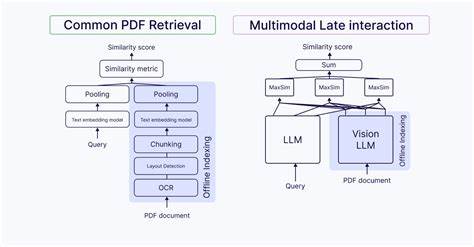
En el mundo actual, donde la información no se limita únicamente a texto, sino que también incluye imágenes, gráficos, tablas y documentos escaneados, la necesidad de entender y buscar en datos multimodales se ha vuelto esencial. Los modelos de interacción tardía multimodal surgen como una solución potente para afrontar los retos que presentan estos formatos híbridos, ofreciendo una precisión y una capacidad de recuperación de información mucho más sofisticadas que los métodos tradicionales. La recuperación de información tradicional, basada principalmente en vectores densos que comprimen el significado del texto en una única representación, suele ser insuficiente cuando la consulta involucra elementos visuales o documentos estructurados. Por ejemplo, en un documento PDF con tablas financieras y gráficos, este enfoque puede perder la relación espacial y semántica entre el texto y los elementos visuales. Esto limita severamente la eficacia de la búsqueda cuando se requieren respuestas específicas relacionadas con la disposición o contenido visual.
Los modelos de interacción tardía funcionan reteniendo embeddings a nivel de token o parches de imagen, lo que permite que cada segmento del documento tenga su propia representación vectorial. Este enfoque desglosa y mantiene la granularidad tanto del texto como de las imágenes, lo que es crucial para manejar documentos complejos y consultas sofisticadas. Cuando se trata de buscar, por ejemplo, una tabla específica dentro de un informe financiero o un gráfico concreto en un artículo científico, los modelos de interacción tardía pueden comparar directamente los tokens de la consulta con cada sección o parche visual del documento. Esta comparativa se realiza utilizando el operador MaxSim, que calcula la similitud máxima entre vectores, permitiendo así que el sistema identifique la información más relevante sin perder el contexto ni la relación entre los diferentes elementos del contenido. Los casos de uso de estos modelos son variados y de gran impacto.
Imagina la tarea de buscar en un PDF escaneado que contiene gráficos de líneas mostrando las variaciones mensuales de ingresos. Los modelos densos tradicionales fallarían al intentar comprender la naturaleza visual del gráfico, pero los modelos multimodales de interacción tardía como ColPaLI o ColQwen pueden reconocer cada parche visual como una unidad significativa, lo que permite responder eficazmente a consultas complejas que involucran elementos gráficos. Del mismo modo, estas arquitecturas permiten asociar tablas con sus leyendas o textos explicativos cercanos, algo que los modelos a vectores simples no pueden lograr. Esta capacidad abre nuevas posibilidades para los sectores financiero, educativo, médico y científico, donde la interpretación precisa de combinaciones textuales y visuales es fundamental. Entre los modelos destacados dentro de esta categoría está ColBERT, un modelo que trabaja exclusivamente con texto pero que emblemáticamente introdujo el concepto de interacción tardía mediante vectores de token y el sistema MaxSim.
Posteriormente, ColPaLI extendió este enfoque para incluir documentos multimodales, utilizando representaciones compartidas entre texto e imágenes, lo que permite una interacción fluida entre ambos tipos de datos. ColQwen representa un avance más reciente, con un tamaño de parche más pequeño y una licencia permisiva que facilita su adopción en diversos proyectos. Estos modelos constituyen la base de sistemas de recuperación y razonamiento automatizados sobre documentos complejos que hoy son esenciales para la eficiencia en sectores que gestionan grandes volúmenes de información diversa. No obstante, implementar estos modelos en un entorno de producción presenta desafíos significativos. Uno de los más importantes es el costo de almacenamiento, ya que el mantener múltiples vectores por documento incrementa los requerimientos de espacio considerablemente.
Además, la mayoría de las bases de datos vectoriales no están aún optimizadas para manejar índices de multi-vectores, lo que dificulta la escalabilidad y rapidez necesarias para aplicaciones en tiempo real. Otro aspecto crítico es el proceso de inferencia, específicamente la necesidad de computar productos punto entre todas las combinaciones posibles de vectores de consulta y documento. Aunque se trata de un proceso intensivo, las últimas innovaciones en hardware y algoritmos están mitigando este problema, haciendo viable la implementación en aplicaciones reales. La alineación cruzada entre modalidades, que implica unificar representaciones de texto e imagen en un espacio semántico común, requiere un entrenamiento robusto y datos bien etiquetados para conseguir que el modelo realice asociaciones precisas. Este es uno de los retos centrales para asegurar que los modelos de interacción tardía multimodal puedan comprender y relacionar correctamente contenidos heterogéneos.
En este contexto, Mixpeek emerge como una solución integral y orientada al uso en producción. Su infraestructura está diseñada para incorporar la extracción modular de características multimodales, incluyendo modelos de estilo ColBERT para una coincidencia semántica fina. Además, optimizan la indexación y recuperación multivectorial para permitir consultas tanto en tiempo real como en modo batch, combinando eficiencia con flexibilidad. Una ventaja clara que ofrece Mixpeek es la transparencia y explicabilidad en el proceso de recuperación, mostrando qué tokens o parches específicos disparan la coincidencia. Esta característica no solo mejora la confianza del usuario en las respuestas proporcionadas sino que también facilita la depuración y mejora continua de los sistemas de búsqueda.
La llegada de estos modelos y plataformas transforma radicalmente la búsqueda en datos multimodales. Al permitir una interacción granular y precisa entre texto e imágenes dentro del mismo documento, abren el paso a aplicaciones de investigación, análisis financiero, gestión documental y más, donde hasta ahora dominar documentos complejos significaba consumir tiempo y recursos extensos. En definitiva, los modelos de interacción tardía multimodal son una evolución esencial para la recuperación de información en la era digital. Su capacidad para preservar la estructura, la relación semántica y la granularidad en contenidos diversos convierte a estas soluciones en la base para la siguiente generación de motores de búsqueda y sistemas de razonamiento automatizados. Con la integración de tecnologías como MaxSim y sistemas especializados como ColPaLI y ColQwen, junto al soporte tecnológico de plataformas como Mixpeek, el futuro del análisis y búsqueda multimodal es prometedor y está al alcance para empresas e investigadores que buscan superar las limitaciones de los métodos tradicionales.
Adoptar estas herramientas significa estar a la vanguardia en eficiencia informativa y precisión en la era de los datos complejos.