Los modelos de lenguaje basados en arquitecturas Transformer han revolucionado el campo del procesamiento del lenguaje natural, y GPT-2 es uno de los exponentes más influyentes de esta nueva era. Comprender cómo funcionan estos modelos a nivel interno puede resultar complejo, pero explorar los pesos de atención dentro de GPT-2 proporciona una ventana invaluable para desentrañar sus mecanismos de decisión y procesamiento de la información. La visualización de los pesos de atención en GPT-2 permite observar cómo cada bloque y cabeza de atención interactúa con diferentes partes de un texto dado, revelando patrones y comportamientos esenciales para la generación de lenguaje coherente y contextualizado. Antes de profundizar en la visualización, es importante comprender qué son los pesos de atención y por qué son fundamentales en los Transformers. En esencia, la atención es un mecanismo que permite al modelo enfocar selectivamente ciertas partes de la entrada mientras procesa información, ponderando la importancia relativa de cada token en función del contexto.
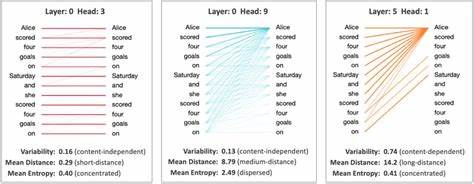
En GPT-2, múltiples cabezas de atención capturan diversos aspectos semánticos y sintácticos del texto, al mismo tiempo que diferentes bloques se encargan de procesar y transformar esta información gradualmente para producir la salida final. Visualizar estos pesos significa mapear cómo cada token en la secuencia de entrada se relaciona con los demás, generalmente a través de matrices donde cada eje representa los tokens consultados o consultantes. Al trabajar con el modelo GPT-2 (pequeño), se puede observar cómo cada cabeza de atención dentro de un bloque se apila a lo largo del eje vertical, mientras que las interacciones token a token se muestran en los ejes horizontal y en profundidad, evidenciando así la complejidad y riqueza del proceso. Una herramienta interactiva para visualizar estos pesos ofrece funcionalidades como el zoom y la selección mediante arrastre, permitiendo al usuario examinar diferentes regiones del bloque de atención, y obtener así una perspectiva granular del comportamiento de cada cabeza. Además, al pasar el cursor sobre puntos específicos, se revelan los valores exactos de los pesos de atención y las parejas de tokens que representan las relaciones de consulta y clave.
Esto proporciona una forma intuitiva de entender qué partes del texto influyen más en cada predicción. Un aspecto importante es la utilización de una escala logarítmica para el tamaño de los puntos en la visualización. Este método, recomendado gracias a aportes de expertos como Taylor Baldwin, ayuda a balancear la representación de los pesos, evitando que los valores más altos dominen la vista y permitiendo capturar también las atenciones más sutiles conocidas como "attention sinks". De esta manera, la visualización es más equilibrada y representativa de la verdadera dinámica interna del modelo. El proceso comienza con la adición de un token especial de inicio de secuencia (<bos>), lo que garantiza que el modelo tenga un punto de partida claro para la generación de texto, y que la atención se distribuya adecuadamente desde el principio.
Posteriormente, a medida que se procesa el prompt, los pesos de atención se calculan para cada bloque y cada cabeza, revelando cómo el modelo decide qué tokens considerar prioritariamente para construir contexto y generar la siguiente palabra. Explorar estos pesos en los diferentes bloques de GPT-2 (que en total suman doce en la versión pequeña) nos permite ver la evolución y refinamiento del entendimiento del texto a lo largo de las capas. Mientras que las primeras capas pueden presentar atenciones más distribuidas o locales, las capas superiores tienden a concentrar su atención en tokens que tienen mayor relevancia para el significado global, demostrando un aprendizaje jerárquico y el manejo avanzado del contexto semántico. El origen de esta visualización proviene de una sinergia de desarrollos previos. Herramientas como Transformer Explainer de Cho et al.
proporcionaron bases técnicas fundamentales al utilizar archivos ONNX para representar el modelo de forma eficiente, permitiendo que esta información sea procesada y renderizada dinámicamente en interfaces web. Además, iniciativas como 3D LLM de Brendan Bycroft impulsaron la exploración tridimensional y más inmersiva de las representaciones internas de modelos de lenguaje, inspirando funcionalidades innovadoras en la visualización actual. Los beneficios de analizar los pesos de atención van más allá del simple aspecto visual. Para investigadores y desarrolladores, entender estas matrices ofrece pistas sobre el comportamiento del modelo, posibles sesgos, o áreas donde puede ser susceptible a errores. Esto abre puertas para mejorar la arquitectura, afinar modelos, o desarrollar mecanismos de interpretabilidad responsables y transparentes, elementos esenciales para la creciente adopción de la inteligencia artificial en aplicaciones críticas.
En el ámbito educativo, esta herramienta representa un recurso valioso para estudiantes y profesionales que buscan comprender en detalle cómo modelos complejos como GPT-2 manejan el lenguaje. La posibilidad de interactuar con datos reales extraídos de modelos entrenados acerca la teoría a la práctica, facilitando una comprensión más tangible y aplicada de conceptos abstractos como la atención y la autoatención. Finalmente, esta representación visual es una celebración del avance tecnológico y la creatividad humana. El proyecto ha sido dedicado a personas cercanas que inspiran y motivan, demostrando cómo la pasión y el compromiso personal pueden fusionarse con la innovación tecnológica para ofrecer soluciones que no solo son funcionales, sino también profundamente significativas. En resumen, la visualización de los pesos de atención en GPT-2 constituye una herramienta esencial para descifrar el funcionamiento interno de uno de los modelos de lenguaje más influyentes, permitiendo tanto a expertos como a aficionados descubrir las complejidades y bellezas de los procesos que subyacen a la generación automática de texto natural.
Este acercamiento interdisciplinario entre ingeniería, diseño e interacción humana establece un nuevo estándar para el análisis e interpretación de inteligencia artificial moderna.








