Los problemas de optimización combinatoria (COP) se presentan en multitud de sectores y disciplinas, desde la programación de turnos laborales y las rutas de tráfico hasta el desarrollo farmacéutico, y constituyen un desafío importante para las computadoras tradicionales debido a su capacidad limitada para encontrar soluciones óptimas en tiempos razonables. En respuesta a esta dificultad, han ganado popularidad los procesadores de recocido (AP), dispositivos especializados diseñados para abordar estos complejos problemas mediante la simulación del modelo físico Ising. Este modelo representa las variables del problema como espines magnéticos y las restricciones como interacciones entre estos, buscando la configuración de espines que minimice la energía total del sistema, lo que corresponde a la solución óptima del COP. Sin embargo, las limitaciones actuales en la arquitectura de estos procesadores suelen imponerse en dos frentes fundamentales: la capacidad de espines procesados y la precisión con la cual se representan las interacciones, medidas en bits. Mientras que algunos diseños permiten una gran cantidad de espines (alta capacidad) con interacción limitada, otros priorizan la precisión pero sacrifican la escala, dificultando así la resolución efectiva de problemas complejos.
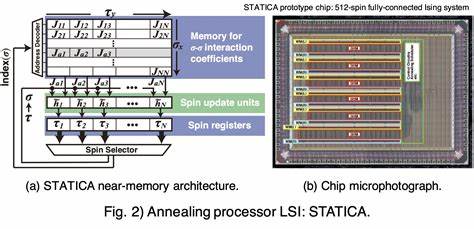
La investigación desarrollada por el equipo dirigido por el profesor Takayuki Kawahara, del Departamento de Ingeniería Eléctrica de la Universidad de Ciencia de Tokio, marca un punto de inflexión en esta área. Mediante la creación de un sistema innovador llamado Procesador de Recocido Escalable Doble (DSAPS), han logrado superar simultáneamente las barreras de capacidad y precisión utilizando una estructura escalable única. Su trabajo, publicado en el prestigioso IEEE Access, no solo establece una base tecnológica robusta sino que también ofrece un marco práctico para la implementación de sistemas que puedan manejar una mayor cantidad de espines y lograr mayor resolución en las interacciones, todo en paralelo y con un solo bloque de control programable (FPGA). El DSAPS opera mediante la manipulación especial de bloques denominados ∆E, que son los responsables de calcular la energía total del sistema, es decir, la base sobre la cual se determina la configuración óptima de los espines. Cada bloque ∆E equivale a un chip de gran integración (LSI) montado en una placa basada en circuitos CMOS.
La clave del avance radica en aplicar dos estructuras distintas para escalar estas unidades: una orientada hacia una capacidad alta y otra hacia una precisión elevada. La primera estructura permite dividir cada bloque ∆E en sub-bloques más pequeños, calculando sus energías individualmente y combinándolas luego mediante un bloque de control centralizado. Así es posible incrementar el número total de espines simplemente aumentando el número de sub-bloques, lo que abre la puerta a la escalabilidad masiva en capacidad. Por otro lado, la estructura de alta precisión aprovecha el procesamiento conjunto de múltiples bloques ∆E, cada uno operando al mismo número de espines pero con diferentes niveles de bits de interacción. Al combinar los resultados mediante desplazamientos de bits controlados por el bloque central, se logra una ampliación efectiva de la resolución total.
En términos prácticos, un conjunto de cuatro bloques ∆E trabajando en niveles de bit diferenciados puede cuadruplicar la anchura de bits de interacción original, permitiendo representar interacciones mucho más detalladas y complejas que lo que permite la tecnología ASIC tradicional, que comúnmente se limita a 4 u 8 bits. Esta dualidad en la escalabilidad otorga al DSAPS una flexibilidad sin precedentes, pudiendo ser aplicado tanto en modelos de Ising de acoplamiento disperso como en modelos totalmente acoplados. Este último es el más deseable para los COPs porque permite un mapeo directo del problema sin necesidad de transformaciones complejas. Sin embargo, hasta ahora estos estaban restringidos por su limitada capacidad y precisión, dos barreras que DSAPS parece superar con éxito. Los investigadores demostraron la viabilidad del sistema mediante dos configuraciones implementadas en una placa CMOS-AP con hilos de espín: una con 2048 espines, 10 bits de interacción y cuatro hilos, y otra con 1024 espines, 37 bits de interacción y dos hilos.
