La gestión y el almacenamiento de datos han sido pilares fundamentales en el desarrollo de sistemas y aplicaciones a lo largo de las últimas décadas. Desde los inicios con bases de datos relacionales hasta la proliferación de soluciones NoSQL, la misión ha sido siempre la misma: almacenar datos de manera eficiente y ofrecer mecanismos para su consulta y manipulación. Sin embargo, a pesar de la evolución tecnológica, las bases de datos tradicionales mantienen un modelo conceptual basado en un estado mutable, compartido y global, que, aunque funcional, presenta limitaciones claras cuando se trata de soportar la complejidad y el volumen que demanda hoy el procesamiento de datos en tiempo real. Aquí es donde Apache Samza irrumpe con una propuesta disruptiva que revela un nuevo enfoque para pensar y construir sistemas de datos modernos. Apache Samza es un framework distribuido de procesamiento de streams desarrollado inicialmente en LinkedIn que enfatiza la importancia de transformar paradigmáticamente la gestión del estado en aplicaciones distribuidas.
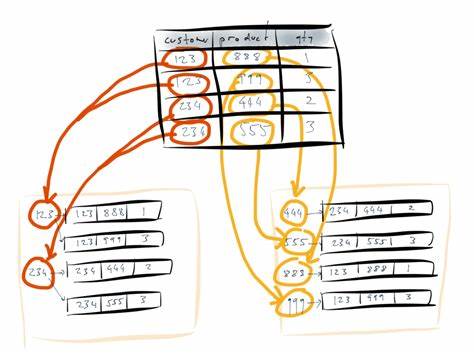
En lugar de tratar la base de datos como un espacio mutable al que múltiples instancias de aplicaciones leen y escriben, Samza propone convertir la base de datos en un flujo continuo de eventos inmutables que capturan hechos sucedidos en un instante determinado. Esta transformación, a la que se refiere como “volver la base de datos del revés”, implica que la fuente de verdad real no es el estado actual en una tabla o colección de datos, sino un registro explícito y completamente histórico de cada cambio ocurrido. En el modelo tradicional, cuando una aplicación actualiza una cantidad en el carrito de compras de un cliente, esa operación se traduce en una consulta imperativa que altera directamente el estado almacenado. Sin embargo, las réplicas y los mecanismos de sincronización internos de la base de datos, como los logs de replicación, en realidad preservan una serie de indicios inmutables: registros que reflejan que en determinado momento un cliente modificó la cantidad de un producto. Esta secuencia de eventos independientes y permanentes representa una mina de información, aportando no solo el estado actual, sino también todo el contexto del historial de cambios, situación que el modelo tradicional suele ignorar al sobrescribir los valores anteriores.
En este sentido, el enfoque de Samza se apoya en un commit log distribuido y durable, construido sobre Apache Kafka, que actúa como el repositorio central y apéndice de todos los eventos que describen las evoluciones del sistema. Kafka garantiza que estos eventos sean almacenados de manera confiable, replicando la información a través de diferentes nodos y proporcionando alta disponibilidad y escalabilidad. Lo importante aquí es reconocer el cambio de paradigma: los datos no son simplemente almacenados para ser leídos, sino que se generan como una corriente continua de hechos que se procesan y transforman para construir vistas materiales especializadas. El concepto de vistas materiales o materialized views en este contexto es fundamental. En lugar de consultar directamente la base de datos central o intentar mantener cachés complejos y propensos a errores en el nivel de aplicación, Samza permite construir dichas vistas a partir del flujo de eventos capturado en Kafka.
Luego, estas vistas sirven como índices o almacenes optimizados para lectura, que se actualizan automáticamente a medida que llegan nuevos eventos, garantizando coherencia, reducción de latencias y minimización de complejidades operativas. Esta metodología resuelve problemas que son notorios en esquemas tradicionales. Por ejemplo, la invalidación de cachés en aplicaciones es un dolor de cabeza recurrente. Cuando el estado base cambia, se vuelve extremadamente difícil asegurar que todos los niveles intermedios de caché se actualicen de forma correcta y oportuna, lo que conduce a condiciones de carrera, posibles errores de consistencia y contingencias en el rendimiento. La lógica compleja para manejar estas invalidaciones suele ser dispersa y difícil de mantener.
