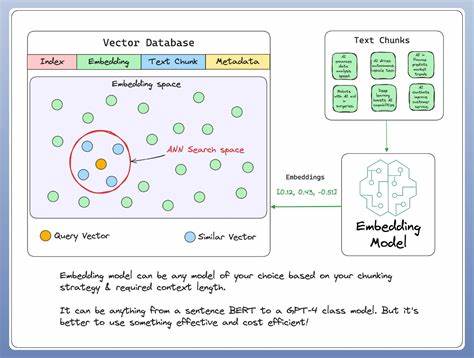
En la era actual dominada por la inteligencia artificial, los modelos de embeddings se han convertido en una pieza fundamental para mejorar la precisión y relevancia en la recuperación de información. El año 2025 presenta un panorama alentador donde nuevas tecnologías y avances revolucionarios consolidan a estos modelos como la base para sistemas de búsqueda inteligentes, capaces de interpretar y asociar datos con un nivel de entendimiento semántico excepcionalmente superior. A medida que la cantidad de información digital crece exponencialmente, la necesidad de sistemas eficientes que transformen datos complejos en vectores manejables y comparables se vuelve indispensable para empresas y desarrolladores. Los modelos de embeddings, que convierten texto, imágenes y otros formatos en representaciones vectoriales numéricas, permiten medir la similitud y relevancia entre elementos con una precisión que anteriormente solo era posible en entornos humanos. En este sentido, 2025 destaca por la aparición de modelos de última generación, tanto propietarios como de código abierto, que se están posicionando como líderes en la fase de recuperación de información, escenario donde cada fracción de mejora en la relevancia puede marcar la diferencia en la experiencia del usuario y la eficiencia operativa.
De entre las novedades sobresale Voyage-3-large, un modelo que ha causado gran sorpresa y entusiasmo en la comunidad por su excepcional rendimiento en relevancia semántica. Aunque OpenAI ha sido un referente natural con sus modelos text-embedding-3 que datan de 2023, estos se han quedado atrás debido al vertiginoso ritmo de innovación. El modelo Voyage-3-large supera consistentemente a sus competidores en pruebas y benchmarks recientes, demostrando una capacidad sin precedentes para entender y procesar diferentes idiomas y contextos. Actualmente, en la industria, los modelos como Gemini, OpenAI y otros proveedores exitosos como Jina, Cohere y Voyage, presentan distintas propuestas en cuanto a tamaño, estructura y licencias de uso, lo que abre un abanico amplio para seleccionar el embeding que mejor se adapte a necesidades específicas. En paralelo, emergen modelos open source como Stella y ModernBERT Embed, que ganan terreno gracias a su flexibilidad, posibilidades de personalización y licenciamiento más permisivo.
El tamaño y las dimensiones de salida del vector que produce cada modelo también son conscientes factores en la selección. Por ejemplo, OpenAI text-embedding-3-large puede generar vectores con hasta 3.072 dimensiones, mientras que otros modelos como Gemini cuentan con representaciones más compactas de 768 dimensiones. Esta característica tiene impacto directo en la velocidad y escalabilidad de las búsquedas vectoriales; los vectores más pequeños permiten consultas más rápidas y un uso eficiente del almacenamiento, aunque en algunos casos podría existir una pérdida mínima de información semántica. Un aspecto innovador en varios modelos de vanguardia es el uso de técnicas Matroyshka, las cuales están diseñadas para priorizar la información más relevante en las primeras dimensiones del vector.
Este diseño permite truncar vectores sin sacrificar demasiado la comprensión semántica, práctica que beneficia en términos de costo computacional y rendimiento en sistemas con limitaciones de recursos. El uso de conjuntos de datos desafiantes y menos convencionales para evaluar estos modelos ha sido una estrategia clave para obtener mediciones realistas y útiles. Se han empleado benchmarks basados en OCR aplicado a conjuntos de imágenes, que contienen textos escaneados provenientes de idiomas como el francés y el inglés. Este enfoque elimina el sesgo hacia modelos entrenados solo en corpus comunes y permite evaluar la verdadera capacidad de generalización y adaptabilidad de cada embedding. El costo también es un componente esencial a la hora de elegir un modelo de embedding para recuperar información.
