En el desarrollo de software moderno, especialmente en aplicaciones que requieren alto rendimiento, es común que lenguajes como Go se combinen con librerías escritas en C para aprovechar funcionalidades robustas y optimizadas. Sin embargo, esta integración también trae consigo ciertos desafíos, entre ellos, la gestión adecuada de la memoria. Un problema recurrente que puede surgir es la fuga de memoria proveniente de la capa C, algo que puede afectar negativamente el rendimiento y la estabilidad de la aplicación final. En arquitecturas modernas, como las utilizadas en Zendesk, es habitual ver consumidores y productores de Kafka escritos en Go que dependen de librerías como librdkafka, una solución en C robusta para manejar Kafka. Para acceder a esta librería desde Go, se utiliza cgo, que actúa como puente entre el código Go y el código C.
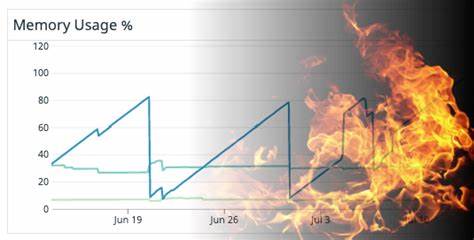
Si bien la ventaja principal es su capacidad para reutilizar código y acceder a funcionalidades maduras, también expone a los desarrolladores a los riesgos comunes asociados a C, principalmente las fugas de memoria, que en entornos de producción pueden provocar incrementos progresivos del uso de memoria y, en casos extremos, causar la terminación inesperada del proceso por parte del sistema operativo. Detectar si la fuga reside en la parte C o en Go es esencial para encaminar correctamente el proceso de depuración. En la experiencia compartida por el equipo de Zendesk, una métrica determinante fue la observación de una discrepancia entre el uso de memoria reportado por el sistema operativo — conocido como RSS (Resident Set Size) — y las estadísticas internas de asignación de memoria gestionada por el recolector de basura de Go. Cuando el uso total de memoria aumentaba sin un incremento paralelo en la memoria asignada y administrada por Go, eso indicaba que la fuga probablemente reside fuera del runtime de Go, en este caso dentro de la librería C. Es pertinente aclarar que no todo incremento de memoria significa una fuga per se.
La fragmentación de memoria o la estrategia de relegación tardía de la memoria por parte del kernel pueden simular una fuga al presentar un crecimiento sostenido en el consumo. Por esta razón, antes de profundizar en líneas complejas de código y herramientas de análisis, es recomendable usar un reemplazo alternativo de malloc conocido como jemalloc. Jemalloc ofrece estadísticas detalladas sobre la memoria asignada en tiempo real dentro del programa y puede integrarse para monitorear el estado real de asignación y liberación de memoria en la parte C. Cuando jemalloc confirma un incremento sostenido de memoria asignada que coincide con el crecimiento en el consumo total detectado por el sistema, la hipótesis de fuga se fortalece y es momento de usar herramientas especializadas. En el caso de código C embebido en Go, Valgrind suele ser la opción tradicional para identificar leaks, ya que intercepta llamadas a malloc y free, detectando memoria asignada y nunca liberada.
Sin embargo, la experiencia mostró que Valgrind no siempre revela la totalidad de la fuga. En el caso concreto, la herramienta reportó solo pocos kilobytes de posibles pérdidas, mientras que la métrica indicaba decenas de megabytes de memoria en uso. Esto podría deberse a que la memoria estaba siendo correctamente liberada antes de la terminación del programa o porque la memoria se asignaba a través de mecanismos no monitoreados por Valgrind, como mmap, aunque este último caso era improbable. Para superar esta limitación, el equipo recurrió a eBPF (Extended Berkeley Packet Filter), una tecnología revolucionaria que permite instrumentar y monitorizar el kernel de Linux y las aplicaciones en tiempo real con bajo costo en rendimiento. Con herramientas como bpftrace, es posible crear scripts que interceptan llamadas de función específicas, extrayendo información relevante como las direcciones de memoria asignadas y sus pilas de llamadas sin detener ni modificar el código base directamente.
El enfoque adoptado consistió en insertar puntos de rastreo dinámico (probes) en las funciones de asignación y liberación de memoria dentro de librdkafka, permitiendo registrar cada malloc y free. Esto fue posible mediante macros de SystemTap que insertan instrucciones nop que actúan como puntos interceptables cuando están habilitados para trazas. Además, se compiló la librería con la opción -fno-omit-frame-pointer para preservar la información necesaria para obtener rastros de pila precisos. Implementar esta solución dentro de contenedores orquestados por Kubernetes no fue trivial, debido a la necesidad de privilegios especiales (CAP_BPF y CAP_PERFMON) para cargar eBPF y al acceso a los encabezados correctos del kernel. Estas barreras se sortearon temporalmente habilitando el modo privilegiado y asegurando la presencia del módulo kheaders para el acceso a los headers del kernel dentro del contenedor.
Al desplegar la herramienta y dejarla actuar, se obtuvo un listado detallado de las asignaciones de memoria que aún no se habían liberado, identificando claramente la pila de llamadas responsable. Esta información brindó un mapa claro para la investigación manual en el código de librdkafka. La raíz del problema resultó ser una cola interna donde librdkafka almacenaba eventos generados al recibir respuestas OffsetCommitResponse del broker Kafka. Debido a una configuración de auto-commit de cinco segundos, esta cola crecía muy rápido y la aplicación no estaba procesando ni vaciando esa cola, acumulando objetos en memoria sin liberarlos hasta que la aplicación terminaba y destruía el manejador de librdkafka, liberando toda la memoria de golpe. Esto explicaba por qué Valgrind no detectaba la fuga mientras el programa corría, pero el sistema operativo sí mostraba un crecimiento lineal del consumo.
La solución fue sencilla una vez localizada: consumir y desechar esos eventos para evitar el crecimiento ilimitado de la cola. Este pequeño ajuste implicó unos pocos cambios en el código pero resultó en una disminución significativa y estable del uso de memoria. Este caso de estudio resalta varios aprendizajes importantes, no solo acerca del uso de librdkafka y su manejo interno de eventos, sino también sobre las estrategias para abordar problemas complejos en ambientes que involucran interoperabilidad entre Go y C. El conocimiento adquirido facilita futuras migraciones y mejora la confianza en sistemas basados en librerías nativas. Asimismo, la experiencia validó el uso de eBPF y herramientas como bpftrace como complementos indispensables para la depuración avanzada, expandiendo el conjunto de habilidades del equipo más allá de las técnicas tradicionales como Valgrind y perf.
Finalmente, esta historia pone sobre la mesa la importancia de contar con tiempo y recursos para investigar a fondo problemas que pueden parecer menores al principio, pero que impactan directamente en la eficiencia y confiabilidad de aplicaciones críticas. El compromiso de apoyar a los equipos en este tipo de esfuerzos es fundamental para construir software sólido y escalable. En conclusión, las fugas de memoria en aplicaciones Go que incorporan código C pueden ser particularmente difíciles de detectar, pero con las herramientas correctas y un enfoque sistemático que combina métricas, análisis con Valgrind y trazabilidad con eBPF, es posible encontrar la raíz del problema y aplicar soluciones efectivas. Adoptar este enfoque detallado garantiza un mejor control del recurso vital que es la memoria, contribuyendo al desarrollo de aplicaciones robustas y eficientes en arquitecturas modernas y distribuidas.








