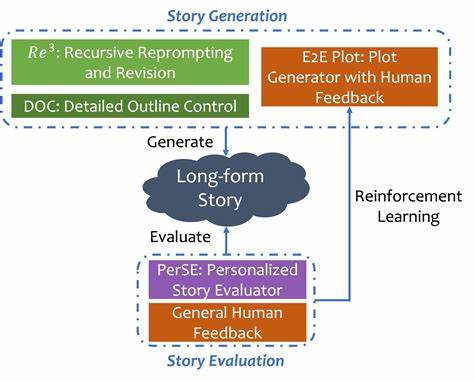
En la era actual de la inteligencia artificial, los modelos de lenguaje han avanzado a pasos agigantados, permitiendo la creación de textos cada vez más elaborados y extensos. Sin embargo, la generación automática de historias largas sigue siendo un desafío complejo, puesto que requiere mantener la coherencia narrativa, desarrollar arcos argumentales sólidos y presentar personajes profundos a lo largo de miles de tokens. Frente a estos retos, el enfoque VR-CLI (Verifiable Rewards via Completion Likelihood Improvement) emerge como una solución innovadora que impulsa la capacidad de razonamiento en modelos generativos para lograr relatos más ricos y consistentes. La generación narrativa a gran escala implica más que simplemente encadenar frases o párrafos; demanda una batería de habilidades cognitivas, similares a las que posee un escritor humano. Es necesario gestionar la trama, realizar un seguimiento de los personajes y sostener un estilo atractivo y constante.
Tradicionalmente, los modelos de lenguaje grandes (LLMs) usaban técnicas de incitación manual para simular comportamientos de autoría, pero estos métodos resultan limitados porque no generalizan bien a diferentes tipos de historias y generan resultados variables según la tarea específica. Por ello, la investigación ha intentado incorporar métodos de aprendizaje por refuerzo (RL) para entrenar a los modelos en base a señales de recompensa que reflejen criterios de calidad. En campos como la matemática o la programación, esta integración ha tenido éxito debido a la existencia de funciones de recompensa bien definidas y verificables. Inspirándose en estos avances, VR-CLI aplica un enfoque similar para la generación de capítulos consecutivos en historias largas, proponiendo un nuevo marco denominado predicción del siguiente capítulo. La idea principal detrás de VR-CLI es aprovechar un conjunto vasto de libros no etiquetados para aprender patrones de razonamiento que ayuden a planificar el desarrollo narrativo.
En lugar de depender de datos cuidadosamente anotados, el sistema emplea la mejora verificable en la probabilidad de finalización del texto para definir recompensas objetivas que guían el aprendizaje. Esto permite que el modelo aprenda a condensar la información esencial del argumento y genere una planificación detallada del siguiente segmento de la historia, fomentando la coherencia y la profundidad en la trama. El proceso consiste en evaluar cómo la planificación influye en la calidad de los capítulos producidos. Los resultados generados con este método se comparan con modelos entrenados sin este razonamiento adicional, así como con aquellos afinados mediante supervisión directa. Las evaluaciones humanas, basadas en juicios pareados, indican que los capítulos creados mediante VR-CLI superan a las baselines en casi todos los criterios evaluados.
De manera destacada, las mejoras son más pronunciadas en géneros como la ciencia ficción y la fantasía, que suelen demandar una arquitectura narrativa más compleja y detallada. Uno de los retos fundamentales que aborda VR-CLI es la carencia de conjuntos de datos de calidad con anotaciones explícitas sobre preferencias o razonamientos correctos, lo que históricamente ha limitado el avance del aprendizaje reforzado en tareas creativas. Al definir recompensas verificables basadas en la mejora de la probabilidad de finalización, esta metodología logra evadir la dependencia en supervisión costosa o difícil de conseguir. Además, se promueve una evaluación automática más objetiva, alineada con el rendimiento real del generador en tareas concretas. Las implicaciones de VR-CLI trascienden la generación literaria.
Al demostrar que es posible entrenar modelos para razonar de manera efectiva sobre secuencias narrativas extensas sin supervisión exhaustiva, se abre la puerta a aplicaciones en otras áreas que requieren planificación a largo plazo, como la escritura de guiones, la producción de contenido educativo o la síntesis avanzada de información. Asimismo, la integración de incentivos verificables podría potenciar sistemas conversacionales y asistentes digitales que mantengan diálogos más coherentes y contextualmente relevantes durante prolongados intercambios. Otro aspecto interesante del trabajo es su contribución a la comprensión de cómo diferentes géneros afectan el desempeño de los modelos en tareas de razonamiento narrativo. La evidencia sugiere que géneros con estructuras más complejas y elementos fantásticos ofrecen un campo fértil para que este tipo de aprendizaje se manifieste de manera más evidente, posiblemente debido a la necesidad de mantener la coherencia en mundos imaginarios y reglas internas específicas. El desarrollo experimental de VR-CLI incluyó la comparación con variantes basadas en parámetros más reducidos, como modelos con 3 mil millones de parámetros, para entender mejor cómo la escala influye en la capacidad de razonamiento.
Los hallazgos indican que aunque la capacidad del modelo influye, la formulación de recompensas y el enfoque de aprendizaje son críticos para el éxito en la generación coherente y rica de historias largas. Finalmente, la implementación práctica del sistema se apoya en un dataset curado cuidadosamente a partir de libros públicos, seleccionados para garantizar diversidad y calidad. La metodología incluye la recopilación de evaluaciones humanas para calibrar las métricas de rendimiento y confirmar la efectividad del aprendizaje por refuerzo con recompensas verificables. La colaboración entre avances en procesamiento de lenguaje natural, aprendizaje automático y estudios literarios da lugar a un enfoque innovador que mejora significativamente la producción automática de narrativas extensas. Con la publicación abierta del código fuente y detalles del entrenamiento, VR-CLI también fomenta la reproducibilidad y el crecimiento de la comunidad investigativa en esta área.
La evolución de este sistema tiene el potencial de transformar no solo la generación automática de textos, sino también la forma en la que entendemos la interacción entre razonamiento computacional y creatividad literaria. En resumen, VR-CLI representa un avance pionero en la generación de historias largas al integrar un mecanismo de recompensas verificables que facilita el aprendizaje de razonamiento en modelos de lenguaje. Al abordar las limitaciones de supervisión y ofrecer mejoras tangibles en la calidad narrativa, esta innovación abre caminos novedosos para la producción de contenido escrito más coherente, original y atractivo, especialmente en géneros con altas demandas de estructuración y detalle. El futuro de la escritura asistida por inteligencia artificial se vuelve más prometedor con enfoques como VR-CLI, que combinan rigor técnico con sensibilidad creativa para superar las barreras actuales en la generación de relatos extensos.