El aprendizaje en grafos se ha consolidado como una de las ramas más prometedoras de la inteligencia artificial, especialmente para modelar datos estructurados e interconectados que se encuentran en multitud de dominios como recomendaciones, detención de fraudes y análisis de redes sociales. Sin embargo, estos modelos suelen requerir un elevado poder computacional y presentan desafíos en términos de velocidad y eficiencia cuando se entrenan a escala real. En este contexto, la combinación de PyTorch Geometric (PyG) y la función torch.compile incorporada en PyTorch 2.0 ofrece una puerta para acelerar considerablemente el entrenamiento sin comprometer la calidad de los resultados.
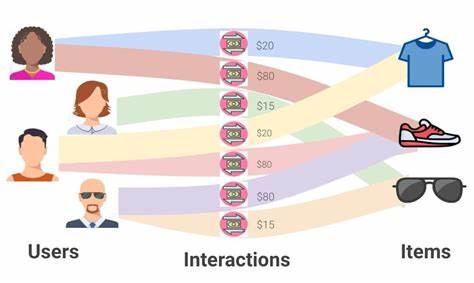
A continuación, exploramos a fondo cómo utilizar estas herramientas para mejorar el rendimiento de modelos avanzados de aprendizaje profundo en grafos. El aprendizaje profundo relacional (Relational Deep Learning) es un enfoque que integra técnicas de deep learning con razonamiento relacional para capturar las dependencias y conexiones complejas entre entidades de datos representadas en forma de grafos heterogéneos. Mediante la construcción de estructuras que integran múltiples tipos de nodos (por ejemplo, usuarios, interacciones y productos), este paradigma aprovecha patrones de conectividad y diversidad multimodal de características para potenciar la capacidad predictiva de las redes neuronales. PyG, como herramienta especializada para trabajar con grafos en PyTorch, facilita la implementación de estos modelos, proporcionando bloques optimizados para el paso de mensajes entre nodos. PyTorch ha sido la base fundamental para esta solución debido a su modo eager, que permite flexibilidad durante el desarrollo y depuración de arquitecturas complejas.
No obstante, cuando el enfoque se traslada a producción, la relevancia de optimizar el rendimiento se intensifica, tanto desde la perspectiva del tiempo de entrenamiento como de la gestión eficiente de los recursos. La aparición de torch.compile en PyTorch 2.0 representa un avance crucial, ofreciendo la posibilidad de convertir modelos definidos en modo eager en kernels compilados just-in-time (JIT) con optimizaciones automáticas, a través de una envoltura sencilla que no demanda cambios significativos en el código fuente. Esta compilación transforma las operaciones en secuencias más rápidas y reduce el overhead de ejecución, aunque también puede presentar ciertos retos que deben ser gestionados para explotar todo su potencial.
Uno de los mayores retos identificados al usar torch.compile en modelos de aprendizaje en grafos es la aparición de recompilaciones innecesarias. PyTorch, al registrar ciertos supuestos relacionados con dimensiones o valores constantes, recompila la zona afectada si detecta cambios en tales supuestos. En modelos con grafos heterogéneos, las entradas varían en tamaño debido a la naturaleza dinámica del muestreo de vecinos y el manejo de mini-batches de subgrafos. Para mitigar esto, es recomendable activar explícitamente la opción dynamic=True en torch.
compile para optimizar el modelo para formas dinámicas, lo que evita recompilaciones frecuentes y costosas durante el entrenamiento. Además, otro caso notable ocurre con el uso de schedulers en el optimizador. torch.compile puede asumir que la tasa de aprendizaje es una constante, y si esta cambia como parte del scheduling, provoca recompilaciones. La solución efectiva es definir la tasa de aprendizaje como un tensor, lo que previene invalidaciones de supuestos y mantiene la compilación estable.
Otra problemática relevante son las rupturas de grafo ('graph breaks'), fenómenos donde el compilador no puede fusionar las operaciones en un solo gráfico de cómputo. Esto perjudica la optimización porque implica movimientos adicionales de datos y pérdida de la ejecución asincrónica óptima en GPU. Detectar estas rupturas es posible utilizando herramientas de logging como TORCH_LOGS=graph_breaks. En muchos casos, corregir rupturas consiste en modificar pequeños detalles del código, como sustituir claves compuestas por cadenas simples al acceder a diccionarios, un cambio que evita operaciones incompatibles con la compilación continua. Trabajar estas rupturas mejora la fluidez y la velocidad del modelo compilado.
La utilización de CUDA Graphs representa una propuesta atractiva para minimizar la sobrecarga en el lanzamiento de kernels GPU al agrupar varias operaciones en un único lanzamiento por CPU. Aunque PyTorch ya permite el uso de CUDA Graphs en entornos con formas dinámicas usando torch.compile(mode='reduce-overhead'), su efectividad se limita a casos donde la variabilidad de la forma es reducida. Para modelos que procesan subgrafos con tamaños altamente variables, habilitar CUDA Graphs puede ser contraproducente debido a la necesidad de grabar y reproducir grafos múltiples veces, lo que incrementa el consumo de memoria y ralentiza la ejecución. Por ello, su uso debe valorarse según las características particulares del problema.
Un aspecto crítico que influye en la eficiencia es la sincronización entre CPU y GPU. La programación en PyTorch es mayormente asincrónica, lo que permite al CPU enviar múltiples kernels al GPU sin esperar a que terminen. Sin embargo, ciertas operaciones obligan a esperar a que el GPU complete tareas para transferir datos al host, lo que genera pausas y reduce el throughput. Ejemplos comunes que provocan estas sincronizaciones innecesarias incluyen llamadas a .item() o conversiones explícitas del tensor a tipo float.
La práctica recomendada es conservar los cálculos y acumulaciones dentro del dispositivo (GPU), postergando el movimiento de datos hacia el CPU hasta el momento estrictamente necesario, preferiblemente al final del entrenamiento o evaluación. También conviene revisar funciones que no parecen problemáticas a simple vista, como torch.repeat_interleave, la cual puede desencadenar sincronizaciones si no se controla correctamente mediante parámetros adecuados. Adicionalmente, mantenerse actualizado con las últimas versiones tanto de PyTorch como de sus complementos como PyG o torchmetrics resulta vital para sacar partido de las constantes mejoras en compatibilidad y rendimiento que se incorporan. Estas actualizaciones aportan correcciones a problemas recurrentes como excesivas recompilaciones, rupturas de gráfico y sincronizaciones invisibles, facilitando una integración más fluida con torch.
compile y optimizaciones de hardware recientes. En experimentos realizados con datasets reales, como el desafío de recomendación de Kaggle de H&M, la utilización de torch.compile en combinación con PyG demostró mejoras en la velocidad de entrenamiento de entre un 30% a 35% sin sacrificar la precisión de los modelos. Se trabajó sobre diferentes tareas como clasificación de nodos para predecir abandono de usuarios, regresión para estimar ventas y predicción de enlaces para anticipar compras. Este progreso confirma la viabilidad de llevar modelos complejos y adaptativos a producción con una eficiencia mucho mayor mediante la adopción de estas técnicas.