Las bases de datos son el corazón invisible que impulsa la mayoría de las aplicaciones que utilizamos a diario, desde sitios web hasta sistemas empresariales complejos. Sin embargo, muchas veces no somos conscientes del complicado proceso que ocurre detrás de escena cuando realizamos una simple operación, como buscar información o agregar un registro. Comprender la anatomía de una operación en bases de datos no solo ayuda a optimizar el rendimiento, sino que también ofrece una visión esencial para desarrollar aplicaciones sólidas y eficientes. En esta exploración, vamos a desglosar qué ocurre desde el momento en que se envía una petición hasta que los datos son devueltos al usuario, con un enfoque en PostgreSQL y su interacción con aplicaciones Django. Cuando un usuario realiza una acción que requiere acceder o modificar datos, esa solicitud viaja desde la interfaz de usuario a través de la aplicación hasta la base de datos.
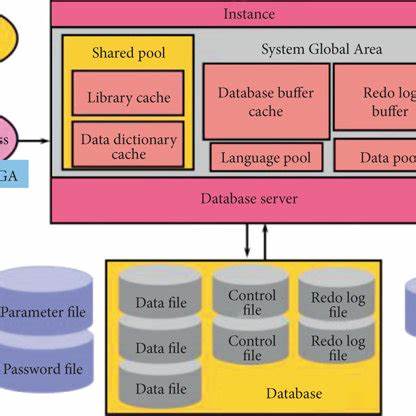
Por ejemplo, en un sitio que almacena información de cervezas, como los tipos y fabricantes, al pedir listar las cervezas o agregar una nueva, la aplicación primero debe transformar esa intención en un comando que la base de datos pueda comprender. En el ecosistema Django, esta transformación es realizada por el ORM (Object Relational Mapper), una capa que traduce las consultas en lenguaje SQL compatible con la base de datos elegida. Si bien no todo el mundo necesita conocer los detalles del ORM, es importante entender que es la que genera las sentencias SQL efectivas que luego serán procesadas. El siguiente paso fundamental es establecer una conexión con el servidor de bases de datos. PostgreSQL, el sistema de gestión de bases de datos relacional utilizado, tiene una arquitectura cliente-servidor clásica en la que el servidor actúa como un guardián del almacenamiento y gestor de datos.
La comunicación fluye a través de un puerto TCP (por defecto, el 5432), donde un proceso supervisor escucha constantemente. Cuando detecta una petición de conexión, crea un proceso dedicado para esa sesión específica, permitiendo que múltiples conexiones coexistan de forma simultánea sin interferencias. Sin embargo, cada conexión consume recursos y la gestión eficiente es clave para mantener un rendimiento óptimo, razón por la cual muchas aplicaciones implementan poolings de conexiones como PgBouncer. Una vez establecida la conexión y recibida la consulta, PostgreSQL inicia un proceso complejo para llevar a cabo la operación solicitada. Primero, la consulta se analiza sintácticamente para detectar posibles errores o problemas, tales como referencias a tablas inexistentes o permisos insuficientes.
Este análisis garantiza que la instrucción sea válida antes de continuar, evitando ejecuciones erróneas o inseguras. Luego, la consulta pasa por una fase de transformación y reescritura, donde elementos como las vistas o reglas específicas de seguridad (por ejemplo, el control a nivel de fila) son interpretados y adaptados. Este mecanismo asegura que lo que se pide en la consulta refleje efectivamente la estructura y políticas vigentes en la base de datos. Una de las etapas más críticas es la planificación. En este punto, PostgreSQL genera un plan de ejecución que especifica cómo obtener los datos o realizar los cambios.
Dado que SQL es un lenguaje declarativo —donde se indica qué se desea sin explicar cómo hacerlo— el motor debe decidir la mejor estrategia posible para acceder, filtrar, ordenar y unir los datos. Esta planificación incluye decisiones como si se explorará toda la tabla o se usará un índice, el tipo de join a emplear, y el orden en que se combinarán las tablas en caso de tener varias involucradas. Entender estos planes de ejecución puede parecer intimidante al principio, pero es esencial para optimizar rendimiento y diagnosticar problemas. Herramientas como EXPLAIN con las opciones ANALYZE y BUFFERS nos permiten visualizar el plan detallado y cómo se comportó en tiempo real, mostrando estadísticas, costos estimados y reales, y cuáles partes de la consulta consumieron más recursos. Estas métricas son oro puro para desarrolladores y administradores que buscan mejorar la eficiencia del acceso a datos.
