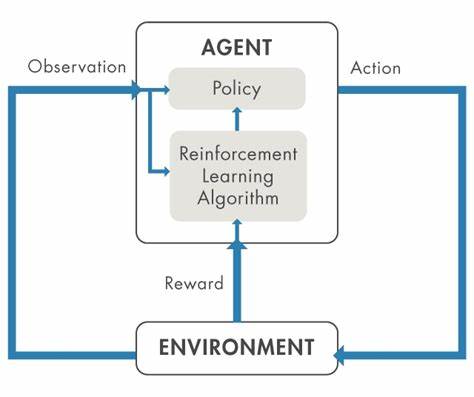
En los últimos años, el aprendizaje por refuerzo ha sido uno de los pilares más prometedores para el desarrollo de inteligencia artificial avanzada, especialmente en áreas como la robótica y el razonamiento automático. Esta técnica permite a los agentes artificiales aprender directamente de la experiencia mediante la maximización de una señal de recompensa, lo que en teoría habilita la autoexploración y la generación de datos propios para mejorar sus habilidades. Sin embargo, pese a sus notables aplicaciones y avances, el aprendizaje por refuerzo presenta una serie de limitaciones cruciales que condicionan su efectividad y aplicabilidad en escenarios complejos, particularmente en problemas del mundo real que requieren capacidades cognitivas profundas y generalizadas. Una de las preocupaciones centrales en la comunidad de investigación es el llamado “muro de datos”, una situación donde los sistemas de entrenamiento se topan con la falta de datos adecuados para seguir mejorando. A pesar de que el aprendizaje por refuerzo permite que los agentes generen sus propios datos a través de la exploración, esto no significa que sea una solución mágica que supere todas las dificultades relacionadas con la disponibilidad o calidad de los datos.
Por ejemplo, en robótica, donde recopilar datos físicos puede ser costoso y lento, la simulación es una herramienta común para el entrenamiento; sin embargo, la transferencia de las políticas aprendidas en simulación al entorno real sigue siendo altamente desafiante debido a las discrepancias visuales y sensoriales. Esta problemática se ejemplifica cuando los agentes son entrenados con observaciones que no se corresponden exactamente con las que encontrarán durante su despliegue. Si el agente aprende a interpretar profundamente ciertas características o texturas específicas que sólo aparecen en simulación, al pasar al mundo físico puede fallar estrepitosamente. Por ello, existe una necesidad imperiosa de que el espacio de observación empleado durante el entrenamiento sea lo más parecido posible al espacio real, o que se realicen ingeniosas modificaciones para que los datos sintéticos reflejen características relevantes y transferibles. Otro componente esencial en el aprendizaje por refuerzo es la función de recompensa, que guía al agente filtrando y asignando valor a las acciones y estados encontrados.
Para problemas en robótica, se suelen usar funciones de recompensa densas que retroalimentan constantemente al agente con señales sobre qué tan bien está ejecutando la tarea y qué tan cerca está de cumplir los objetivos. Esta granularidad ayuda a fomentar una exploración eficaz, especialmente en entornos continuos y complejos donde la mera señal de éxito o fracaso sería demasiado escasa para orientar el aprendizaje. Por el contrario, en dominios como la resolución de problemas matemáticos o de programación, la función de recompensa puede ser mucho más simple y escasa, limitándose por ejemplo a indicar si el resultado es correcto o no. Para estas tareas, el entrenamiento conquiere otra dimensión gracias a modelos base potentes y ya bien entrenados, que permiten a los agentes partir de un punto avanzado y solamente afinar sus habilidades con la ayuda de la retroalimentación de recompensa. En estos casos, el aprendizaje por refuerzo puede ser un complemento para mejorar aún más la precisión, en lugar de un motor principal para el aprendizaje desde cero.
No obstante, incluso en esos escenarios más controlados, el aprendizaje por refuerzo tiene que lidiar con el problema fundamental de la exploración, es decir, cómo decidir qué acciones probar para descubrir soluciones mejores o innovadoras sin desperdiciar recursos en opciones inútiles. Cuando la recompensa es demasiado escasa o poco informativa, el agente puede quedarse estancado en patrones subóptimos, incapaz de encontrar rutas superiores porque no sabe a dónde dirigir sus esfuerzos. Por ello, gran parte del diseño y avance de sistemas de aprendizaje por refuerzo implica la creación de funciones de recompensa elaboradas o estrategias de exploración mejor fundamentadas para sortear estos problemas. A la hora de trasladar estas capacidades a tareas que impliquen razonamiento complejo y generalizado, las limitaciones son aún más pronunciadas. Muchos problemas abstractos y de alta complejidad no cuentan con un método automático para verificar que las soluciones son correctas, lo que imposibilita construir funciones de recompensa claras y directas.
