En la era digital actual, la cantidad de información académica disponible es abrumadora, y la eficiencia en el manejo y análisis de esta información se ha convertido en un factor crucial para investigadores y estudiantes. Frente a este desafío, surgen soluciones tecnológicas innovadoras, siendo una de las más prometedoras los agentes de investigación asistidos por inteligencia artificial (IA) diseñados con arquitectura event-driven o basada en eventos. Este artículo explora en detalle cómo se puede desarrollar un asistente de investigación desde cero utilizando esta tecnología, con el fin de facilitar el procesamiento avanzado de literatura científica y potenciar la productividad investigativa. La arquitectura event-driven es una metodología de diseño de sistemas en que las acciones se desencadenan en respuesta a eventos específicos que suceden dentro del flujo del programa o en su entorno externo. Esta característica resulta especialmente útil para asistir en procesos complejos, como el análisis de artículos académicos, porque permite organizar el flujo del trabajo en módulos independientes y altamente especializados que responden a las distintas fases del análisis, desde la carga inicial del documento hasta la generación de reportes y visualizaciones interactivas.
El agente inteligente para asistir en la investigación, apoyado por esta arquitectura, se fundamenta en la integración de modelos de IA avanzados, siendo en este caso ejemplar el modelo Gemini 2.5 Pro de Google, el cual posee capacidades destacadas en procesamiento de lenguaje natural y extracción de información semántica. Mediante el uso de este modelo, el sistema puede analizar documentos extensos y complejos, identificar conceptos clave, generar resúmenes precisos, así como evaluar el impacto científico y sugerir nuevas líneas de investigación. El flujo de trabajo típico inicia con la carga de un artículo académico, que incluye metadatos esenciales como título, autores, resumen, enlace al PDF y DOI. Esta información es el punto de partida para que el agente comience el proceso de extracción de texto, que aunque simulado inicialmente para fines demostrativos, está diseñado para integrar en el futuro módulos reales de análisis de PDF que permitan procesar figuras, tablas y otras representaciones no textuales.
Posteriormente, el sistema ejecuta un análisis exhaustivo del contenido, desglosando la información en distintas capas de conocimiento. Una primera tarea es generar un resumen condensado que mantenga la esencia y la lógica del estudio, facilitando así la comprensión rápida y efectiva para cualquier usuario que consulte el documento mediante el sistema. A continuación, se realiza la extracción de conceptos y términos técnicos con descriptores, destacando el vocabulario relevante para el área de estudio. Esta capacidad de identificación semántica es fundamental para construir una base de datos coherente y enriquecida. Un aspecto innovador del agente es la evaluación del impacto investigativo que permite descubrir la significancia del trabajo dentro de su campo, analizando su nivel de innovación, relevancia y posibles aplicaciones prácticas.
A partir de esta evaluación, el sistema también realiza un análisis de los vacíos en la investigación, identificando áreas poco exploradas o con limitaciones metodológicas que representan oportunidades para profundizar o expandir el conocimiento existente. En un mundo científico que evoluciona rápidamente, otro componente valioso es la recomendación automatizada de artículos relacionados, una función que implementa búsquedas inteligentes en internet y bases de datos académicas. De esta manera, los usuarios obtienen acceso inmediato a literatura complementaria, fomentando la conexión entre diferentes investigaciones y el pensamiento crítico interdisciplinario. La gestión del conocimiento no termina en la simple recopilación de datos, sino que el agente también construye un grafo de conocimiento interactivo que visualiza las relaciones entre documentos, conceptos y autores. Esta representación gráfica permite a los investigadores navegar intuitivamente dentro del corpus de información y detectar patrones o conexiones que podrían no ser evidentes mediante la lectura tradicional.
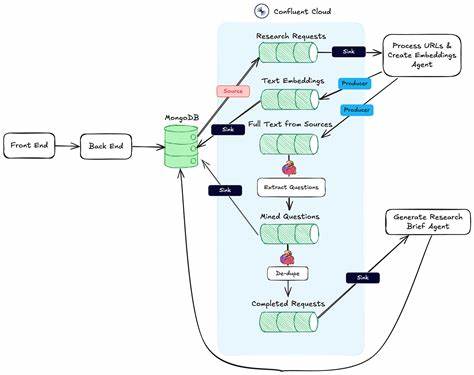
Para facilitar la consumición del conocimiento generado, el asistente cuenta con una función para producir reportes en formato markdown, los cuales son amigables y legibles, y pueden integrarse en documentos académicos o presentaciones. La capacidad para consultar el grafo mediante conceptos o identificadores específicos ofrece una flexibilidad única y potencia la exploración profunda sin perder el foco. Desde la perspectiva técnica, la implementación del sistema destaca por su modularidad y robustez. Los endpoints API diseñados permiten la interacción fluida con servicios externos y el control sobre etapas clave como la carga de papers, la consulta de conceptos o la obtención de detalles específicos de documentos. Gracias al sistema event-driven, cada componente opera de manera desacoplada, recibiendo, procesando y emitiendo eventos que desencadenan acciones posteriores, lo que favorece la escalabilidad y el mantenimiento del software.
Asimismo, la integración con Google Gemini 2.5 Pro asegura que todas las tareas complejas de análisis semántico, extracción de información estructurada y generación de contenido sean realizadas con alta precisión y rapidez. Los mecanismos integrados para la gestión de errores y la interpretación de respuestas semi-estructuradas garantizan la confiabilidad en escenarios reales, donde la calidad de los textos o la heterogeneidad de los datos pueden presentar desafíos. La plataforma también está preparada para ser ampliada y perfeccionada. Entre las mejoras futuras contempladas destaca la inclusión de bibliotecas especializadas para el parsing real de PDFs, el uso de bases de datos no relacionales o graficadas para almacenar el grafo de conocimiento y la incorporación de actualizaciones en tiempo real mediante WebSocket, las cuales permitirían un seguimiento instantáneo del progreso en el análisis.
La experiencia de usuario se ve enriquecida con una interfaz web diseñada para subir documentos, visualizar resultados, explorar el grafo y generar reportes de manera intuitiva. Esta interfaz también puede ser una puerta para futuros desarrollos colaborativos y funciones de autenticación, dando lugar a un entorno personalizado y seguro para equipos de investigación. Por otra parte, el sistema es un ejemplo sobresaliente del potencial del uso de inteligencia artificial en la academia, mostrando cómo es posible automatizar procesos que tradicionalmente podían ser tediosos y lentos, sin sacrificar profundidad ni calidad en el análisis. Esto permite que los investigadores dediquen más tiempo a la interpretación crítica y al diseño de nuevas hipótesis. En resumen, el desarrollo de un agente de investigación basado en arquitectura event-driven y potenciado por inteligencia artificial como Gemini 2.
5 Pro representa un avance significativo en la forma de manejar, analizar y organizar el conocimiento académico. Este enfoque no solo mejora la eficiencia sino que también fomenta la innovación y colaboración en entornos científicos, ayudando a acelerar la generación de nuevas ideas y el progreso del conocimiento. A medida que la tecnología avanza, la convergencia entre IA y metodologías orientadas a eventos promete transformar radicalmente no solo la investigación académica sino otros campos del saber que requieren procesamiento intensivo de datos semi-estructurados y toma de decisiones complejas. Este tipo de asistentes inteligentes se posicionan como aliados imprescindibles en la era del conocimiento, facilitando un acceso más rápido, profundo y organizado a la información crucial para el desarrollo científico y tecnológico.