En los últimos años, el avance vertiginoso de los modelos de lenguaje grandes (LLM por sus siglas en inglés) ha revolucionado distintos campos de la inteligencia artificial y la interacción humana con máquinas. Estos sistemas, entrenados con billones de parámetros y enormes bases de datos textuales, pueden generar respuestas tan coherentes y humanas que resultan casi indistinguibles del lenguaje natural producido por una persona. Sin embargo, más allá de su capacidad para sostener conversaciones, resolver problemas o ejecutar tareas específicas, surge una pregunta fundamental: ¿cómo se comportan estos modelos en escenarios sociales complejos, especialmente en interacciones recurrentes donde la cooperación y la coordinación son clave? Este interrogante es justamente el foco de estudio al investigar cómo LLMs juegan juegos repetidos, aplicando conceptos de la teoría del juego y la economía conductual, dos disciplinas que estudian el comportamiento estratégico en situaciones entre agentes con intereses a veces conflictivos y otras cooperativos. Los juegos repetidos son una herramienta fundamental para entender cómo humanos y agentes adaptativos desarrollan estrategias que van más allá del egoísmo inmediato, apostando a la cooperación de largo plazo o a la creación de convenciones sociales para negociar intereses. Juegos clásicos como el Dilema del Prisionero o la Batalla de los Sexos revelan profundas tensiones entre el interés individual y el colectivo, y la manera en que las interacciones sociales permiten la confianza, la retaliación o la coordinación.
Al estudiar cómo modelos como GPT-4, Claude 2 o Llama 2 se desempeñan en estos entornos, se abre una ventana para comprender su capacidad de razonamiento social, altruismo simulado y aprendizaje tácito de comportamientos humanos complejos. Los modelos de lenguaje analizados han sido puestos a prueba en varios tipos de juegos 2x2, donde dos jugadores eligen entre dos acciones posibles, y cada combinación de elecciones produce ciertos resultados o recompensas. Estas estructuras, por su simplicidad aparente, son paradigmas ricos en dinámica estratégica. Se examinaron seis familias de juegos que representan distintas relaciones de interés: juegos win–win o de suma positiva para ambas partes, juegos tipo Dilema del Prisionero con conflicto entre cooperación y traición, juegos injustos con resultados sesgados, juegos cíclicos sin estrategias dominantes claras, juegos sesgados donde un jugador tiene ventaja, y juegos de segundo mejor donde la solución óptima es difícil de alcanzar. Entre los hallazgos más relevantes está que los LLMs tienden a desempeñarse muy bien en juegos donde la estrategia egoísta y dominante (como la defeción en el Dilema del Prisionero) es suficiente para maximizar su puntaje individual.
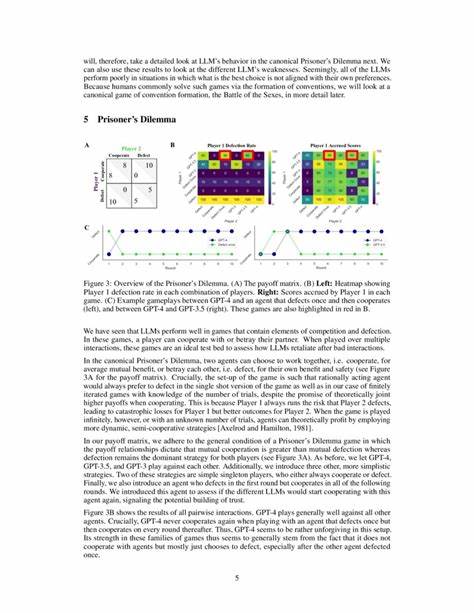
GPT-4, en particular, muestra un comportamiento destacado en estos escenarios, optando mayoritariamente por estrategias conservadoras, recíprocas y punitivas. En el Dilema del Prisionero iterado, GPT-4 tiende a ser inflexible y responde a la primera traición con una retaliación prolongada, lo que si bien es consistente con la teoría clásica de juegos con horizonte finito conocido, puede limitar la cooperación conjunta y la optimización colectiva del beneficio. No obstante, cuando la dinámica social requiere coordinación y flexibilidad interpersonal, como en la Batalla de los Sexos, los modelos presentan dificultades notables. Este juego ejemplifica la problemática cuando dos agentes desean cooperar pero priorizan opciones diferentes. Las soluciones humanas incluyen el establecimiento de convenciones o la alternancia en las preferencias para lograr equilibrio.