En consecuencia, el aprendizaje por refuerzo tiende a ser menos efectivo para fomentar el desarrollo de habilidades de razonamiento genuinamente innovadoras o profundas, en comparación con otras modalidades de entrenamiento supervisado o mixto. Investigaciones recientes han demostrado que los beneficios del aprendizaje por refuerzo sobre modelos base -como grandes modelos de lenguaje- pueden ser limitados o incluso contraproducentes. Cuando se toman modelos ya competentes y se les aplica aprendizaje por refuerzo, las mejoras suelen ser pequeñas y, en algunos casos, el modelo termina sesgado hacia patrones aprendidos previamente, reduciendo la diversidad y flexibilidad de las respuestas. Esto sugiere que el aprendizaje por refuerzo amplifica ciertas conductas aprendidas en el preentrenamiento, pero no necesariamente genera capacidades nuevas ni generalizaciones profundas. Otra dificultad que enfrentan las técnicas de aprendizaje por refuerzo está relacionada con la alineación y la capacidad de autovalidación.
En escenarios avanzados donde se considera que el agente pueda actuar como su propio juez para evaluar la calidad de sus soluciones, surgen problemas de confiabilidad y coherencia. Si un sistema autoevaluador no tiene criterios externos suficientemente robustos, puede caer en la trampa de optimizar funciones de recompensa que no se corresponden con los objetivos reales o que son vulnerables a ser explotadas, generando soluciones engañosas o sin valor. Desde el punto de vista práctico, hoy el aprendizaje por refuerzo muestra su mayor eficacia en dominios con problemas bien definidos y verificables, como tareas de manipulación robótica con alta disponibilidad de datos de sensores, entrenamiento en simuladores muy detallados o trabajos de optimización en juegos y problemas matemáticos donde las respuestas correctas son claras y fácilmente evaluables. En estos contextos, el aprendizaje por refuerzo puede llevar a sistemas robustos y capaces, teniendo en cuenta que cuenta con la infraestructura necesaria, como simulaciones precisas, funciones de recompensa adecuadas y políticas base razonablemente competentes. Sin embargo, para la mayoría de los escenarios generales, particularmente los que requieren razonamiento abstracto, creatividad o interacción en entornos altamente impredecibles y complejos, el aprendizaje por refuerzo todavía enfrenta importantes obstáculos.
Los problemas de exploración, verificación y transferencia al mundo real dificultan su aplicación directa. Aun así, estas limitaciones no deben descalificar su uso, sino motivar la búsqueda de soluciones híbridas que integren aprendizaje supervisado, aprendizaje por refuerzo, y técnicas emergentes de aprendizaje automático, como el uso de modelos visuales multimodales y representaciones latentes más robustas. La investigación continúa avanzando en la mitigación de estas barreras. Por ejemplo, el desarrollo de métodos de aprendizaje jerárquico busca repartir las tareas extensas y complejas en subproblemas manejables, lo que podría facilitar la aplicación del aprendizaje por refuerzo en horizontes largos. Además, la integración con modelos multimodales y el uso de técnicas de autocomprobación externa prometen fortalecer las funciones de recompensa y mejorar la alineación de los agentes.
En conclusión, el aprendizaje por refuerzo es una herramienta extremadamente poderosa dentro del arsenal de la inteligencia artificial, especialmente en aplicaciones específicas que requieren optimización basada en la interacción directa con el entorno y donde la retroalimentación es clara y continua. No obstante, sus límites son evidentes al intentar aplicarlo a problemas que exceden estas características, como el razonamiento generalizado o el aprendizaje en entornos muy variables sin funciones de recompensa bien definidas. La clave para avanzar radica en combinar sus fortalezas con otras técnicas complementarias y continuar explorando nuevas formas de superar los retos inherentes a la adquisición de conocimiento y habilidades mediante la experiencia autónoma. El futuro del aprendizaje por refuerzo será seguramente uno donde la simbiosis con grandes modelos preentrenados, sistemas de verificación avanzados y arquitecturas jerárquicas permita expandir su campo de aplicación, manteniendo siempre un enfoque realista sobre sus restricciones y aplicando soluciones prácticas a los problemas concretos que se le planteen en la robótica, el razonamiento artificial y más allá.