El avance de la inteligencia artificial ha transformado radicalmente la manera en que interactuamos con la tecnología. Los grandes modelos de lenguaje (LLMs, por sus siglas en inglés) se encuentran en el corazón de esta revolución, siendo capaces de comprender y generar texto con altísimo grado de sofisticación. Sin embargo, ejecutar estos modelos exige enormes recursos computacionales, lo que tradicionalmente ha implicado la dependencia de servidores en la nube. Con la llegada del Apple Neural Engine (ANE), se abre una nueva puerta para que estos potentes modelos funcionen directamente en dispositivos Apple, como iPhones, iPads y Macs, adecuándose a una era donde la privacidad, eficiencia energética y el rendimiento local son cruciales. Apple Neural Engine es un coprocesador especializado diseñado para acelerar operaciones de aprendizaje automático y procesamiento neuronal, integrado en los sistemas en chip (SoC) de Apple.
Este motor se enfoca en realizar tareas de inteligencia artificial de manera eficiente y rápida, aprovechando unidades específicas para cálculos tensoriales y operaciones de inferencia. Transformar grandes modelos de lenguaje para que puedan ejecutarse en esta arquitectura permite maximizar el desempeño de aplicaciones en el dispositivo, reduciendo latencias y evitando la necesidad de enviar datos sensibles a servidores externos. Uno de los proyectos más emblemáticos en este campo es ANEMLL, una iniciativa de código abierto que facilita la conversión, optimización y ejecución de modelos LLM directamente sobre Apple Neural Engine. Este proyecto ofrece un pipeline completo que abarca desde la conversión de modelos populares alojados en Hugging Face, tales como las variantes de LLaMA, hasta la entrega de ejemplos prácticos tanto en Swift para iOS/macOS como en Python para pruebas y desarrollo. ANEMLL provee una solución clave para desarrolladores que buscan integrar inteligencia artificial potente y autónoma en apps orientadas a asistentes personales, chatbots, herramientas de productividad y otras aplicaciones de borde.
La importancia de ejecutar LLMs de forma local en el dispositivo radica en varios aspectos fundamentales. En primer lugar, la privacidad: al procesar datos sensibles directamente en el hardware del usuario, se eliminan riesgos asociados con la transferencia o almacenamiento en la nube. Esto es especialmente relevante en sectores como salud, finanzas o comunicaciones donde la confidencialidad es crítica. Además, la independencia de conexión a internet potencia la experiencia del usuario en ambientes con conectividad intermitente o nula, aumentando la robustez y disponibilidad del sistema. En términos de rendimiento, el uso de ANE optimiza el consumo energético y acelera la inferencia, evitando los costos y latencias vinculadas a la computación remota.
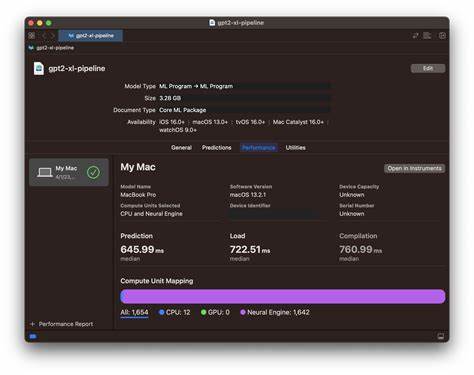
La ingeniería detrás de ANEMLL incluye herramientas para convertir pesos de modelos preentrenados a formatos CoreML compatibles, que son interpretados eficientemente por el motor neuronal de Apple. Aunque la versión actual se encuentra en fase alpha, soportando principalmente modelos de la serie LLaMA y sus distilados, anticipa un soporte progresivo para otras arquitecturas y optimizaciones de cuantisación con técnicas avanzadas. Para desarrolladores interesados, ANEMLL provee una serie de componentes útiles: scripts para la conversión inmediata del modelo, interfaces de línea de comandos en Swift para ejecutar inferencias, código ejemplo para integración en aplicaciones iOS/macOS y un entorno Python para pruebas rápidas y evaluación del rendimiento. Incluso existen aplicaciones piloto en TestFlight que permiten experimentar con chatbots corriendo completamente en ANE. La flexibilidad para usar Swift junto con la compatibilidad con modelos desde Hugging Face hace que la implementación sea accesible para distintos perfiles técnicos.
A nivel tecnológico, uno de los retos más complejos es la cuantización adecuada del modelo, es decir, la reducción del tamaño y precisión de los parámetros sin sacrificar notablemente la calidad de las respuestas generadas. Actualmente, la cuantización LUT4 presenta limitaciones debido a la ausencia de técnicas avanzadas de bloque cuantización específicas para ANE, aunque se espera que métodos como GPTQ y Spin Quant mejoren estos aspectos en el futuro cercano. El proyecto cuenta además con una suite de evaluación y benchmarking que mide la eficacia y rendimiento, ayudando a determinar configuraciones óptimas para cada caso de uso. Otro punto determinante es la integración nativa con tecnologías Apple, como CoreML y SwiftUI, lo que ofrece a los desarrolladores la oportunidad de crear interfaces altamente responsivas y modernas que exploten al máximo la GPU, CPU y ANE en conjunto. La ejecución híbrida permite que ciertos procesos se realicen en el motor neuronal mientras que otros pueden manejarse con el software tradicional, facilitando un equilibrio perfecto entre rapidez y funcionalidad.
La comunidad alrededor de ANEMLL, en constante crecimiento, contribuye activamente con mejoras, nuevos modelos y consultas. La colaboración con Hugging Face en la publicación de versiones preconvertidas optimiza el acceso a modelos listos para usarse y asegura una actualización permanente para beneficiar a desarrolladores y empresas. Además, la documentación detallada y los canales de soporte permiten un aprendizaje ágil para quienes desean incorporar estos avances en sus soluciones propias. En la actualidad, los requisitos para aprovechar al máximo ANEMLL incluyen dispositivos Apple que cuenten con una versión reciente de macOS o iOS que integren Apple Neural Engine, preferentemente con al menos 16GB de RAM para manejar los recursos demandados por los LLMs grandes. También es indispensable contar con las herramientas de desarrollo Xcode y sus complementos para CoreML, las cuales permiten compilar y validar los modelos optimizados para ANE.
El entorno virtual de Python se recomienda para mantener aisladas las dependencias y facilitar la gestión de paquetes durante la conversión y testeo. Conforme evolucione la capacidad del Apple Neural Engine y se perfeccionen las técnicas de compresión y cuantización, la ejecución de grandes modelos de lenguaje en el dispositivo promete expandir su alcance para incluir arquitecturas diversas, contextos más extensos y aplicaciones con mayor interacción en tiempo real. Esto abre un camino hacia tecnologías autónomas, seguras y con alto rendimiento embebidas directamente en nuestros dispositivos cotidianos. En síntesis, utilizar Apple Neural Engine para correr grandes modelos de lenguaje es un paso decisivo para modernizar aplicaciones con inteligencia artificial avanzada, garantizando rapidez, privacidad y eficiencia energética. Proyectos como ANEMLL demuestran que hacer LLMs accesibles en dispositivos Apple no es solo posible sino que está en constante desarrollo para cubrir las necesidades emergentes de usuarios y desarrolladores en el espacio de AI local.
Adaptarse a esta tendencia representa una ventaja competitiva significativa en el panorama tecnológico actual y futuro.