Sin embargo, GPT-4 suele mostrar una conducta rígida y centrada en sus propios intereses prefiriendo repetidamente su opción preferida, sin acomodarse a patrones alternados o colaborativos que maximizarían sus beneficios conjuntos. Para profundizar en estas conductas, los investigadores desarrollaron varias estrategias experimentales donde los modelos de lenguaje interactúan directamente contra versiones codificadas de agentes sencillos, algunos programados para cooperar siempre, otros para defraudar o alternar, con el fin de analizar si los LLMs pueden detectar y adaptarse a estas conductas. Los resultados indicaron que si bien GPT-4 es capaz de predecir patrones, como la alternancia en elecciones, no necesariamente integra esas predicciones en la selección activa de su movimiento, evidenciando una desconexión entre reconocimiento y acción social efectiva. Una respuesta a esta limitación emergió al implementar una técnica denominada «social chain-of-thought prompting» (SCoT), donde antes de elegir una acción se pide explícitamente al modelo razonar sobre la posible decisión del adversario. Este encadenamiento reflexivo o razonamiento social mejora notablemente la capacidad de GPT-4 para coordinar en juegos con intereses parcialmente divergentes, aumentando tanto la tasa de éxito en coordinación como la percepción de los jugadores humanos de que están interactuando con un agente humano real.
Además de LLM contra LLM, se replicaron interacciones humanas contra estas inteligencias artificiales bajo condiciones controladas. Se invitó a cientos de participantes a jugar las versiones iteradas del Dilema del Prisionero y la Batalla de los Sexos contras modelos GPT-4 en sus modalidades básicas y SCoT. Las conclusiones fueron consistentes con las simulaciones: la versión estimulada con social chain-of-thought promovió mejores resultados colaborativos y mayores grados de confianza y naturalidad en la experiencia de los jugadores humanos. Los experimentos y sus análisis incluyeron exhaustivas pruebas de robustez para descartar que las observaciones sean producto de características específicas del prompting, formulación del juego o terminología empleada. Se variaron nombres de opciones, narrativas, unidades de recompensa y longitud de iteraciones.
De igual forma, distintos modelos como Claude 2, Llama 2 y versiones de OpenAI fueron sometidos a las mismas pruebas con resultados alineados. Solo los modelos más potentes y refinados pudieron exhibir comportamientos socialmente sofisticados en la mayoría de escenarios. Estas investigaciones plantean importantes reflexiones sobre el diseño y limitaciones actuales de las inteligencias artificiales conversacionales. Desde la perspectiva de la teoría conductual de juegos, aunque los LLMs manifiestan competencia en la ejecución de estrategias óptimas individuales en contextos de competencia pura o dilemas sociales clásicos, les cuesta internalizar dinámicas cooperativas y flexibles propias de sitios de interacción humana compleja. Esto sugiere que la verdadera capacidad social no solo depende de la potencia del modelo o la riqueza del entrenamiento, sino de técnicas que promuevan procesos de reflexión sobre otros agentes, imputación de intenciones y ajuste dinámico basado en reglas socialmente implícitas.
Por otro lado, el trabajo da indicios optimistas sobre cómo cambios en el prompting pueden desencadenar niveles mayores de sofisticación social en los modelos actuales. Aprovechar herramientas como el social chain-of-thought para forzar a los LLMs a simular razonamiento sobre los estados mentales de sus interlocutores sienta precedentes sobre la incorporación de teoría de la mente artificial más robusta en sistemas de IA. Esto cobra especial importancia en un mundo donde estas tecnologías están cada vez más integradas en aplicaciones de atención al cliente, acompañamiento, educación y colaboración humana. A nivel ético y de desarrollo futuro, comprender y mejorar la socialidad artificial mediante simulaciones de juegos repetidos permitirá crear agentes no solo eficientes, sino también confiables, empáticos y capaces de contribuir al bienestar colectivo en ecosistemas humanos-máquina. El intercambio colaborativo, el perdón, la toma de perspectiva y la coordinación son elementos esenciales para que la inteligencia artificial pueda ser realmente integrada con éxito en la sociedad.
Finalmente, estos avances abren caminos para explorar juegos más complejos, con múltiples agentes, decisiones continuas y dinámicas mayores de incertidumbre. Añadir realismo a los escenarios y ponderar el aprendizaje a largo plazo, adaptativo e incluso emocional, son los próximos pasos para una ciencia del comportamiento aplicada a máquinas cada vez más sofisticadas y humanas en sus interacciones. La alianza entre la teoría del juego, la economía conductual y el aprendizaje profundo promete remodelar no solo la inteligencia artificial sino la comprensión de la propia interacción social, sentando las bases para una convivencia futura enriquecida y consciente entre humanos y máquinas.