Aunque el rendimiento es primordial, el costo por consulta o por parámetro afecta directamente la viabilidad práctica para empresas que manejan grandes volúmenes de datos o requieren respuesta en tiempo real. En esta ecuación, modelos como Voyage-3-lite se destacan por ofrecer un balance casi ideal entre costo y rendimiento, alcanzando niveles cercanos a los modelos de OpenAI pero a una fracción del precio y con vectores más livianos. Por otro lado, los modelos open source Stella, diseñados principalmente por un único desarrollador, emergen como una opción mu robusta y altamente competitiva, especialmente atractiva para proyectos con presupuesto limitado que desean además poder ajustar y afinar el modelo para tareas específicas. A pesar de su tamaño relativamente pequeño, Stella ofrece resultados sorprendentes en benchmarks de recuperación de información y demuestra que la calidad también puede ser producto de la innovación individual. En contraste, la familia de modelos ModernBERT, basada en la arquitectura BERT optimizada para velocidad y precisión, ha mostrado resultados discretos en las pruebas recientes, sin alcanzar la misma consistencia ni excelencia que sus contrapartes.
Esto indica que quizá será necesario que sus próximas versiones incorporen mayores avances para competir en un mercado cada vez más exigente. Un dato importante para los usuarios que trabajan con datos multilingües es la ausencia de modelos asentados exclusivamente en inglés en algunos escenarios. Por ejemplo, algunas variantes de ModernBERT y Gemini están entrenadas sólo en inglés, lo que limita su desempeño en contextos multilingües o en contenidos con información en lenguas como el francés, mientras que Voyage, Stella y otros han desarrollado capacidades pluriidiomáticas robustas. Desde la perspectiva del desarrollador y profesional de tecnología, la elección del modelo de embedding es un proceso que debe considerar cuidadosamente el equilibrio entre precisión, costo, velocidad y capacidad multilingüe para lograr la mejor experiencia de usuario y la máxima eficiencia. La tecnología evoluciona rápidamente y mantenerse actualizado con las últimas referencias y benchmarks se vuelve indispensable para no quedar rezagados en un mercado competitivo.
En cuanto a las aplicaciones, los modelos de embedding juegan un papel decisivo en diversas áreas que van desde motores de búsqueda avanzados, sistemas de recomendación, chatbots respondiendo preguntas complejas gracias a sistemas de recuperación aumentada (RAG), hasta análisis de grandes volúmenes de documentos empresariales o legales donde la precisión en la interpretación semántica marca la diferencia. El futuro de la recuperación de información se vislumbra aún más prometedor con la integración de estos modelos en arquitecturas de inteligencia artificial cada vez más sofisticadas y escalables, soportadas por plataformas en la nube y hardware optimizado para tareas de aprendizaje automático. También va ganando tracción la posibilidad de ajustar y personalizar modelos open source para dominios específicos, lo que abre la puerta a soluciones hiperadaptadas para industrias particulares. En conclusión, el año 2025 representa una etapa clave en la evolución de los modelos de embeddings para la recuperación de información. Modelos como Voyage-3-large marcan un nuevo estándar en precisión, mientras opciones económicas y open source como Voyage-3-lite y Stella ofrecen alternativas viables para diferentes tipos de proyectos y presupuestos.
La combinación de innovación técnica, evaluación con datasets poco tradicionales y un enfoque centrado en el balance costo-beneficio hacen que la recuperación de información a base de embeddings sea una solución cada vez más sólida y universal en el mundo de la inteligencia artificial y el procesamiento del lenguaje natural. Quienes estén involucrados en el desarrollo de sistemas de búsqueda, inteligencia artificial aplicada y gestión avanzada de datos deben sin duda considerar estas tendencias para mantenerse a la vanguardia y ofrecer experiencias de usuario superiores en sus aplicaciones. La tecnología está en constante movimiento y la llegada de estos nuevos modelos abre un abanico de posibilidades que aún están por descubrirse en los próximos años.