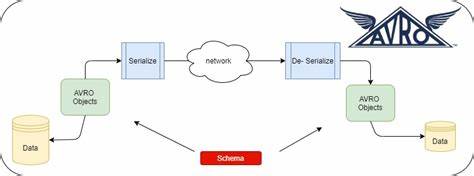
La tecnología Avro es una pieza fundamental en el ecosistema de Apache Kafka y en la gestión de datos serializados en múltiples sistemas actuales. Sin embargo, a pesar de su popularidad y eficiencia, los mensajes de error que genera pueden ser crípticos y difíciles de interpretar, lo que representa un obstáculo considerable para desarrolladores y arquitectos de datos que trabajan con esquemas complejos o datos genéricos. Ante esta problemática surge avro-explain, una biblioteca de Java que mejora de manera significativa la claridad y utilidad de los mensajes de error que provienen del uso de Avro. Esta solución ha sido desarrollada en un entorno productivo y abierta para la comunidad, con la intención de facilitar la vida a quienes manejan datos estructurados con Avro. Para comprender la importancia de avro-explain es necesario sumergirse primero en la naturaleza del problema.
Cuando Avro detecta una incompatibilidad en el tipo de dato o falta algún campo esperado según el esquema, típicamente arroja un error que puede parecer técnico y poco explícito, por ejemplo: "Expected start-union. Got VALUE_NUMBER_INT". Frases como esta, aunque útiles para máquinas, ofrecen muy poca ayuda práctica al desarrollador para identificar dónde se originó el problema en la estructura anidada de sus datos o qué significa realmente en términos comprensibles. Esta dificultad se complica aún más cuando se trabaja con esquemas que contienen uniones (unions) o campos opcionales con valores por defecto. Avro-explain ha sido diseñado para abordar precisamente este desafío, ofreciendo un método simple y poderoso: org.
clojars.mjdrogalis.avroexplain.ExplainAvro/explain(). Esta función realiza una exploración profunda y detallada tanto del esquema como de los datos, detectando las inconsistencias y regresando un objeto explicado con información relevante y fácilmente entendible.
El resultado se traduce en mensajes que aclaran la causa raíz del error, indican la ubicación exacta dentro del esquema y del conjunto de datos donde ocurre la discrepancia, y describen en lenguaje claro qué debe corregirse. Los desarrolladores se benefician en gran medida al poder ver no solo qué tipo de error ocurrió, sino también qué dato específico en qué parte del esquema provocó la falla. Esto permite una depuración rápida y precisa de problemas, ahorrando horas de frustración y revisiones extensas de código. Además, avro-explain proporciona enlaces directos a discusiones enriquecedoras y explicativas en plataformas como Stack Overflow para profundizar en aspectos como el manejo apropiado de uniones o la configuración correcta de campos con valores predeterminados. La instalación e integración del paquete es bastante sencilla y se encuentra disponible en el repositorio de Clojars, lo que facilita su incorporación en cualquier proyecto Java que utilice Avro.
Añadir la dependencia en el archivo de configuración y llamar al método explain con el esquema y datos es todo lo que se necesita para empezar a obtener mensajes de error altamente informativos. Un caso práctico muy ilustrativo es el manejo de esquemas que utilizan uniones para permitir que un campo pueda tomar diferentes tipos de datos, como null o un tipo primitivo. En escenarios comunes, puede suceder que el dato proporcionado no incluya una pista clara para distinguir qué rama de la unión debe usarse, provocando mensajes poco claros. Avro-explain traduce este problema en una explicación detallada y en lenguaje accesible, señalando que falta la indicación necesaria y ofreciendo recursos para aprender a solucionarlo. Considerando que el trabajo con esquemas Avro forma parte diaria de arquitectos de datos y desarrolladores en empresas que manejan flujos masivos de información en tiempo real, la relevancia de disponer de herramientas que ayuden a entender mejor los errores no puede subestimarse.
La mejora en los mensajes facilita la confianza en la calidad de los datos y reduce tiempos muertos en la implementación y mantenimiento de pipelines de datos. Además, al desplegar avro-explain en entornos productivos, como lo ha hecho su creador en una empresa activa del sector de tráfico de datos llamado ShadowTraffic, se demuestra su robustez y confiabilidad. Esto ofrece garantías para su adopción en ambientes críticos donde la estabilidad y trazabilidad son fundamentales. Avro-explain cubre un nicho específico pero crucial dentro del manejo de datos serializados, un área en constante crecimiento debido a la explosión de sistemas distribuidos, IoT y análisis en tiempo real. En este contexto, la precisión en la identificación y explicación de errores es una ventaja competitiva que impacta directamente en la eficiencia operativa y en la calidad del desarrollo.
En conclusión, avro-explain no es solo una mejora estética en los mensajes de error, sino una herramienta transformadora que potencia el uso de Avro al hacer que sus errores sean comprensibles, contextualizados y accionables. Su enfoque en el detalle, con la capacidad de exponer la porción exacta del esquema y de los datos donde ocurre el problema, convierte el doloroso proceso de depuración en una experiencia mucho más fluida y rápida. Para quienes trabajan con datos estructurados en sistemas basados en Avro y buscan optimizar su flujo de trabajo, avro-explain representa una inversión imprescindible que aporta claridad, eficiencia y un menor margen de error. Su código abierto y su presencia en Mercados públicos facilitan su acceso y contribución desde la comunidad, consolidándose como una herramienta valiosa en el ecosistema moderno de datos. El futuro promete incluso más mejoras en este ámbito, y herramientas como avro-explain marcan el camino hacia desarrollos más inteligentes, facilitados y con menos fricciones en la gestión de datos complejos.
Integrar soluciones que expliquen claramente los errores es un paso fundamental para democratizar el acceso a tecnologías avanzadas y acelerar avances en la ciencia y arquitectura de datos.