Una vez diseñado el plan, PostgreSQL procede a ejecutarlo. Se accede a los datos, ya sea mediante escaneos secuenciales de las páginas de datos o utilizando índices, que son estructuras optimizadas para acelerar la búsqueda. En tablas pequeñas, puede resultar más eficiente leer todo el contenido, mientras que en tablas más grandes el uso de índices reduce significativamente el trabajo al enfocarse solo en las filas relevantes. Cuando la consulta involucra joins, PostgreSQL puede emplear técnicas como loops anidados, merge joins o hash joins, según la naturaleza y volumen de los datos. Estas operaciones permiten combinar registros de múltiples tablas para obtener un resultado coherente.
Para operaciones de inserción, actualización o eliminación, PostgreSQL utiliza un sofisticado sistema llamado MVCC (Control de concurrencia multiversión). Esta técnica permite que múltiples transacciones se ejecuten simultáneamente sin bloquearse mutuamente, garantizando la consistencia y el aislamiento de los datos. Por ejemplo, cuando se actualiza un registro, el sistema crea una copia nueva y marca la antigua como obsoleta, la cual será eliminada posteriormente en un proceso conocido como vacuum. Esto evita bloqueos perjudiciales y mantiene la base de datos rápida y accesible para todos los usuarios. Las transacciones en PostgreSQL brindan una capa de seguridad que agrupa varias operaciones en una única unidad atómica: las operaciones se aplican en su totalidad si todo es exitoso o no se aplican si ocurre algún fallo, evitando estados intermedios inconsistentes.
En entornos Django, el modo autocommit suele estar activado, lo que implica que cada consulta se trata como una transacción individual que se cierra automáticamente, salvo que se especifique lo contrario. Finalmente, después de ejecutar la consulta, los resultados se envían de regreso a la aplicación. Este paso, aunque puede parecer trivial, también requiere atención ya que el transporte de datos sobre la red influye en la experiencia del usuario. Solicitar más datos de los estrictamente necesarios puede generar latencias innecesarias y saturar recursos. Por eso, aprender a seleccionar únicamente las columnas y filas realmente útiles es una práctica fundamental para optimizar la interacción entre la base de datos y la aplicación.
Además, la configuración adecuada del servidor PostgreSQL puede mejorar considerablemente la monitorización y el rendimiento. Parámetros como log_min_duration_statement permiten registrar consultas que superen un umbral de tiempo, facilitando la identificación de las operaciones lentas o ineficientes. A su vez, personalizar el prefijo de líneas de log ayuda a contextualizar cada evento con información que puede incluir la hora, el usuario, la base de datos y más. Conocer y entender la anatomía de una operación en bases de datos es una habilidad imprescindible para desarrolladores, administradores y arquitectos de software. Facilita crear soluciones más robustas, predecibles y también permite anticiparse a posibles cuellos de botella o problemas.
PostgreSQL, con su amplia comunidad y arquitectura probada, es una plataforma ideal para profundizar en estos conceptos. En resumen, cuando una consulta parte de una aplicación, pasa por una serie de etapas críticas: conexión, análisis, planificación, ejecución y devolución de resultados. Cada una de estas fases está optimizada para garantizar rapidez y confiabilidad. La interacción entre ambientes como Django y PostgreSQL ejemplifica cómo la combinación de tecnologías puede simplificar el trabajo del desarrollador, mientras que el conocimiento profundo de estos procesos ayuda a sacar el máximo provecho. Adentrarse en este tipo de detalles no solo enriquece la capacidad técnica sino que también transforma la forma en que se diseñan y gestionan sistemas modernos, asegurando experiencias de usuario fluidas y bases de datos bien mantenidas y eficientes.
En definitiva, valorar y entender la anatomía de una operación en bases de datos es clave para dominar el mundo digital actual.




![Solutions for PV Cyber Risks to Grid Stability [pdf]](/images/361FA81B-0EEC-48D6-896A-847510B2B5A0)
![Can an English Fish Merchant Turn a Profit in Asia's Largest Market? [video]](/images/65E85E32-6C6C-4517-9A27-B5613ED8B908)