Al adoptar una arquitectura en la que el registro del estado es un flujo inmutable de eventos y las vistas materializadas se actualizan de forma autónoma a partir de él, se erradica gran parte de estos problemas. Otra ventaja destacable de trabajar con eventos inmutables y flujos continuos es la capacidad que ofrece para la resiliencia y recuperación ante errores. Dado que todos los cambios están registrados en un log inalterable, es posible reproducir toda la historia del sistema, analizar cambios pasados, realizar auditorías detalladas y, si es necesario, corregir errores reinterpreting el flujo desde algún punto previo. Esta característica no solo aporta transparencia, sino que también abre la puerta a nuevas estrategias de recuperación y mejora continua que no son factibles cuando se sobrescriben estados sin dejar rastro. También es importante mencionar el impacto que tienen estas ideas en la arquitectura general de aplicaciones.
Tradicionalmente, las aplicaciones web y móviles se construyen con un modelo de backend stateless que depende exclusivamente de una base de datos mutable para manejar el estado. Aunque esta aproximación facilita la escalabilidad horizontal y la disponibilidad, introduce una dependencia crítica en un estado global mutable, que no solo es un cuello de botella en términos de concurrencia y rendimiento, sino que también complica la evolución ágil de aplicaciones. Al desacoplar las operaciones de escritura —que simplemente convierten las acciones en eventos append-only— de las lecturas —que consumen vistas materializadas especializadas—, Apache Samza facilita la creación de sistemas más flexibles. De esta manera, si se desea implementar una nueva funcionalidad que requiere una vista diferente sobre los datos, basta con construir un nuevo job de procesamiento en Samza que consuma el log desde el inicio y construya la vista requerida, sin afectar la integridad del sistema ni los procesos existentes. Esto reduce drásticamente la necesidad de realizar migraciones abortivas y permite experimentar con nuevas características de forma incremental y controlada.
Además, el ecosistema que rodea Apache Samza y Kafka permite manejar cargas gigantescas de datos con una consistencia estricta y baja latencia, siendo capaz de atender millones de eventos por segundo con relativa facilidad. Esto coloca a esta tecnología en una posición ideal para aplicaciones modernas que requieren datos en tiempo real, como análisis de comportamiento, sistemas de recomendación, detección de fraudes y otras soluciones centradas en el usuario. Otro aspecto revolucionario de este enfoque es la integración natural con modelos de interacción entre cliente y servidor más reactivos y dinámicos. En lugar del tradicional modelo request-response, los clientes pueden suscribirse a las actualizaciones de datos en las vistas materializadas, recibiendo notificaciones y actualizaciones automáticas en cuanto los datos cambian. Este patrón potencia el desarrollo de interfaces de usuario altamente responsivas y sincronizadas, con una arquitectura de backend que soporta de forma nativa la reactividad inherente al mundo actual conectado y en flujo constante.
Es cierto que este tipo de arquitectura, basada en eventos inmutables y procesamiento de streams, es un cambio cultural y tecnológico profundo respecto a las prácticas establecidas. Supone un replanteamiento del diseño de bases de datos, del manejo de transacciones y de la integración entre componentes. Sin embargo, el crecimiento en el soporte de herramientas especializadas, comunidades activas y la adopción creciente en la industria muestran que esta revolución ya está en marcha y presenta un camino sostenible para enfrentar las necesidades del futuro. En conclusión, Apache Samza representa una evolución significativa en el diseño de sistemas de datos y bases de datos, impulsando paradigmas que aprovechan la inmutabilidad, el procesamiento en tiempo real y las vistas materializadas actualizadas continuamente para ofrecer soluciones más escalables, robustas y flexibles. Al entender la base de datos no solo como un repositorio estático de estado mutable, sino como un flujo dinámico de hechos inmutables, los desarrolladores pueden construir aplicaciones más coherentes, capaces de evolucionar con agilidad y optimizadas para el mundo digital altamente distribuido y conectado en que vivimos.
Esta transformación invita a repensar los sistemas y abre un abanico de posibilidades donde los datos no solo son almacenados, sino también interpretados y enriquecidos en cada etapa de su ciclo de vida, permitiendo que las organizaciones extraigan valor en tiempo real y respondan con efectividad ante un entorno en constante cambio.