprendizaje reforzados con data de conocimiento estructurado. También en la gestión de enfermedades crónicas como la diabetes tipo 2, donde las soluciones basadas en GraphRAG han permitido proveer insights en tiempo real capaces de transformar la atención médica. Estos casos reflejan no solo la flexibilidad técnica sino la relevancia práctica y el impacto que puede tener un sistema bien diseñado.
Finalmente, una recomendación esencial es considerar un enfoque híbrido que combine las capacidades de bases de datos de grafos con bases de datos vectoriales y motores de búsqueda textuales. Esta combinación permite aprovechar lo mejor de cada mundo: la semántica profunda proporcionada por los embeddings y las capacidades relacionales complejas de los grafos. Ajustar este equilibrio según el volumen de datos, la necesidad de consultas en tiempo real, el presupuesto y la complejidad del dominio es crucial para el éxito a largo plazo. En resumen, el desarrollo de sistemas GraphRAG robustos y eficientes depende en gran medida de la elección cuidadosa de las tecnologías y herramientas disponibles. A partir de un buen modelado de datos, pasando por técnicas avanzadas de búsqueda y expansión, hasta la integración con modelos de lenguaje, la construcción de un entorno integrado es clave para maximizar el potencial de estos sistemas.
Con el avance continuo de las tecnologías de bases de datos y la evolución de los modelos de lenguaje, el futuro promete soluciones aún más sofisticadas que transformarán la manera en la que interactuamos con grandes volúmenes de información estructurada y no estructurada.