Estas configuraciones representan un salto notable respecto a sistemas ASIC existentes y validan la escalabilidad tanto en capacidad como en precisión. En pruebas concretas de problemas como MAX-CUT, DSAPS alcanzó una precisión superior al 99% en comparación con resultados teóricos de referencia, lo que muestra su capacidad para entregar soluciones confiables. No obstante, la elección de la configuración es crucial según el tipo de problema. En el caso del problema de mochila 0-1, la versión de 10 bits mostró una desviación promedio significativa (99%), mientras que aquella con 37 bits logró una desviación mínima (0.73%), comparable con emulaciones por CPU.
Esto refleja que problemas con características específicas pueden requerir una mayor precisión para obtener soluciones adecuadas, subrayando la importancia estratégica de la flexibilidad de DSAPS. El impacto de este desarrollo trasciende el ámbito puramente académico. En términos educativos, la Universidad de Ciencia de Tokio ha incorporado este sistema como parte de los experimentos prácticos para estudiantes de tercer año a partir de 2025, mejorando el aprendizaje en diseño semiconductores y tecnología de optimización avanzada. En aplicación práctica, los procesadores escalables dualmente aportan una base para resolver problemas industriales y científicos que, hasta ahora, superaban las capacidades de los sistemas convencionales. Áreas como la inteligencia artificial, la planificación logística, el modelado biomolecular y el análisis de redes complejas están destinadas a beneficiarse enormemente.
Desde un punto de vista tecnológico, el DSAPS representa un avance sofisticado en el diseño de hardware para computación cuántica y máquinas de Ising integradas, combinando eficientemente escalabilidad y precisión, dos factores tradicionalmente contrapuestos. La arquitectura modular basada en chips LSI y su control centralizado por FPGA no solo facilita la expansión progresiva según las necesidades del usuario sino que también mantiene el equilibrio ideal entre rendimiento y costo energético. Además, la investigación realizada bajo la dirección del profesor Kawahara cuenta con el respaldo de importantes subvenciones del JSPS KAKENHI, lo que garantiza continuidad y profundización en la exploración de electrónica sustentable y sistemas de computación avanzada. Estos esfuerzos en el diseño de dispositivos de baja potencia, sensores especializados y técnicas de computación cuántica reforzarán aún más las capacidades del DSAPS y ampliarán su rango de aplicación. En resumen, el desarrollo de los Procesadores de Recocido Escalable Doble constituye un salto tecnológico fundamental para la computación optimizada, al permitir simultáneamente gestionar un número mayor de variables y mejorar la precisión de las interacciones en la búsqueda de soluciones óptimas a problemas complejos.
El doble enfoque de escalabilidad abre un amplio abanico de posibilidades para enfrentar retos actuales y futuros en múltiples disciplinas, desde la investigación básica hasta las aplicaciones industriales más exigentes. La combinación de diseño innovador, validación práctica y educación superior conforma un círculo virtuoso que impulsará significativamente el progreso en tecnologías de optimización combinatoria y ciencias computacionales. Este avance también invita a repensar las metodologías tradicionales de resolución de problemas en ciencia y tecnología, alentando la integración de hardware especializado con algoritmos evolutivos y técnicas de inteligencia artificial para explorar soluciones más eficientes y rápidas. Conforme se extiendan las aplicaciones y se optimicen las implementaciones, DSAPS tiene el potencial de transformar la manera en que se abordan los desafíos globales, sentando las bases para una nueva era de computación intensiva en precisión y escala.