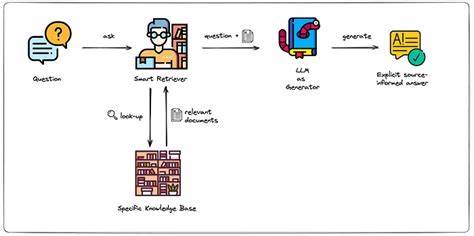
La evolución constante de la inteligencia artificial y las tecnologías basadas en el procesamiento de grandes volúmenes de datos ha llevado al auge de sistemas sofisticados como la Generación Aumentada por Recuperación (RAG, por sus siglas en inglés). Estos sistemas combinan técnicas avanzadas de recuperación de información y generación de contenido, permitiendo responder consultas complejas mediante fuentes de conocimiento extensas y variadas. Sin embargo, a medida que la cantidad y la diversidad de datos aumentan, surgen desafíos para organizar y gestionar adecuadamente estos insumos, siendo la segmentación de datos uno de los elementos más cruciales para garantizar la eficiencia y seguridad en estas arquitecturas. La segmentación de datos en sistemas RAG responde a una necesidad práctica: evitar que se mezclen informaciones que pertenecen a ámbitos o usuarios diferentes y asegurar que cada consulta sea respondida con la información más relevante posible. En ausencia de una segmentación adecuada, las búsquedas pueden generar respuestas incorrectas, arriesgando la privacidad y la satisfacción del usuario.
Esto sucede, por ejemplo, en plataformas SaaS que atienden a múltiples clientes, donde la mezcla de documentos o bases de conocimiento puede derivar en filtraciones de información confidencial. Al aplicar particiones lógicas en un sistema RAG, se crean límites que aíslan grupos de documentos según el dominio, cliente o cualquier criterio relevante. Esta práctica no solo protege los datos evitando el cruce no autorizado sino que también mejora la calidad de los resultados. Particularmente, en métodos híbridos de búsqueda que combinan índices semánticos y basados en palabras clave, la importancia relativa de cada término depende del corpus específico analizado. Cuando los documentos están segmentados correctamente, la métrica TF-IDF (Term Frequency-Inverse Document Frequency) puede ajustarse al contexto particular, lo que facilita identificar términos clave con mayor precisión y jerarquizar adecuadamente las respuestas.
La segmentación también es fundamental para manejar la heterogeneidad en la información procesada. Un sistema que alberga documentos legales no debe mezclar su contenido con políticas de recursos humanos o soporte al cliente. Al definir particiones para estos ámbitos, se garantiza que las búsquedas sean especializadas y que las respuestas reflejen el conocimiento adecuado para cada área, evitando ruido innecesario y mejorando la experiencia del usuario final. Un aspecto complementario esencial en la segmentación son los filtros basados en metadatos asociados a cada documento. Etiquetar cada registro con características como tipo de documento, fuente, identificador de usuario o atributos personalizados permite refinar las consultas dentro de las particiones.
Esta combinación de aislamiento por particiones y filtrado detallado posibilita un control granular sobre la recuperación de información, crucial para aplicaciones que implementan modelos robustos de control de acceso y seguridad, como el acceso basado en roles (RBAC). Además de la seguridad y relevancia, la segmentación impulsa la escalabilidad y el mantenimiento de los sistemas. Manejar grandes volúmenes de datos en un único conjunto puede complicar las actualizaciones, el monitoreo y la detección de anomalías. Separar las bases de conocimiento facilita estas tareas y optimiza el rendimiento general porque los procesos de indexación y recuperación se enfocan en subconjuntos específicos, reduciendo la carga computacional y acelerando las respuestas. Diversas plataformas y herramientas dedicadas a RAG están integrando soporte nativo para segmentación, reconociendo su importancia estratégica.







![Statistics for Hackers (2016) [video]](/images/63EA424A-AA4D-42D8-99CD-E748658800EE)
