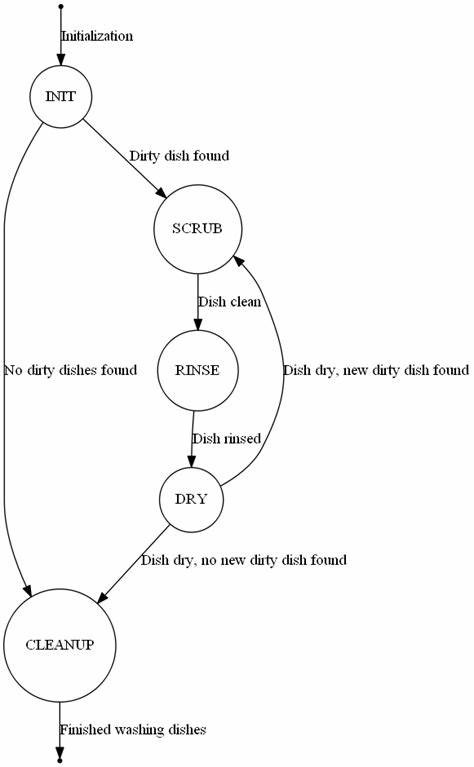
Las máquinas de estado finito, conocidas por sus siglas en inglés FSM (Finite-State Machine), constituyen un modelo computacional que encuentra diversas aplicaciones prácticas en el desarrollo de software y sistemas empresariales. Su esencia radica en representar procesos complejos mediante estados claramente definidos y transiciones condicionadas por eventos, permitiendo un seguimiento controlado y preciso del flujo de actividades. En el contexto de sistemas de gestión de órdenes, transformar las reglas de negocio en una máquina de estado no solo simplifica la implementación, sino que también mejora la integridad y coherencia del sistema. PostgreSQL, reconocido sistema gestor de bases de datos relacional, ofrece potentes herramientas para integrar directamente este tipo de lógica, evitando inconsistencias y rupturas en los procesos derivados de errores o condiciones de carrera. Para ilustrar esta implementación, consideremos un sistema básico de gestión de órdenes con reglas simples pero fundamentales que rigen diversas etapas: las órdenes no pueden ser enviadas antes de haber sido pagadas, puede cancelarse una orden solo si no ha sido despachada, y las órdenes pagadas que se cancelan deben ser reembolsadas.
Este conjunto de reglas se traduce naturalmente en una máquina de estado finito que consta de un conjunto definido de estados, eventos, transiciones y un estado inicial que marca el punto de partida. El primer paso en PostgreSQL consiste en crear una tabla destinada a almacenar los eventos que afectan a cada orden. Esta tabla, denominada order_events, registra el identificador de la orden, el evento ocurrido y el momento en que se llevó a cabo. Gracias a esta estructura, es posible almacenar un historial detallado que permita reproducir el recorrido de cualquier orden a lo largo de sus estados. La pieza clave del modelo es la función de transición, que determina el siguiente estado de la orden considerando su estado actual y el evento recibido.
En PostgreSQL, esta función puede definirse usando SQL de manera sencilla y elegante, mediante una estructura CASE que evalúa el estado actual y el evento para devolver el estado resultante o un estado de error en caso de combinaciones no válidas. Para asegurar que los cambios en la tabla de eventos mantengan la integridad del sistema, es esencial validar cada nuevo evento antes de su inserción. Esto se logra mediante la definición de un agregado definido por el usuario que recorre secuencialmente todos los eventos ocurridos para una orden determinada, aplicando la función de transición en forma acumulativa y obteniendo finalmente el estado en el que se encuentra la orden tras todos los eventos. Esta función agregada, construida con las herramientas propias de PostgreSQL, permite una evaluación eficiente y coherente del historial de eventos. La aplicación práctica de este agregador se cristaliza en un disparador (trigger) que se invoca antes de insertar cualquier nuevo evento en la tabla.
El propósito del disparador es ejecutar la función agregada para el conjunto de eventos que incluye el nuevo, y en caso de que el resultado sea un estado de error, cancelar la inserción lanzando una excepción. De esta forma, se asegura que toda secuencia de eventos permanezca dentro de las reglas definidas por la máquina de estado, protegiendo la base de datos contra inserciones inválidas o inconsistentes. Probando la solución con una secuencia válida de eventos observamos cómo el sistema acepta la inserción sin problemas, mientras que ante una secuencia inválida, como intentar enviar una orden sin haberla pagado previamente, el disparador detiene la acción y lanza un error. Este comportamiento garantiza que la lógica de negocio está en todo momento alineada con el estado de los datos almacenados. Una ventaja secundaria pero muy valiosa que ofrece la implementación de máquinas de estado directamente en PostgreSQL es la posibilidad de realizar análisis temporales y estudios avanzados del comportamiento de las órdenes a lo largo del tiempo.
Por ejemplo, mediante el uso de funciones ventana que aplican el agregador de eventos ordenado cronológicamente, es posible reconstruir la evolución del estado de cualquier orden y obtener informes detallados sin tener que depender de lógica adicional en capas superiores de la aplicación. Esta capacidad analítica puede extenderse para evaluar conjuntos completos de órdenes en rangos de fechas específicos, fusionando la generación de series temporales con subconsultas laterales. Así, es factible dimensionar cuántas órdenes se encontraban en cada estado para cada día, brindando una visión clara y profunda que ayuda en la toma de decisiones estratégicas y en el monitoreo de procesos. Más allá de las ventajas técnicas, implementar la lógica estatal dentro de la base de datos puede significar un ahorro considerable en el desarrollo y mantenimiento del software, ya que centraliza el control en un único lugar. Además, fortalece la seguridad y consistencia de la información, al reducir la posibilidad de condiciones de carrera y otras anomalías cuando se trabaja concurrentemente con múltiples transacciones.
Sin embargo, este enfoque también implica ciertas consideraciones. Integrar lógica de negocio en la capa de base de datos puede aumentar la complejidad del esquema y dificultar la migración o escalabilidad en algunos escenarios. Por ello, es importante evaluar cuidadosamente su implementación según las particularidades del proyecto, el volumen de datos y los requerimientos operativos. En conclusión, la implementación de máquinas de estado finito en PostgreSQL es una estrategia poderosa para manejar procesos basados en estados en sistemas de gestión de órdenes y otros dominios. Esta técnica combina la robustez y eficiencia del sistema gestor de bases de datos con un modelo formal y comprobable para el control de la evolución de objetos de negocio, entregando tanto integridad como capacidad analítica avanzada.
Con un enfoque cuidadoso y planificación adecuada, esta solución puede transformar sistemas tradicionales en plataformas más confiables, escalables y fáciles de mantener, aportando valor tanto a nivel técnico como operativo. La invitación a experimentar con estas técnicas abre una ventana a nuevas posibilidades para diseñar aplicaciones modernas y resilientes que aprovechan al máximo las herramientas que ofrece PostgreSQL.



![Rapid accumulation of [trash] on most pristine islands (2017)](/images/F14A7D38-46B6-4CE6-8840-3562A942F4B5)